node is single-threaded, how can our node project utilize the resources of a multi-core CPU while improving the stability of the node service?
This article is divided into 4 main parts to explain.
- node’s single thread
- node multi-process creation
- multi-process communication
- multi-process maintenance
1. single thread of node
A process is a dynamic execution of a program with certain independent functions on a dataset, an independent unit of resource allocation and scheduling by the operating system, and a vehicle for the operation of an application.
A thread is a single sequential control flow in program execution, which exists within a process, and is a smaller basic unit than a process that can run independently.
In the early days of single-core CPU systems, the concept of process was introduced to realize multitasking. Different programs ran in processes with isolated data and instructions, and were executed through time-slice rotation scheduling.
The system overhead is high because of the need to save relevant hardware site, process control blocks and other information during process switching. In order to further improve the system throughput and make fuller use of CPU resources while the same process is executing, the concept of threads is introduced. Threads are the smallest unit of OS scheduling execution, they are attached to the process, share the resources in the same process, and basically do not own or only own a small amount of system resources, so the switching overhead is very small.
Node is built on top of the V8 engine, which dictates a mechanism similar to that of a browser.
A node process can only utilize one core, and node can only run in a single thread. Strictly speaking, node is not really a single-threaded architecture, i.e., there can be multiple threads within a process, because node itself has certain i/o threads that exist, and these I/O threads are handled by the underlying libuv, but these threads are done transparently to the node developer, and are only used in C++ extensions. Here we will shield the underlying details and focus exclusively on what we want to focus on.
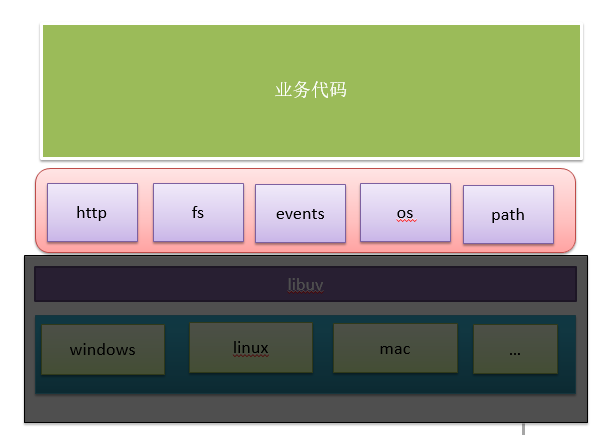
The advantages of single-threaded are: single program state, no locking, thread synchronization problems in the absence of multiple threads, and the operating system can also improve CPU usage very well when scheduling because of less context switching. However, single-core single-threaded has corresponding disadvantages.
- the whole program hangs when this thread hangs.
- Inability to fully utilize multi-core resources.
2. node multi-process creation
node provides the child_process module, which provides several methods to create child processes.
|
|
All four methods can create subprocesses, but the way they are used is slightly different. Let’s take the example of creating a subprocess to calculate the Fibonacci series numbers, with the file of the subprocess (worker.js).
|
|
How do you call these methods in master.js to create a child process?
| Commands | Use | Explanation |
|---|---|---|
| spawn | spawn(’node’, [‘worker.js’]) | start a word process to execute a command |
| exec | exec(’node worker.js’, (err, stdout, stderr) => {}) | start a subprocess to execute the command, with callbacks |
| execFile | exexexFile(‘worker.js’) | start a subprocess to execute the executable(add # to the header! /usr/bin/env node) |
| fork | fork(‘worker.js’) | is similar to spawn, but here you only need to customize the js file module |
Take the fork command as an example.
3. Communication between multiple processes
The communication between processes in node is mainly between master and slave (child) processes. The child processes cannot communicate with each other directly, and if they want to communicate with each other, they have to forward the information through the master process.
The master and child processes communicate with each other through IPC (Inter Process Communication), which is also implemented by the underlying libuv according to different operating systems.
Let’s take the example of calculating the Fibonacci sequence, where we use the number of cpu processes minus one to do the calculation and the remaining one to output the result. This requires the sub-process responsible for the calculation to pass the result to the main process, and then let the main process pass it to the output to perform the output. Here we need 3 files.
- master.js: to create the subprocesses and the communication between the subprocesses.
- fib.js: to calculate the Fibonacci sequence.
- log.js: to output the result of the Fibonacci series calculation.
Main process.
|
|
Calculation process.
|
|
Output process.
When we run master, we can see the results of the individual child process calculations.
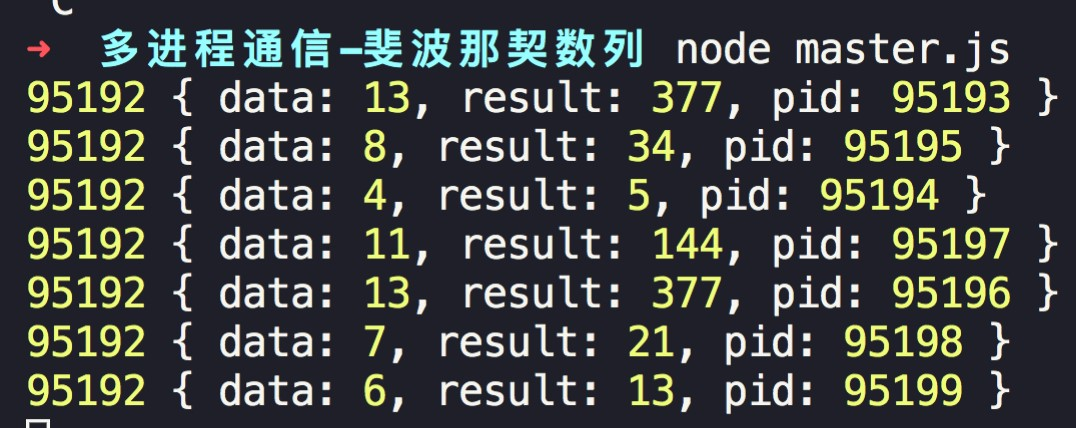
The first number indicates the number of the current output sub-process, followed by the data calculated in each sub-process.
Similarly, we can use a similar idea when logging the http service, where multiple subprocesses take on the http service and the remaining subprocesses do the logging and other operations.
When I want to create a server with subprocesses, I use the above Fibonacci sequence-like idea and change fib.js to httpServer.js.
The result is an error, indicating that port 8080 is already occupied.
|
|
This is because: there is a file descriptor for the socket socket listening port on the TCP side, and each process has a different file descriptor, which will fail when listening to the same port.
There are two solutions: the first and simplest is that each child process uses a different port, and the master process gives the cyclic identifier to the child process, which uses the relevant port by this identifier (e.g. the identifier passed in from 8080+ as the port number of the current process).
The second option is to do port listening in the master process and then pass the listening socket to the child process.
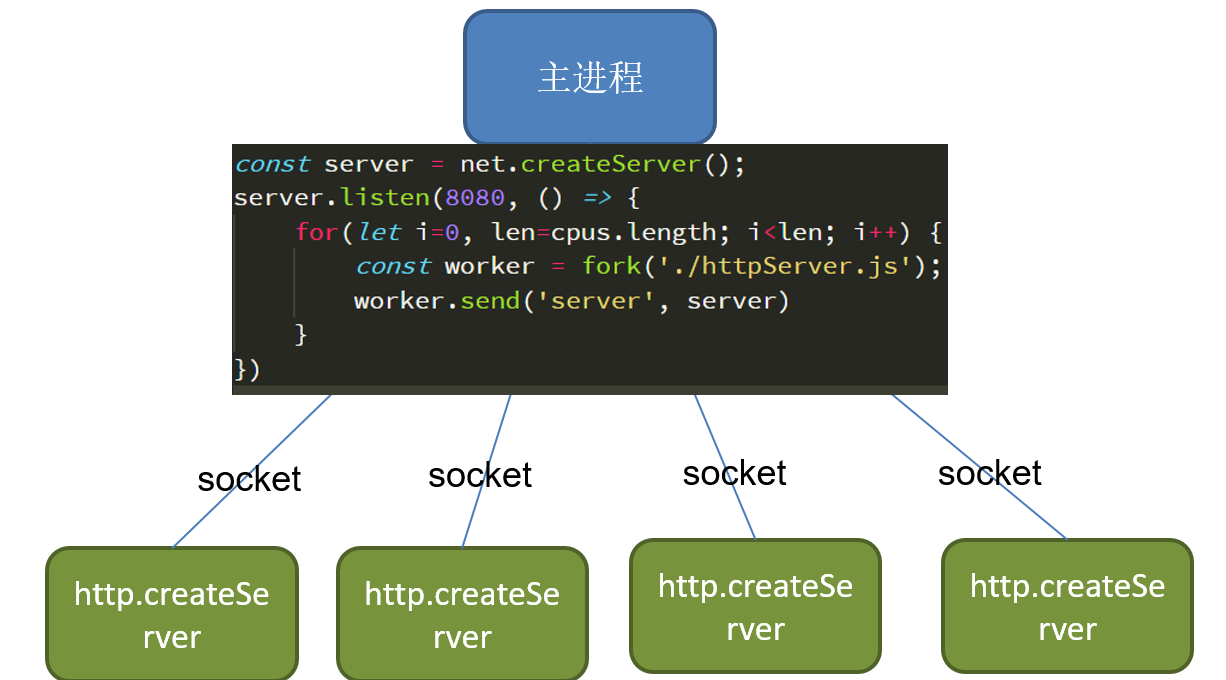
Main process.
|
|
httpServer1.js:
|
|
httpServer2.js:
|
|
Our 2 servers, one outputting random numbers and the other outputting the current timestamp, can be found to be functioning properly. Also, because these process services are preemptive, whichever process grabs the connection will handle the request.
What we should also know is that.
The memory data between each process is not interoperable, so if we cache data in one process using a variable, another process cannot read it.
4. Multi-process guarding
The multiprocess we created in part 3 solves the problem of multi-core CPU utilization, and then we have to solve the problem of process stability.
Each child process will trigger the exit event when it exits, so we can listen to the exit event to know that a process has exited, and then we can create a new process to replace it.
|
|
cluster module
For the multi-process daemon part, node has also introduced the cluster module to solve the multi-core CPU utilization problem. The cluster also provides exit events to listen to the exit of child processes.
A classic example.
|
|
5. Summary
Although node is single-threaded, we can make full use of multi-core CPU resources by creating multiple sub-processes, and we can improve the overall stability of our project by listening to some events of the process to sense the running status of each process.