Kubernetes started out by providing only Extender. The Extender scheduler plugin, which enables non-intrusive extensions by deploying a web service, has several problems.
- The number of Extender extensions is limited: only “Filter” and “Prioritize” extensions are available during scheduling. The “Preempt” extension is called after running the default preemption mechanism. “Extender cannot be called at other points, e.g. not before running the predicate function.
- Performance issues: Each call to an extender involves JSON coding and decoding. Calling a webhook (HTTP request) is also slower than calling a native function.
- The scheduler cannot notify Extender that Pod scheduling has been aborted. For example, if an Extender provides a clustered resource, and the scheduler contacts the Extender and asks it to provide an instance of the resource for the pod being scheduled, and then the scheduler encounters an error while scheduling the pod and decides to abort the scheduling, it will be difficult to communicate the error to the Extender and ask it to withdraw the configuration of the resource.
- Since the current Extender runs as a separate process, it cannot use the scheduler’s cache. Either build their own cache from the API Server or process only the information they receive from the scheduler.
Scheduling Framework The Scheduling Framework is a new set of “plug-in” APIs that allow many scheduling features to be implemented using plug-ins while keeping the scheduler “core” simple and maintainable. Scheduler plugins must be written in Go and compiled with Kubernetes scheduler code, which has a learning cost.
Although Extender is simple, in the long run, try to choose Scheduling Framework. here is a detailed compilation of these 2 extensions based on the official design documentation.
Extender
Scheduler Extender is actually an additional web service that extends the default scheduler to adjust scheduling decisions at different stages by registering an external webhook. Filter method, Prioritize method, Bind method implemented according to your needs.
Advantages.
- the functionality of the existing scheduler can be extended without recompiling the binaries.
- The extender can be written in any language.
- Once implemented, it can be used to extend different versions of kube-scheduler.
Design
When scheduling pods, Extender allows external processes to filter nodes and prioritize them. Two separate http/https calls are made to Extender, the “filter” and “prioritize” operations. If the pod cannot be scheduled, the scheduler will try to preempt lower priority pods from the node and send them to Extender’s “preempt” interface (if configured) Extender can return a subset of nodes and new evictees to the scheduler. In addition, Extender can optionally bind the pod to the apiserver by implementing a “bind” operation.
Configuration
To use Extender, a scheduler configuration file must be created. Configure whether the access method is http or https and the timeout configuration, etc.
|
|
Example configuration file.
|
|
Multiple Extenders can be configured and the scheduler will call them in order.
Interface
The Extender Web module can implement the following 4 interfaces as needed, each with a corresponding request and response.
Filter
Request
|
|
Response
|
|
Prioritize
Request
Same as Filter Request
Response
|
|
Bind
Request
|
|
Response
Preempt
Request
|
|
Response
Scheduling Framework
The Scheduling Framework is a set of new “plug-in” APIs added to the existing Kubernetes scheduler that allow many scheduling features to be implemented as plug-ins and compiled into the scheduler, while keeping the scheduling “core” simple and maintainable. maintainable.
As more and more features are added to the Kubernetes scheduler. These new features continue to make the code larger and the logic more complex. This makes the scheduler harder to maintain, bugs harder to find and fix, and those running custom schedulers have difficulty catching up and integrating new changes. While the current Kubernetes scheduler provides webhooks to extend its functionality. However, these are limited in several ways.
- The number of Extender extensions is limited: only “Filter” and “Prioritize” extensions are available during scheduling. The “Preempt” extension is called after running the default preemption mechanism. The “Bind” extension is used to bind Pods, and the Bind extension can only bind one extension, which replaces the scheduler’s bind operation.
- Performance issues: Each call to an extender involves JSON coding and decoding. Calling a webhook (HTTP request) is also slower than calling a native function.
- The scheduler cannot notify Extender that Pod scheduling has been aborted. For example, if an Extender provides a clustered resource and the scheduler contacts the Extender and asks it to provide an instance of the resource for the pod being scheduled, and then the scheduler encounters an error while scheduling the pod and decides to abort the scheduling, it will be difficult to communicate the error to the Extender and ask it to withdraw the configuration of the resource.
- Since the current Extender is running as a separate process, it cannot use the scheduler’s cache. Either build their own cache from the API Server or process only the information they receive from the scheduler.
The above limitations prevent building a high-performance and more functional scheduler. Ideally, it would be desirable to have an extension mechanism that is fast enough to allow conversion of existing functions to plugins, such as predicate and priority functions. Such plugins would be compiled into the scheduler binaries. In addition, authors of custom schedulers can compile custom schedulers using (unmodified) scheduler code and their own plugins.
Design Goals
- Make the scheduler more extensible.
- Make the scheduler core simpler by moving some of the scheduler core functionality to plugins.
- To propose extension points in the framework.
- propose a mechanism to receive plug-in results and continue or abort depending on the results received.
- propose a mechanism to handle errors and communicate with plug-ins.
The scheduling framework defines new extension points and Go APIs in the Kubernetes scheduler for use by “plugins”. Plugins add scheduling behavior to the scheduler and include it at compile time. The scheduler’s ComponentConfig will allow plugins to be enabled, disabled, and reordered. Custom schedulers can write their plugins “out-of-tree” and compile a scheduler binary containing their own plugins.
Scheduling cycles and binding cycles
Each dispatch of a pod is divided into two phases: the dispatch cycle and the binding cycle. The scheduling cycle selects a node for the pod, and the binding cycle applies that scheduling result to the cluster. The scheduling cycle and the binding cycle together are called the “scheduling context”. Scheduling cycles run serially, while binding cycles may run concurrently.
If a pod is determined to be unschedulable or there is an internal error, either the scheduling cycle or the binding cycle can be aborted. The pod will return to the queue and retry. If the binding cycle is aborted, it will trigger the Unreserve method in the Reserve plug-in.
Extension Points
The following diagram shows the dispatching context of Pod and the extension points exposed by the dispatching framework. In this diagram, “Filter” is equivalent to Extender’s “Predicate” and “Scoring” is equivalent to “Priority”. Plugins are registered to be called at one or more of these extension points. In the following sections, we describe each extension point in the same order in which they are called.
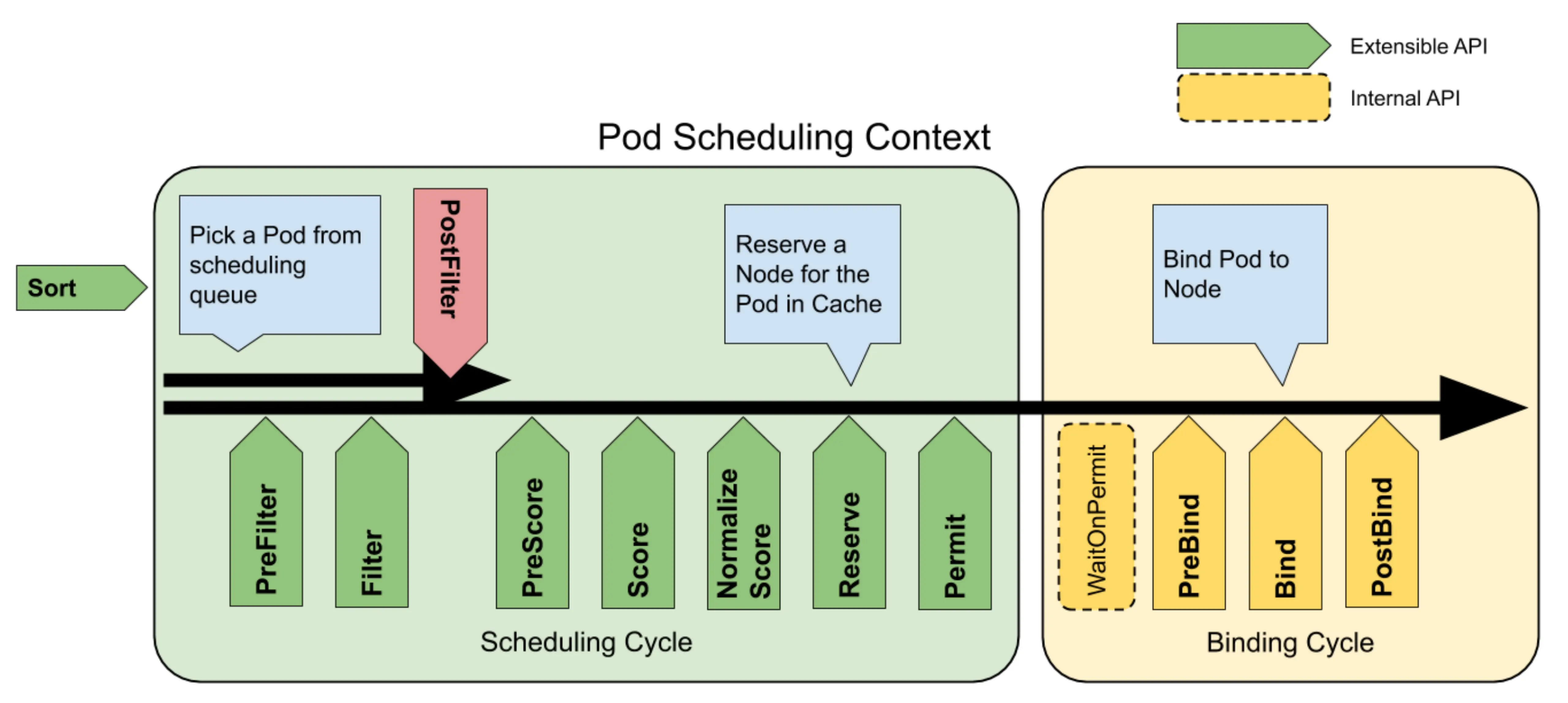
Queue sort
These plugins are used to sort the pods in the scheduling queue. They will essentially provide less(pod1, pod2) functionality. Only one queue sort plugin can be enabled at a time.
PreFilter
PreFilter is called once in each scheduling cycle. These plugins are used to preprocess information about pods or to check clusters, certain conditions that pods must meet. A pre-filter plugin should implement a PreFilter interface, and if the pre-filter returns an error, the scheduling cycle is aborted.
The Pre-filter plugin may implement the optional PreFilterExtensions interface, which defines AddPod and RemovePod methods to incrementally modify its pre-processing information. The framework guarantees that these functions will only be called after the PreFilter, on the cloned CycleState, and possibly multiple times before calling the Filter on a particular node.
Filter
Used to filter out nodes that are unable to run Pods. For each node, the scheduler will invoke the filter plugins in the configured order. If any filter plugin marks the node as infeasible, the remaining plugins will not be called for that node. Nodes may be evaluated concurrently, and filter may be called multiple times in the same scheduling cycle.
PostFilter
Called after the Filter phase, and only if no feasible nodes are found for the pod. Plugins are invoked in the order they are configured. If any PostFilter plugin marks the node as dispatchable, the rest of the plugins are not called. A typical PostFilter implementation is preemption, which attempts to make a Pod dispatchable by preempting other Pods.
PreScore
Information extension point for performing PreScore. Plugins will be invoked using the list of nodes in the filtering phase Plugins can use this data to update internal state or generate logs/metrics.
Scoring
The plugin here has two phases.
The first stage is called “score” and is used to rank the nodes that have passed the filtering stage. The scheduler will call the Score function of each scoring plugin for each node.
The second phase is “normalize scoring”, which is used to modify the score before the scheduler calculates the final ranking of the nodes, and each scoring plugin receives the score given to all nodes by the same plugin during the “normalize scoring” phase. Each scoring plugin receives scores from the same plugin for all nodes in the “normalize scoring” phase. NormalizeScore is optional and can be provided by implementing the ScoreExtensions interface.
The output of the score plugin must be an integer in the range [MinNodeScore, MaxNodeScore]. If it is not, the scheduling cycle is aborted. This is the output after running the optional NormalizeScore function of the plugin. If NormalizeScore is not provided, the output of Score must be within this range. After the optional NormalizeScore, the scheduler will combine the node scores from all plugins based on the configured plugin weights.
For example, suppose the plugin BlinkingLightScorer ranks nodes based on the number of blinking lights they have.
However, the maximum count of blinking lights may be small compared to the MaxNodeScore. To solve this problem, BlinkingLightScorer should also implement NormalizeScore.
|
|
If Score or NormalizeScore returns an error, the scheduling cycle is aborted.
Reserve
Plugins that implement the Reserve extension have two approaches, Reserve and Unreserve, which support two information scheduling phases called Reserve and Unreserve, respectively. plugins that maintain runtime state (aka “stateful plugins”) should use these phases to notify the scheduler when resources on a node are being reserved and unreserved for a given Pod. ) should use these phases to notify the scheduler when resources on a node are being Reserve and Unreserve for a given Pod.
The Reserve phase occurs before the scheduler actually binds the Pod to its specified node. It exists to prevent contention conditions while the scheduler waits for a successful binding. The Reserve method of each Reserve plug-in may succeed or fail; if a Reserve method call fails, subsequent plug-ins are not executed and the Reserve phase is considered to have failed. If the Reserve methods of all plug-ins succeed, the Reserve phase is considered successful and the remaining scheduling cycles and binding cycles are executed.
If the Reserve phase or subsequent phases fail, the Unreserve phase is triggered. When this happens, the Unreserve methods of all Reserve plugins are executed in the reverse order of the Reserve method calls. This phase exists to clean up the state associated with the Reserve Pod.
Note: The implementation of the Unreserve method in the Reserve plugin must be idempotent and cannot fail.
Permit
These plugins are used to block or delay the binding of Pods. The Permit plugin can do one of three things.
-
approve Approve
Once all Permit plugins have approved a pod, it will be sent for binding.
-
deny Deny
If any Permit plugin denies a pod, it will be returned to the scheduling queue. This will trigger the Unreserve method in the Reserve plugin.
-
wait wait (timeout)
If the permit plugin returns “wait”, the pod will remain in the Permit phase until the plugin approves it. If it times out, wait becomes deny and the pod returns to the scheduling queue, triggering the unreserve method during the Reserve phase.
The Permit plugin is executed as the last step of the scheduling cycle, but the wait in the Permit phase occurs at the beginning of the binding cycle, before the PreBind plugin is executed.
Approve pod bindings
While any plugin can receive a list of reserved Pods from the cache and approve them (see FrameworkHandle), we expect only permission plugins to approve bindings to reserved Pods that are in the “waiting” state. Once a Pod is approved, it is sent to the pre-binding phase.
PreBind
Used to perform any work required before binding a pod. For example, a prebind plugin might provide a network volume and mount it on the target node before allowing the pod to run.
If any PreBind plugin returns an error, the pod will be rejected and returned to the scheduling queue.
Bind
Used to bind a pod to a node. Bind plugins are not invoked until all PreBind plugins have completed. Each bind plugin is called in the configured order. Bind plugins can choose whether to process a given Pod. if a bind plugin chooses to process a Pod, the remaining bind plugins are skipped.
PostBind
This is an information extension point. the PostBind plugin is called after a Pod has been successfully bound. This is the end of the binding cycle and can be used to clean up the associated resources.
Plugin API
The Plugin API has two steps. 1. register and configure, and 2. use the extension point interface. The extension point interface has the following forms.
CycleState
Most plugin functions (except for the Queue Sort plugin) will be called with the CycleState parameter. cycleState represents the current scheduling context.
CycleState will provide an API for accessing data scoped to the current scheduling context. Because binding loops may execute concurrently, plugins can use CycleState to ensure they are processing the correct requests.
CycleState also provides an API similar to context.WithValue that can be used to pass data between plugins with different extension points. Multiple plugins can share state or communicate through this mechanism. This state is only retained for the duration of a single dispatch context. Note that plugins are assumed to be trusted. The scheduler does not prevent a plug-in from accessing or modifying the state of another plug-in.
Warning: Data referenced via CycleState is invalid after the scheduling context ends, and plugins should not hold a reference to this data for longer than necessary.
FrameworkHandle
CycleState provides APIs related to individual scheduling contexts, while FrameworkHandle provides APIs related to the plugin lifecycle. this is how the plugin gets the client (kubernetes.Interface) and SharedInformerFactory, or from the scheduler’s cluster state cache of the scheduler. The handle will also provide the API to list and approve/reject waiting pods.
Warning: FrameworkHandle provides access to the kubernetes API Server and the scheduler’s internal cache. However, the two are not guaranteed to be synchronized, so extra care should be taken when writing plugins that use data from both of them.
Providing plug-in access to the API Server is necessary to implement useful features, especially if those features use object types that are not normally considered by the scheduler. Providing a SharedInformerFactory allows plugins to share caches securely.
Plugin Registration
Each plugin must define a constructor and add it to the hard-coded registry.
Plugins can also be added to a registry object and injected into the scheduler.
Plugin Lifecycle
Initialization
Plugin initialization has two steps. First, the plugin is registered. Second, the scheduler uses its configuration to determine which plugins to instantiate. If a plugin is registered with multiple extensions, it will only be instantiated once.
When a plugin is instantiated, it is passed config args and a FrameworkHandle.
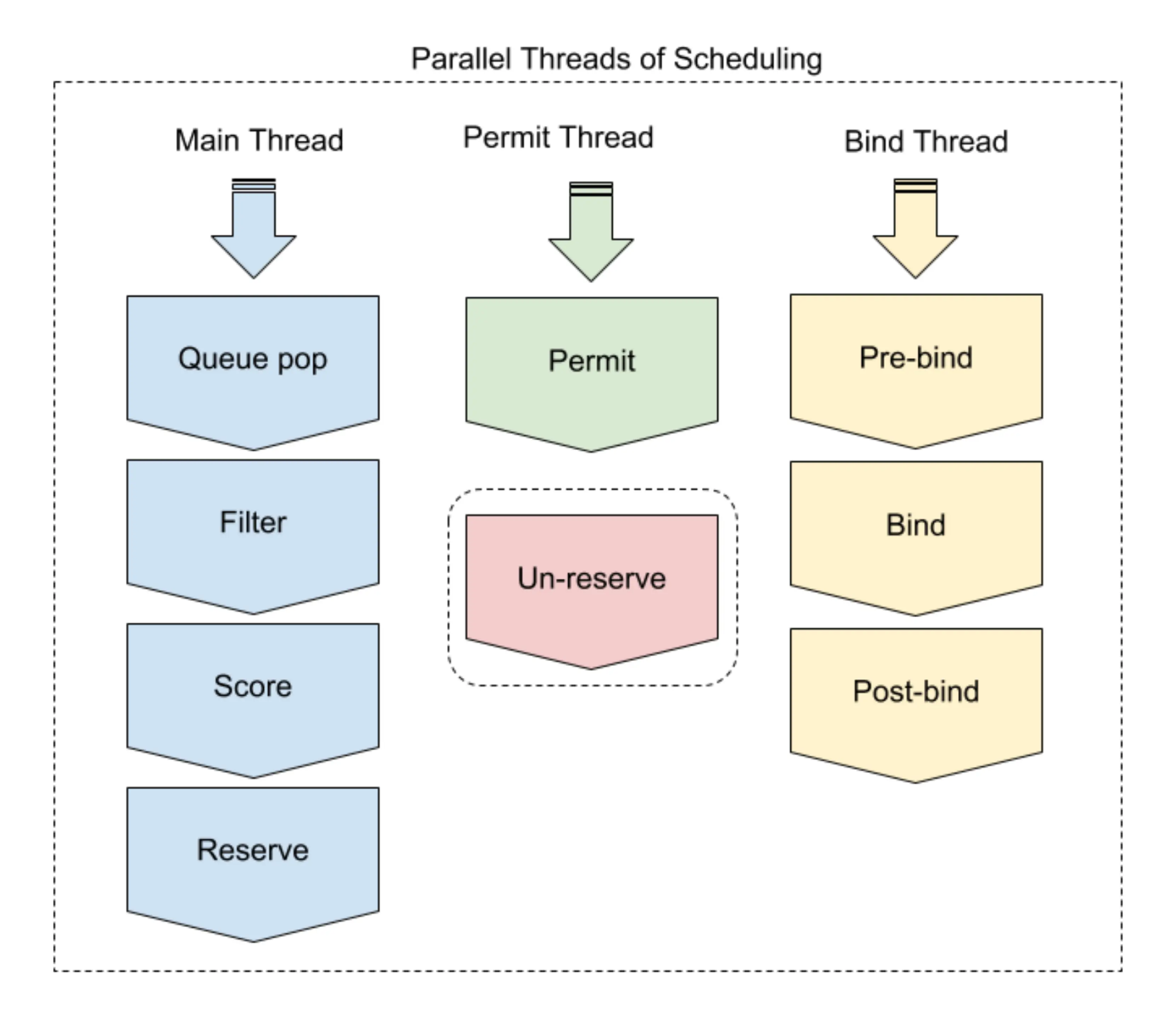
Concurrency
Plugin writers should consider two types of concurrency. When evaluating multiple nodes, a plugin may be called multiple times at the same time, and a plugin may be called simultaneously from different scheduling contexts.
Note: In a scheduling context, each extension point is evaluated serially.
In the main thread of the scheduler, only one scheduling cycle is processed at a time. Any extensions up to and including permit will be completed before the start of the next scheduling cycle (the queue sorting extension is a special case. It is not part of the scheduling context and can be called for many pod pairs simultaneously). After the permit extension point, the binding cycle is executed asynchronously. This means that the plugin may be invoked by two different scheduling contexts at the same time. Stateful plugins should be careful to handle these cases.
Finally, the Unreserve method in the Reserve plugin can be called from either the main thread or the bind thread, depending on how the pod is rejected.
Configuring Plugins
The scheduler’s component configuration will allow plugins to be enabled, disabled, or otherwise configured. Plugin configuration is divided into two parts.
- a list of enabled plugins for each extension point (and the order in which they should be run). If one of these lists is omitted, the default list will be used.
- Each plugin has an optional set of custom parameters. Omitting a plugin’s parameters is equivalent to using that plugin’s default configuration.
Plugin configurations are organized by extension points. Each list must contain plugins that register multiple points.
|
|
Example:
|
|
Enable/Disable
The configuration uniquely enables the list of plugins for a given extension point. If an extension omits the configuration, the extension uses the default set of plugins.
Change Evaluation Order
The order of plugin execution is determined by the order in which the plugins appear in the configuration. Plugins that register multiple extension points can have a different order at each extension point.
Optional Args
Plugins can receive parameters with arbitrary structure from their configuration. Because a plugin may appear in multiple extensions, the configuration is located in a separate list in PluginConfig.
Example.
|
|
Backward Compatibility
The current KubeSchedulerConfiguration type has apiVersion:kubescheduler.config.k8s.io/v1alpha1. This new configuration format is v1alpha2 or v1beta1. When newer versions of the scheduler parse v1alpha1, the policy section will be used to construct the equivalent plugin configuration.
Interaction with Cluster Autoscaler
Cluster Autoscaler must run Filter plugins instead of predicates. This can be done by creating a Framework instance and calling RunFilterPlugins.