I. Preface
In this article, let’s learn the SBE(Simple Binary Encoding) transfer protocol, which is the same as protobuf, which is a binary transport protocol with higher performance than protobuf, inspired by fast binary variant of FIX fix-simple-binary-encoding), and was originally intended for use in financial-grade, low-latency trading systems. SBE is also widely used as a data transfer medium in the open source software Aeron.
II. Design Principles
2.1 Copy-Free
Network and storage systems usually need to encode and decode data buffers when processing data. the principle of Copy-Free is not to use any intermediate buffers to encode and decode data. If intermediate buffers were used, performance loss would occur due to multiple copies of the data.
SBE uses direct encoding and decoding of the underlying buffer, which has the limitation that it does not support direct sending of data longer than the transmission buffer, in which case segmentation and data reassembly are required.
2.2 Native Type Mapping
Copy-Free mode gets a performance boost by encoding data directly into the native type in the underlying buffer. For example, a 64-bit integer can be encoded directly into the underlying buffer as a single x86_64 MOV instruction. If the byte order of the data (big end/small end) does not match the CPU’s, then the data can be swapped in registers using the x86 BSWAP instruction before being written to the underlying buffer.
2.3 Allocation-Free
The creation of objects leads to a reduction in CPU cache, which reduces efficiency. The objects need to be managed and released later. For Java, this process is done by the garbage collector, which reclaims memory by triggering STW (Stop The World) of varying duration (except for the new generation C4 garbage collector.) C++ is better, but introduces a locking mechanism when memory is released back to the memory pool, which also incurs performance overhead. The SBE codec uses the flyweight model to avoid allocation problems. flyweight windows encode and decode data directly on the underlying buffer, selecting the appropriate type of flyweigh via the templateId field in the message header. if the fields in the message need to be kept outside the island processing flow, they need to be copied out separately .
|
|
2.4 Streaming Access
Modern memory subsystems have become more and more complex, and the algorithmic model of access memory largely determines performance and consistency. The best performance and most consistent latency can be achieved by using a stream-based approach to access memory addresses in ascending mode. The SBE codec encodes and decodes data based on the forward progression of positions in the underlying buffer. While some backtracking is possible, this operation is highly discouraged from a performance and latency perspective.
2.5 Word Aligned Access
Many CPU architectures exhibit significant performance problems when we do not access data at the boundary of a word. A word should start at an address that is a multiple of its size in bytes, e.g. a 64-bit integer can only start at an address whose byte address is divisible by 8, a 32-bit integer can only start at an address whose byte address is divisible by 4, and so on.
The SBE mode supports the concept of defining an offset for the start of a field in the data. It assumes that the data is encapsulated in protocol frames with 8-byte size boundaries. To achieve compactness and efficiency, message fields should be ordered by their type and size in descending order.
|
|
2.6 Backwards Compatibility
The message format must be backwards compatible, i.e. the older system should be able to read the newer version of the same message, and vice versa.
An extension mechanism is designed in SBE to allow the introduction of new optional fields in the data, which can be used by the new system and ignored by the old system until it is upgraded. If required fields or basic structures need to be changed, the new message type must be used, as this is no longer a semantic extension of the existing data type.
III. Tutorials for use
3.1 XML Grammar
First we have to learn how to define an SBE transport protocol, which differs from protobuf in that it uses a custom format, SBE uses XML format. We have to refer to the official documentation, so we won’t talk about it here.
3.2 Maven Plugins
After we have prepared the XML file of SBE, the next step is to generate the corresponding codec code according to the file, the official recommendation is to use sbe-all-${SBE_LIB_VERSION}.jar toolkit, and then call java -jar to generate the code, the specific process and detailed parameters can be found in the official document.
Here I introduce another way to generate code through the Maven plugin, which is much easier to use. First assume that I store the XML file in the resources directory of the project, as shown in the following figure.
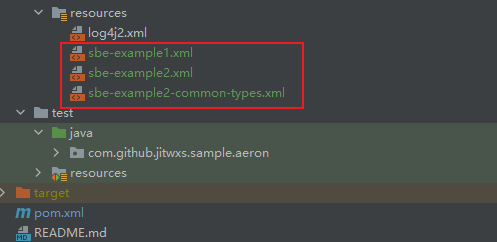
Then add the plugin in Maven
|
|
Then execute the maven clean install command and the automatically generated code will be placed in the target/generated-sources/java directory.
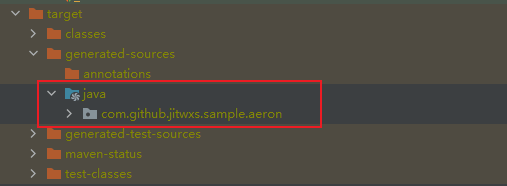
Note: If you need to adjust the XML file location, or the location of the generated file, or the generation parameters, please adjust the specific parameters in the plugin above by yourself.
3.3 Codec
The next step is to use the generated codec class for data transmission, the difficulty is the use of its API, here I give two examples that I used when I was studying, you can debug locally against the document and understand it quickly.
The first example is from the Aerona Cookbook.
- Example description: https://aeroncookbook.com/simple-binary-encoding/basic-sample/
- Corresponding source code: com.github.jitwxs.sample.aeron.sbe1.SbeExample1Test
The second example is from SBE GitHub:
- Example description: https://github.com/real-logic/simple-binary-encoding/wiki/Java-Users-Guide
- Corresponding source code: com.github.jitwxs.sample.aeron.sbe2.ExampleUsingGeneratedStub