Previously, Yu Zhao from Google submitted a Patch to the Linux kernel that modified the page swap algorithm in the kernel memory management module, proposing a multi-level LRU. This article takes you through the advantages of the page swap algorithm and multi-level LRU.

What are pages and page replacement
We know that memory paging mechanisms are used on almost all modern operating systems and processors. In some embedded operating systems and in special cases where processor resources are tight and there is no need to consider inter-process safety, or even the concept of threads, memory paging is not necessary. Memory paging is proposed for virtual memory mechanisms, where each process has its own separate address space for inter-process isolation on most modern operating systems, which is called virtual memory. Virtual memory needs to have a mapping to physical memory, but the problem is that this mapping table takes up memory space, especially on 64-bit processors where the address space to be mapped is so large that if the addresses were mapped one to one, the mapping table would be larger than the physical memory. This requires a paging mapping of the memory into pages of a certain size, e.g. 4KB, which correspond to the 4KB pages in physical memory, which is the memory paging mechanism. However, the page table is still very large, and modern architectures generally use multi-level page tables to significantly reduce the space occupied by the page table, such as the four-level page table in Linux.
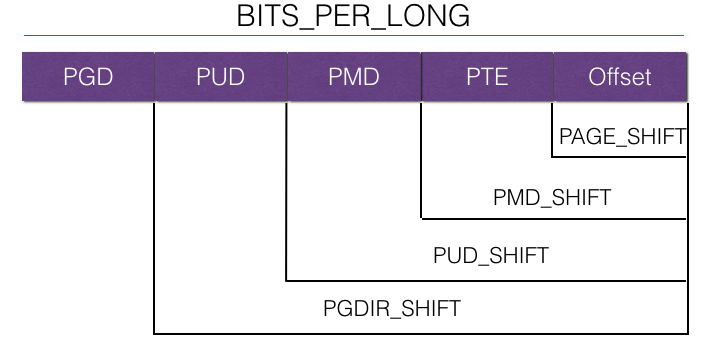
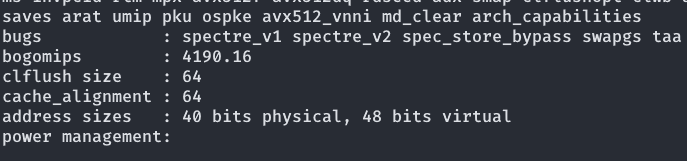
Linux even uses a five-level page table on the latest Intel Xeon processors, so I won’t go into the details of processor-specific support. It is worth noting that page tables require hardware support, i.e. support from the CPU’s memory management unit (MMU) . Here is the MMU support for an Intel Xeon Gold 6230, you can see that 40 bits physical means that its MMU supports 40 bits of hardware addressing, and 48 bits physical is the size of the virtual address space supported by the current Linux four-level page table.
And what is page replacement?
Page replacement also comes from a feature that almost all modern operating systems have - the swap mechanism. When physical memory is nearly full, the operating system moves some of the less frequently used pages to disk to make room for more frequently used pages in order to keep the whole system available. Of course, this comes at the cost of reduced performance, and the mechanism is not foolproof, as the system can still become almost unusable when actively used memory is also borrowed near the size of physical memory, but at least this mechanism gives the system a chance to recover on its own, rather than having to have some processes killed by the OOM Killer. This swap mechanism obviously requires a good algorithm to determine which part of the page is “stale”, which brings us to the topic of this article - Page Replacement Algorithm.
Page Replacement Algorithms
As operating systems have evolved over the last 50 years and page replacement algorithms have improved, let’s take a look at some of the page replacement algorithms that have emerged.
- Optimal algorithms: Nice try, even the definition of “optimal” depends on the actual scenario.
- NRU (recently unused) algorithm: A simple algorithm that maintains a chain table, eliminating the end pages each time, and moving the pages to the head of the table on each read. It is an acceptable algorithm, with easy implementation and low performance loss.
- FIFO: Maintains a queue and clears the pages at the head of the queue directly each time. Almost no performance overhead, but does not work well.
- Second Chance FIFO: Maintains a cyclic queue that cleans up pages with an access flag bit of 0 each time, and sets the flag position to 1 after each access, so that as long as there is an access to a page in the cycle, it is saved from being cleaned up unless all pages are 1. Due to the high number of memory operations using cyclic queues, one of the following algorithms is generally used.
- Clock Algorithm: Pointer and circular chain/queue implement SCFIFO, eliminating memory operations, and is the more commonly used algorithm, which works better and is a big improvement over NRU.
- LRU (Least Recently Used) algorithm: Good approximation for optimal algorithms in most cases, excellent results, but more difficult to implement, current algorithms either have high time complexity or high space complexity. Hardware support is also required most of the time.
- NFU algorithm: LRU simulated by software, using a frequency Freq counted by the system clock interrupt handler, works well but has some performance overhead and does not implement “nearest”.
- Aging algorithm: Adds frequency aging to the NFU and implements “nearest”, with the older the usage being weighted less.
The current page replacement algorithm used by the Linux kernel is the two-stage software LRU, which is divided into two chains of active and inactive types and implements the software LRU (NFU) algorithm, which is referred to as LRU in the following as hardware-based LRU is not available in today’s architecture.
The problem of two-level LRU
TL;DR
The current algorithm has too much CPU overhead and often makes bad decisions.
Granularity
The two classifications Active/Inactive is really a rather coarse granularity in today’s hardware environment. Mind you, it is not uncommon, if not common, in the Linux-ruled server world for memory to be on T. Intel’s recent rollout of Aeon memory in recent years has placed even higher demands on memory scheduling. This active/inactive classification is not a good one. Contexts like file access, where there are often periodic memory operations, and where pages move back and forth between the two tables, do not give a good indication of whether the page is active or not. And many code segments of executable files that are being executed are often removed simply because they have not been used for a fairly short period of time. This causes a delay in the response of the interactive process on Android and ChromeOS.
Performance issues with inverted page table scans
Since the LRU algorithm needs to periodically update the page access counter based on an inverted page table (rmap), however, the rmap has a rather complex data structure with poor locality, resulting in poor CPU cache hit rates when scanning the rmap. The cache hit rate of modern CPUs has a huge impact on execution speed, and a low cache hit rate can reduce CPU execution speed to 10% or less of its peak.
Multigenerational LRU
Yu Zhao’s recent Patch submission proposes the Multigenerational LRU algorithm, which aims to solve the problem of the two-level LRU now used by the kernel. This Multigenerational LRU borrows ideas from the ageing algorithm, dividing the LRU table into a number of Generations according to page generation (allocation) time. The LRU page sweep uses an incremental scan of the page table based on pages accessed during the cycle, unless the memory distribution accessed during that time is very sparse, and usually the page table has better locality compared to the inverted page table, which in turn improves the CPU’s cache hit ratio.
In the mailing list Yu Zhao illustrates his use of the changed algorithm in several simulation scenarios.
- Android: 18% reduction in low memory kills, and thus 16% reduction in cold starts.
- Borg (Google’s cloud resource orchestration system): active memory usage reduced.
- ChromeOS: inactive pages reduced memory usage by 96% and reduced OOM kills by 59%.
Conclusion
Changes to the Linux kernel’s page replacement algorithm can have a huge impact, even if they are only “minor” tweaks. As Linux is not limited to the usual scenarios, this Patch will need a long period of discussion and testing by various developers before it can finally be merged into the mainline. Although the majority of kernel developers have not yet commented on this, some have been positive and favorable about the new algorithm, so I also think this Patch will eventually make it into the mainline Linux kernel.
read more
- The multi-generational LRU
- [PATCH v1 00/14] Multigenerational LRU
- Long-term SLOs for reclaimed cloud computing resources https://research.google/pubs/pub43017/
- Profiling a warehouse-scale computer https://research.google/pubs/pub44271/
- Evaluation of NUMA-Aware Scheduling in Warehouse-Scale Clusters https://research.google/pubs/pub48329/
- Software-defined far memory in warehouse-scale computers https://research.google/pubs/pub48551/
- Borg: the Next Generation https://research.google/pubs/pub49065/