In this article we discuss the Jump Consistent Hash algorithm, a minimalist and efficient consistent hashing algorithm.
Hashing and Consistent Hashing
A hash function, or hash function, maps the elements of a large definition field into a small finite value field. The elements in the value domain are sometimes called buckets, and the size of the value domain is also referred to as the number of buckets.
MD5 is a common hash function that maps data of any size (the larger definition field) into a 16-byte hash (the smaller finite value field). The simplest hash function is modulo, which maps all integers (the larger definition field) into an integer interval (the smaller finite value field).
Suppose our server has 3 worker processes, serving the user at the same time. These worker processes have the same function and store the user’s state data. So how to decide which worker process serves a user? The easiest way to do this is to take the user ID and assign it to one of the 3 processes.
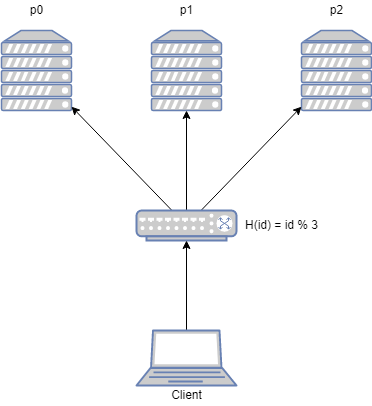
This seems to be working perfectly. As the number of users grows, 3 worker processes are overstretched and the server needs to be scaled up. We need to add one more worker process and have 4 worker processes serving the users at the same time. This is where the problem arises.
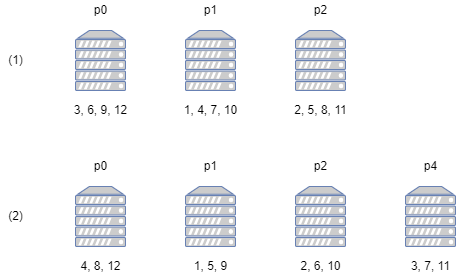
Suppose that before the expansion the server has 12 users online with IDs 1 to 12, then they are distributed among 3 processes as shown in figure (1) above. Now we add a worker process, which requires the users to be distributed among 4 processes, and the hash function should be changed to remainder of 4, which will cause the distribution of clients to change to the case shown in figure (2) above. As mentioned earlier, the server processes store the state data of the users; this expansion will cause the processes of almost all users to change, which will necessitate a large number of data migration operations. If the server has a large number of users online, the cost of the scaling operation becomes unacceptable.
To solve this problem, consistent hash has been proposed. Consistent hash is a special class of hash functions, which is characterized by the fact that when the number of buckets increases from
There are various consistent hashing algorithms. The earliest consistent hashing algorithm was proposed by Karger et al. It associates buckets in a clockwise ring, which is used in the Chord algorithm. In this paper, we present the Jump Consistent Hash algorithm proposed by John Lamping et al. in 2014. It is extremely simple, with only 7 lines of code
At first glance, you may be confused: 2862933555777941757ULL What is it? What is left-right shift to floating point and then divide? Is it really possible to change the mapping of
Probability-based hashing algorithm
As mentioned before, when the number of buckets increases from
Consider the problem from another perspective: Suppose there is an element that maps to bucket 0 when there are 1 buckets. When the number of buckets becomes 2, it has
Based on this idea, we can implement a consistent hashing algorithm. Since the algorithm is based on random probability, in order to make each hash result consistent, we make random seeds of the values of the elements.
This algorithm simulates the case where the number of buckets grows. When the number of buckets is 1, the element must be in bucket 0, so there is an initial b = 0. Each time the number of buckets increases to n, the element has a probability of moving to bucket n - 1, which is the newly added bucket.
Improved algorithm
This algorithm can achieve consistent hashing, but it is a bit slow, with a time complexity of
Notice that elements only move as buckets are added, and each move is necessarily to the newest bucket. That is, if an element moves to bucket
Suppose the target of the next move of the element is bucket
In terms of probability, the probability that the next move of an element is at least
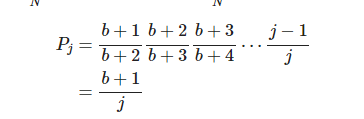
Now let’s reverse the idea. Now that the element moves to

The improved algorithm is as follows:
In the above algorithm, each iteration finds the next position j of the element by using the formula (1), until j >= num_buckets.
Linear congruence generator
To further improve the algorithm, we can use our own implementation of the random function, rather than relying on the system. Here we use the Linear congruential generator. This is an old random number generation algorithm, which is easy to implement. Its random numbers are generated iteratively, and the iterative formula is as follows:
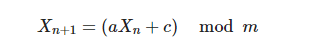
In the Jump consistent hash algorithm, each iteration is like this:
The randomized algorithm has a multiplier of 2862933555777941757, an increment of 1, and a modulus of 0x100000000000000000000. There is no need to take the modulus manually, just let the integer overflow naturally. So each iteration generates a random number in the range 0 to 0xffffffffffffff. Here (key >> 33) + 1 takes the high 31 bits of the random number and adds one more, from 1 to 0x80000000. Then we divide 0x80000000 by it to get the inverse of the probability. The final multiplication by b + 1 is the position of the next move of the element j.
Summary
So there’s a lot of wisdom in a little code. There are a few things that this article hasn’t gone into, such as the rigorous proof of the probability formula; why the multiplier is 2862933555777941757, and why the increment is 1. The random number generation algorithm is a very important topic, and this paper can only go so far. Compared to Karger’s algorithm, the Jump Consistent Hash algorithm is simple, fast, and does not require additional memory. Of course, it has a disadvantage: its value domain can only be the set of non-negative integers less than N. This means that it is not possible to simply remove the intermediate numbers. This means that you cannot simply remove the middle bucket, which would result in a discontinuity in the value domain.