Preface
In order to solve the problem of confusing architecture design that has existed since Android-App development, Google has launched the Jetpack-MVVM series of solutions. As the core of the whole solution - LiveData, with its lifecycle security, memory security and other advantages, and even gradually replace EventBus, RxJava as the trend of Android side state distribution components.
The mall app team has encountered some difficulties in the process of using LiveData in depth, especially in the use of LiveData observers encountered a lot of pitfalls, we put these experiences here to do a summary and share.
How many callbacks can the Observer actually receive
Why do we receive at most 2 notifications
This is a typical case, when debugging a message bus scenario, we usually print some log logs at the receiver of the message to help us locate the problem, however the log printing can sometimes bring some confusion to our problem location, you can see the following example.
We start by defining a minimalist ViewModel:
Then look at our activity code.
|
|
Can you think of what the result of this program run would be? We create a Livedata and then Observe this Livedata 10 times, each time new a different Observer object, and it looks like we have made 10 Observer bindings to a data source. When we modify this data source, we should have 10 notifications. Run it and see the result.
Strange, why do I only get 2 callback notifications when I’ve obviously registered 10 observers? Try a different way of writing it?
Let’s add a part to the Log code like printing the hashCode and look at the result.
|
|
This time the result is normal, in fact for many message bus debugging there are similar problems.
In fact, for the Log system, if he determines that the timestamp is the same, and the content of the Log behind it is also the same, then he will not print the content repeatedly. It is important to pay attention to this detail here, otherwise in many cases, it will affect our judgement of the problem. If we go back to the code where we did not add the hashCode, we will understand it if we look more closely: only the Log prints two items, but the notification is received 10 times, so why print two items? Because your timestamp is the same and the subsequent content is the same.
Strange compilation optimizations
It doesn’t end here, look at the following diagram.
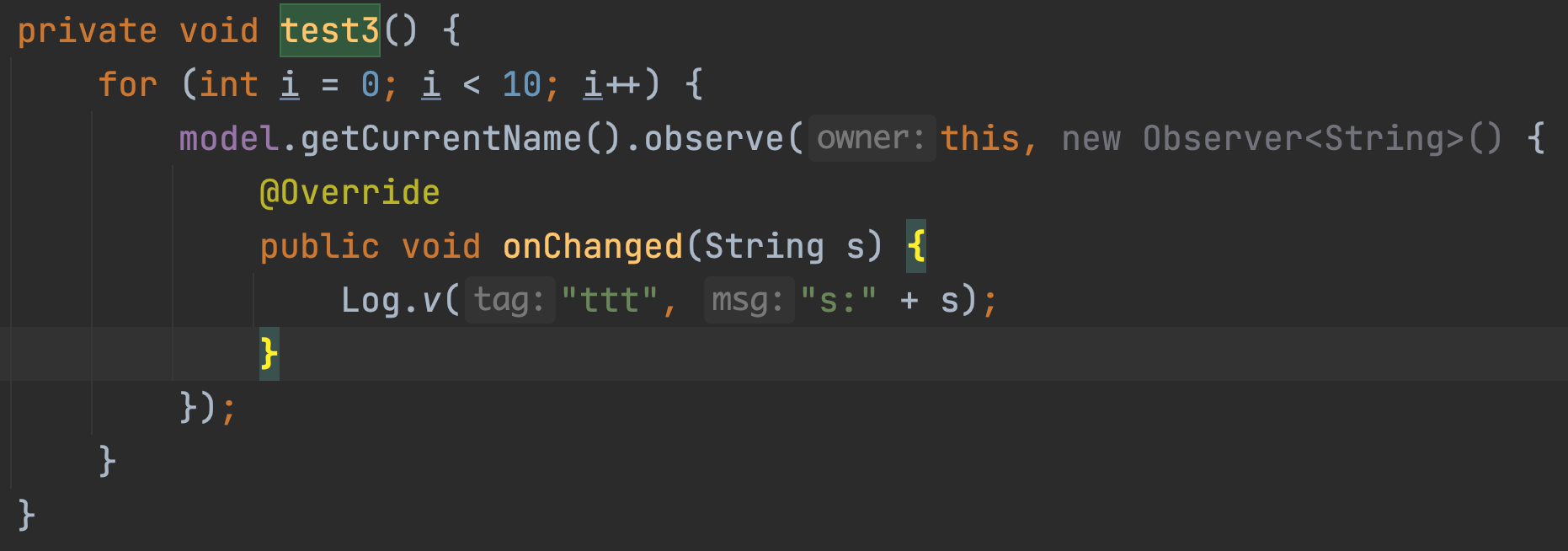
The above code will be greyed out in android studio, I believe many people with code cleanliness will know why, this is the lambda of Java8, ide automatically gives us a hint to let us optimize the writing method, and a mouse click will automatically optimize it, very convenient.

The grey is gone, the code is cleaner, try running it
|
|
Strange, why is there only one log this time? Is it still the Log logging system? I’ll try adding a timestamp then

Look again at the execution results
|
|
I’ve added the observer 10 times in the for loop here. Is the lambda causing the problem? Well, let’s type out the number of Observers and see what’s wrong. Look at the source code, as shown below: our observers are actually stored inside this map, we can find out the reason by taking out the size of this map.
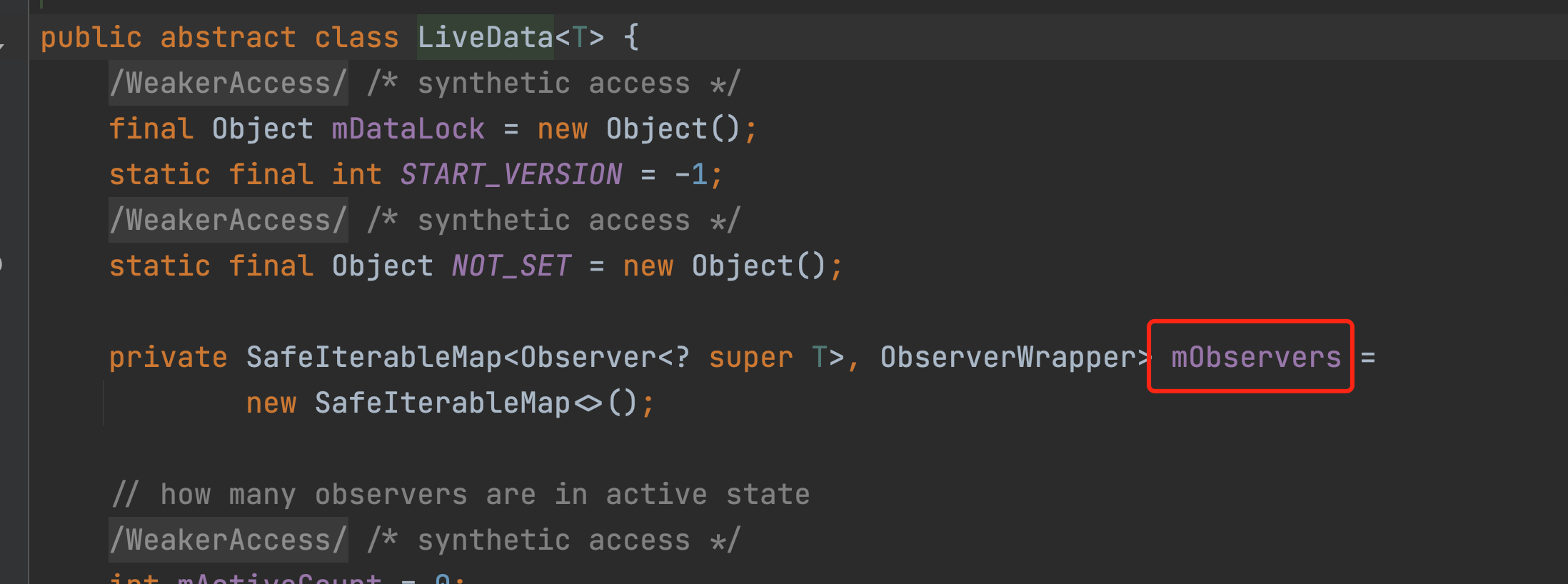
Reflect to read this size, note that the LiveData we normally use is MutableLiveData and this value is in the LiveData, so it is getSuperclass().
|
|
Look again at the execution results
Sure enough, the map size here is 1, not 10, so I must have received only 1 notification. So the question is, I’ve obviously added 10 observers to the for loop, why did I change to lambda and have 1 observer? Let’s decompile (using jadx to decompile our debug app directly) and see.
|
|
It is clear to see that the compiler has been clever in the compilation process because of the use of Java8 lambda, so the compiler automatically helps us to optimise Chengdu to add the same static observer, not 10, which explains why the map size is 1. We can remove the lambda again and see if the decompilation works.
One last question: does this lambda optimisation work regardless of the scenario? Let’s try a different way of writing
Note that although we also use lambda in this way, we have introduced external variables, which are different from the previous lambda, and look at the result of decompiling this way.
It’s reassuring to see the new keyword, and this way of writing gets around the Java8 lambda compilation optimizations.
Does Kotlin’s lambda writing style have pitfalls?
Considering that most people use Kotlin nowadays, let’s try to see if Kotlin’s lambda writing style has the same pitfalls as Java8’s lambda.
Take a look at the way lambda is written in Kotlin.
Look again at the results of the decompilation.
|
|
It seems that Kotlin’s lambda compilation is just as aggressive as Java8’s lambda compilation, in that it takes the for loop and optimises it to an object by default. Likewise, let’s see if there’s any more “negative optimisation” by having the lambda access external variables.
See the result of the decompilation
|
|
Everything is working fine. Finally, let’s look at the non-lambda writing of ordinary Kotlin. Is it the same as the non-lambda writing of Java?
See the result of the decompilation
Everything is fine, and here we can draw a conclusion.
For scenarios where a lambda is used in the middle of a for loop, when no external variables or functions are used in your lambda, then either the Java8 compiler or the Kotlin compiler will by default optimize it for you to use the same lambda.
The compiler’s starting point is a good one, and newing different objects in a for loop will of course lead to some degree of performance degradation (after all, what’s new ends up in gc), but such optimizations may often not meet our expectations, and may even cause us to misjudge in certain scenarios, so be careful when using them.
Why LiveData receives messages before Observe
Analyze the source code to find the reason
Let’s look at an example.
|
|
What this code means is that I update a livedata to a value of 3, and then 3s later I livedata register an observer. Note here that I updated the livedata value first and then registered the observer some time later, so in theory I should not have received the livedata message at this point. Because you sent the message first and I observed it later. But the result of the program execution is :
|
|
This one is just plain weird and doesn’t fit the design of a message bus framework that we commonly see. Let’s take a look at the source code to see what’s really going on.
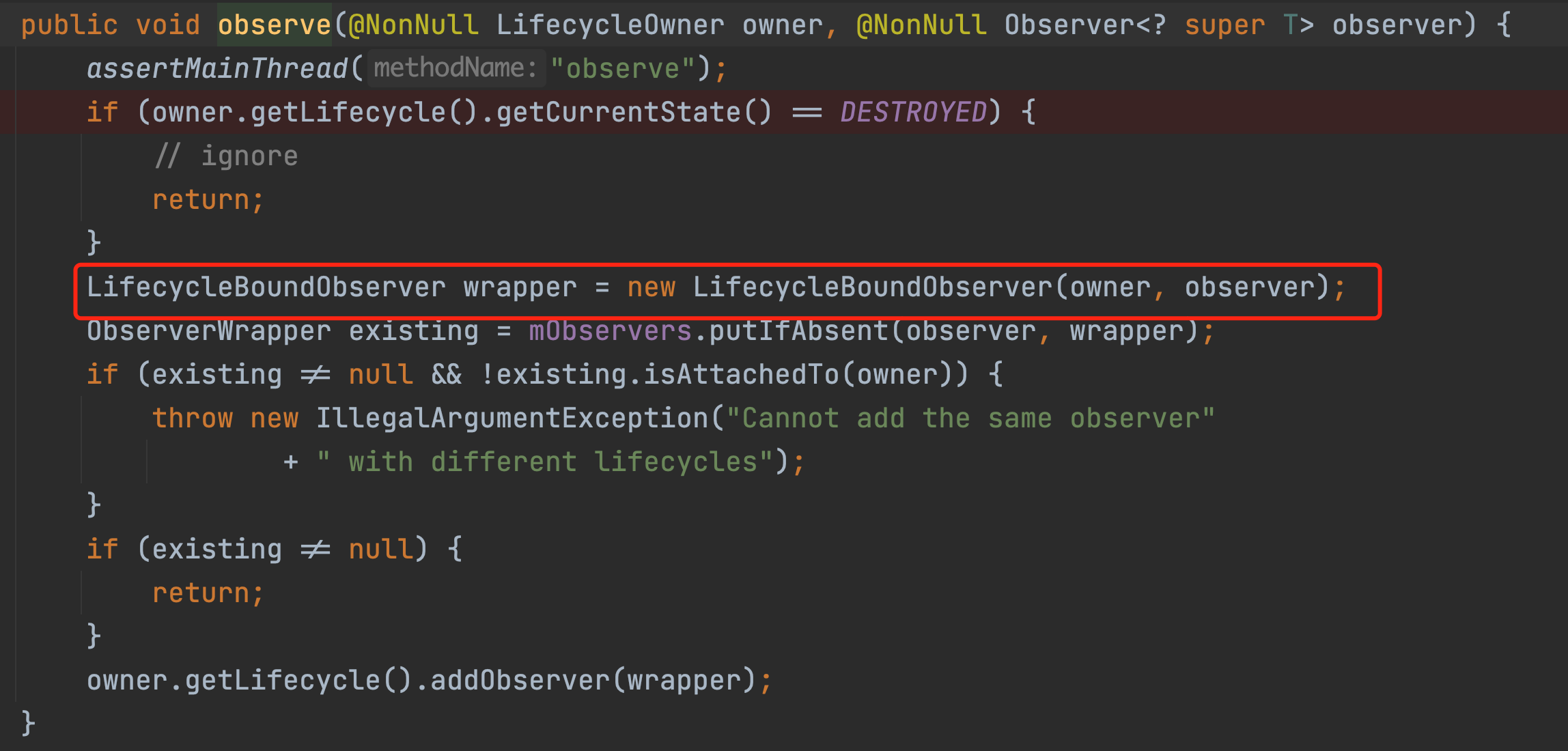
Each time we observe we create a wrapper, see what this wrapper does.
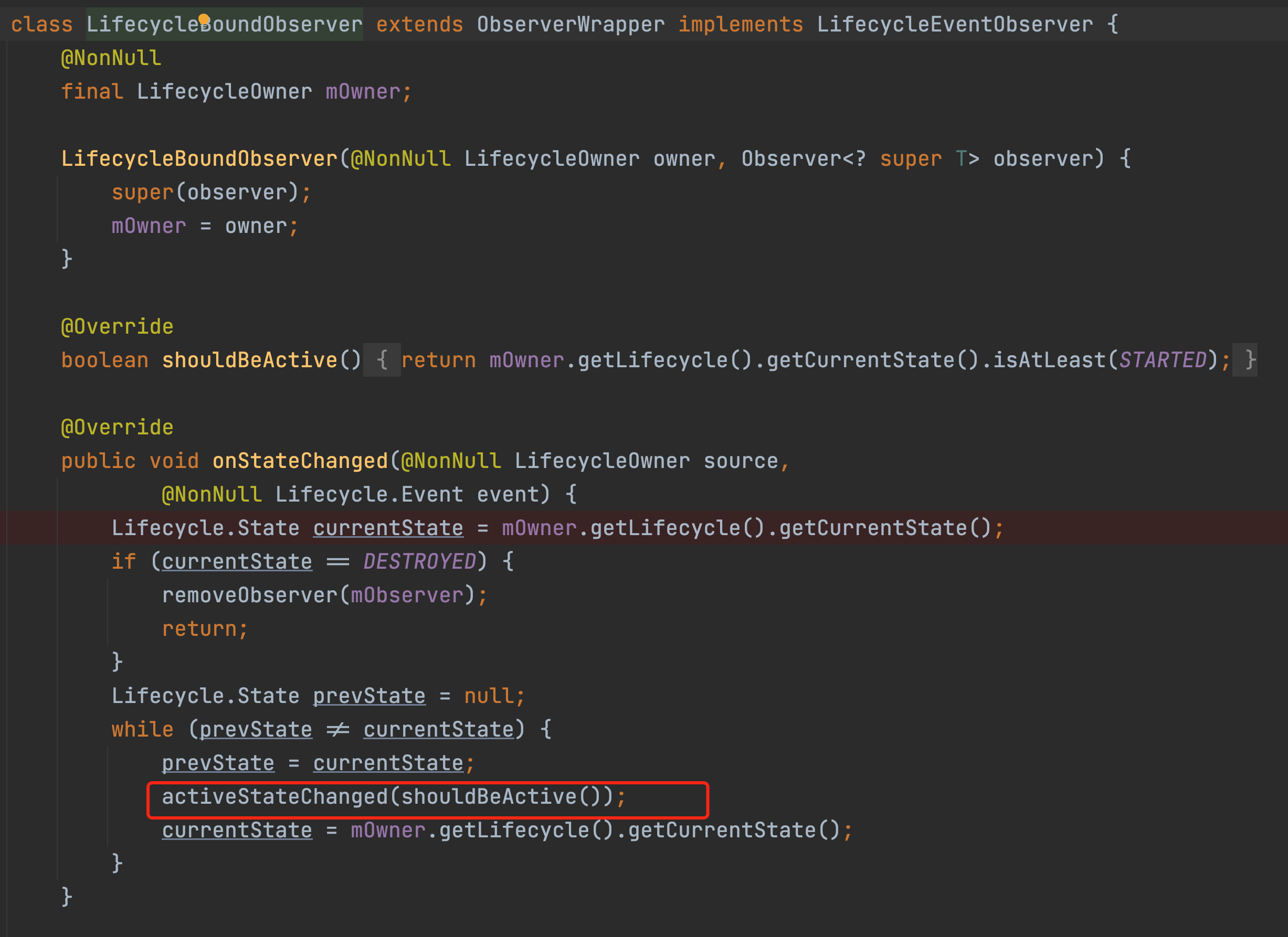
Note that this wrapper has an onStateChanged method, which is the core of the whole event distribution, so let’s remember this entry for now. Going back to our previous observe method, the last line is a call to the addObserver method, let’s see what is done in this method.
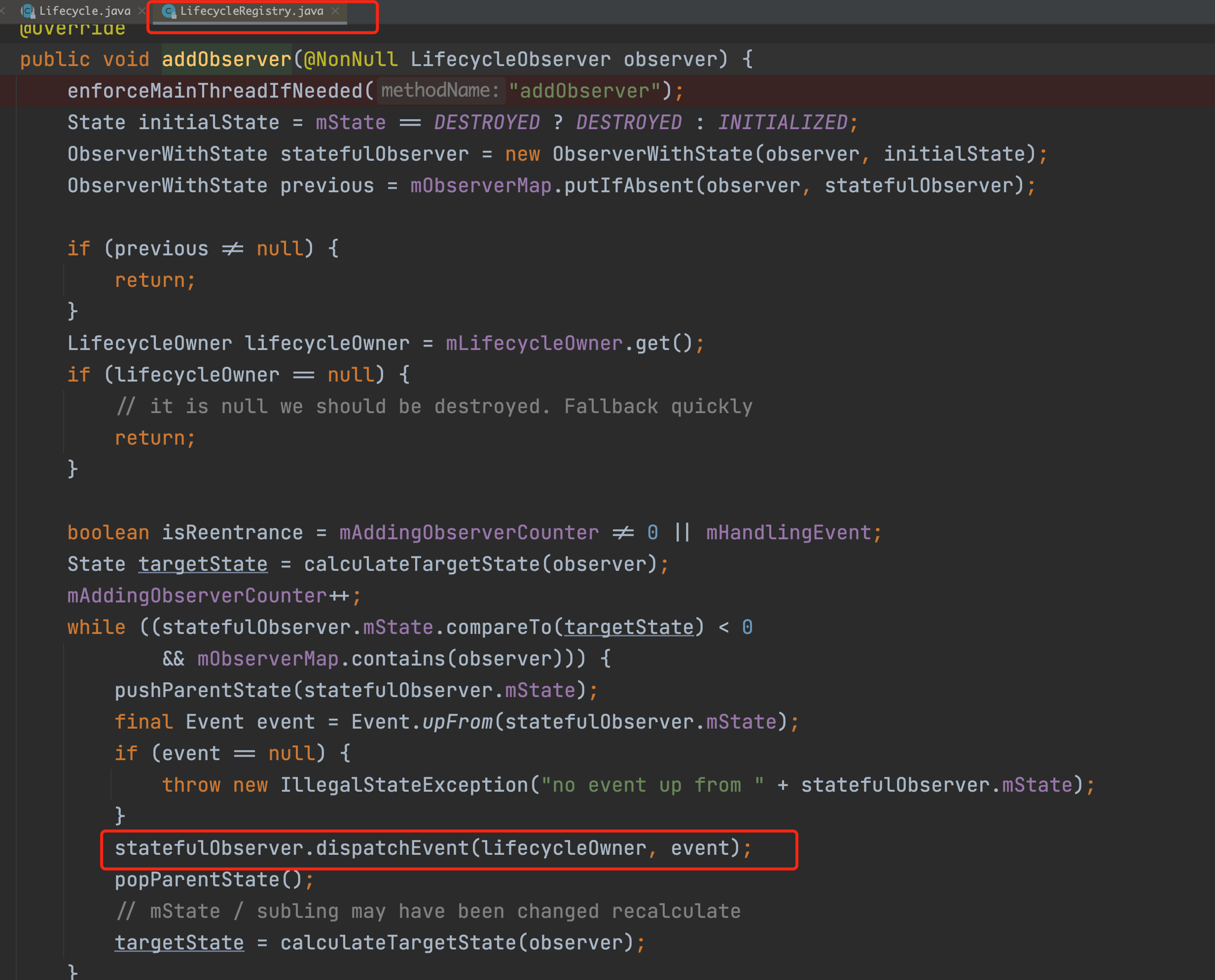
Eventually the flow will go to this dispatchEvent method and continue to follow.
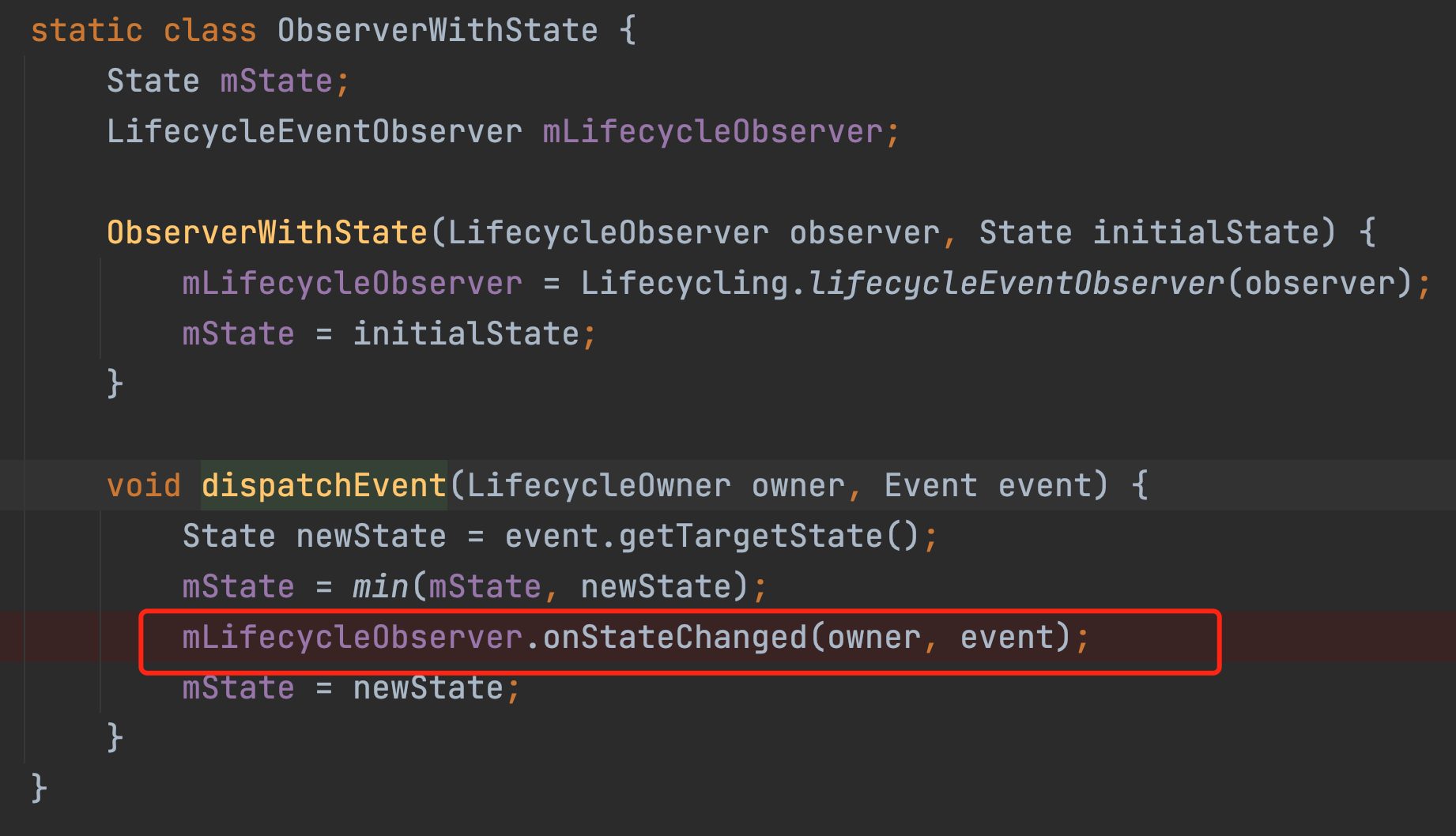
The mLifeCycleObserver is in fact the LifecycleBoundObserver object we created in the observe method at the beginning, which is the variable of the wrapper. The onStateChanged method will eventually go through a series of calls to the considerNotify method as shown in the diagram below.
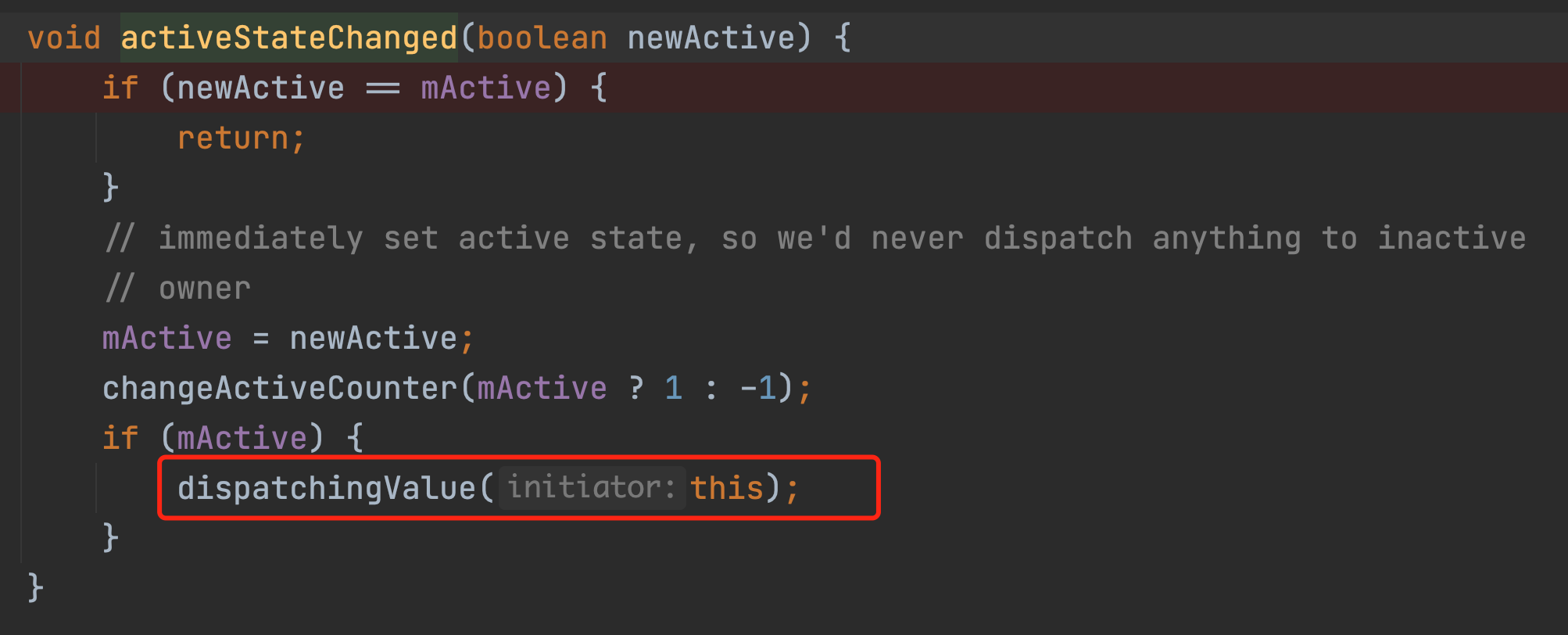
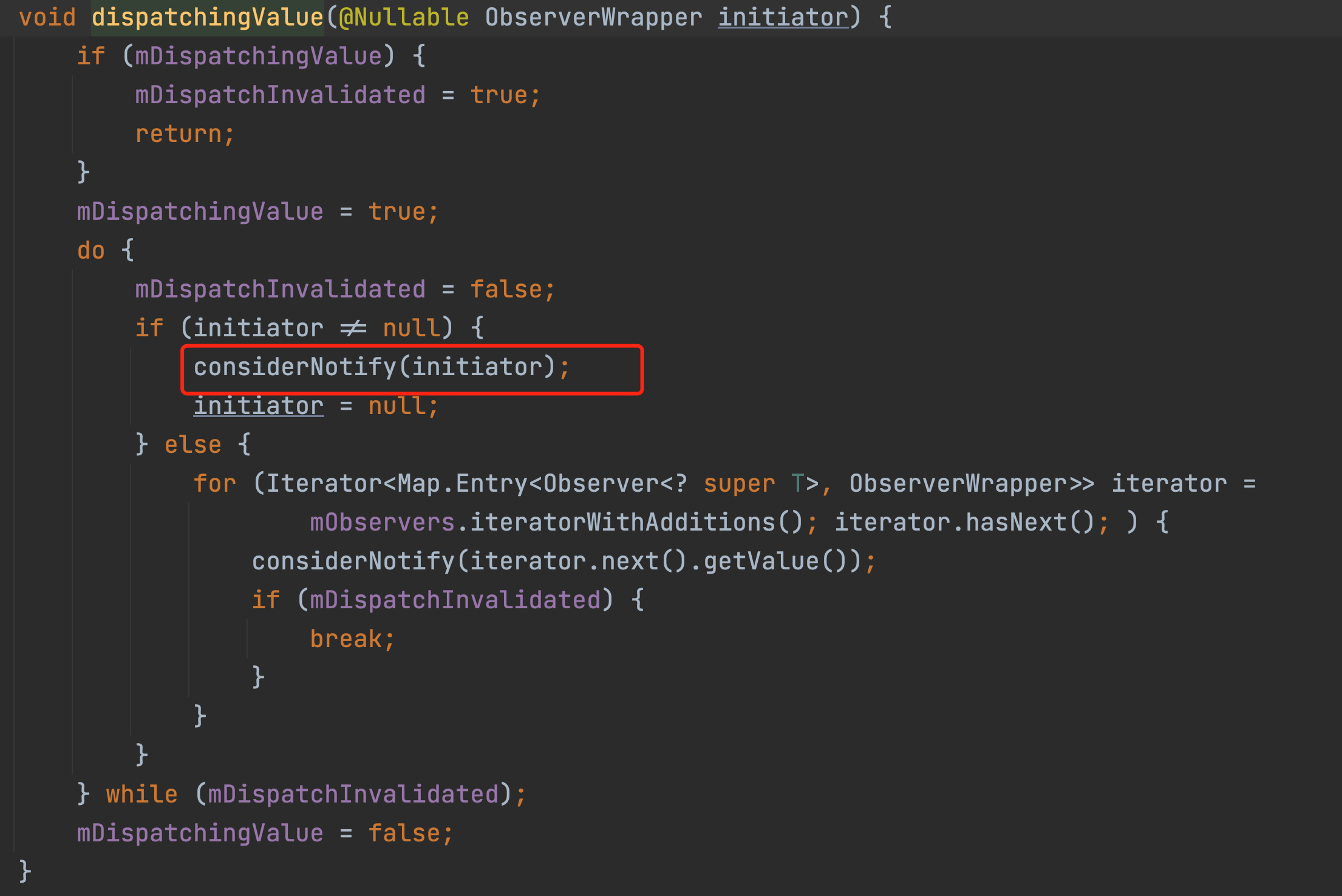
And the whole considerNotify method has only one effect.
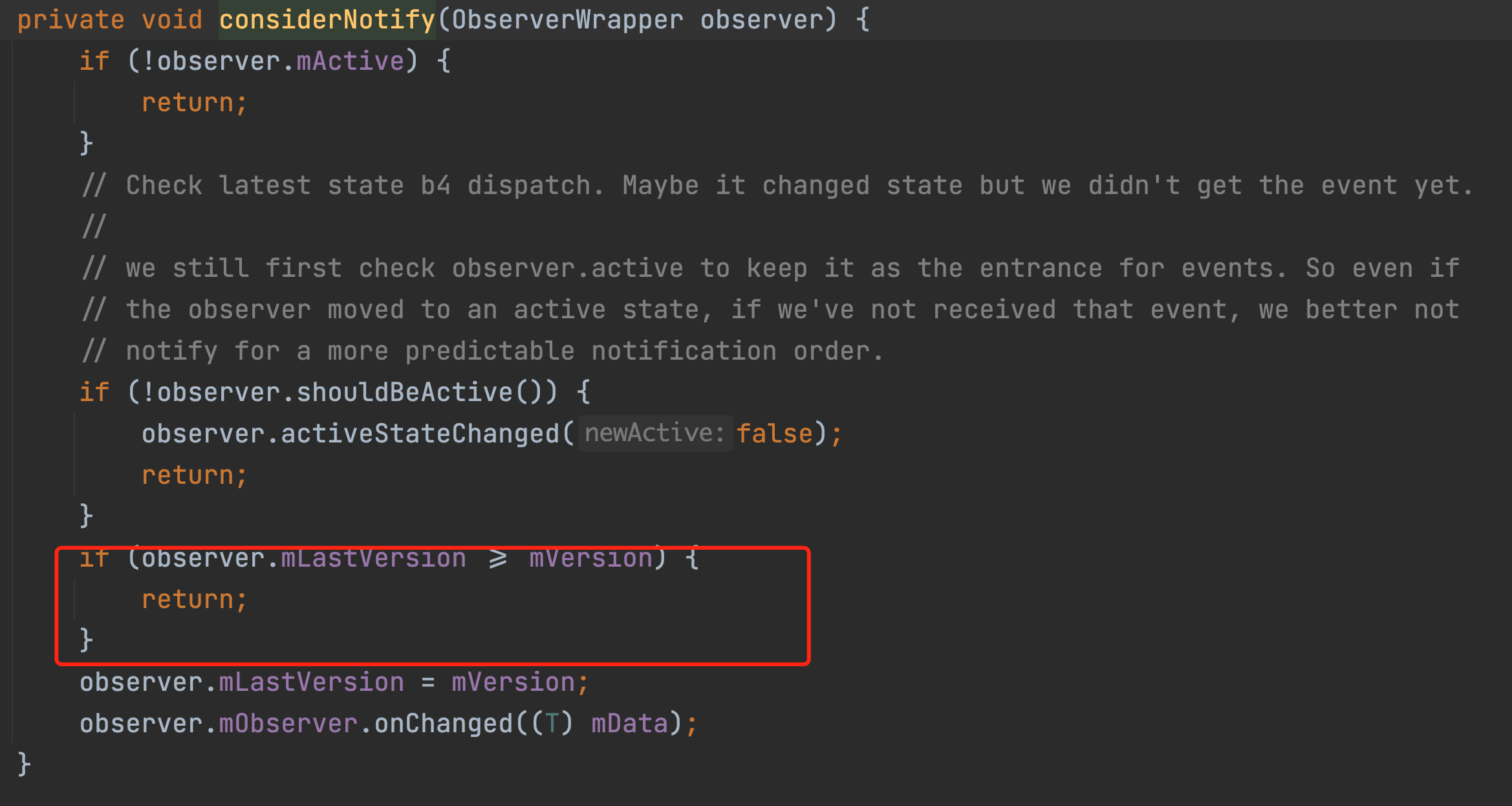
If the value of mLastVersion is < mVersion, then the onchaged method of the observer will be triggered, which means that it will call back to our observer method.
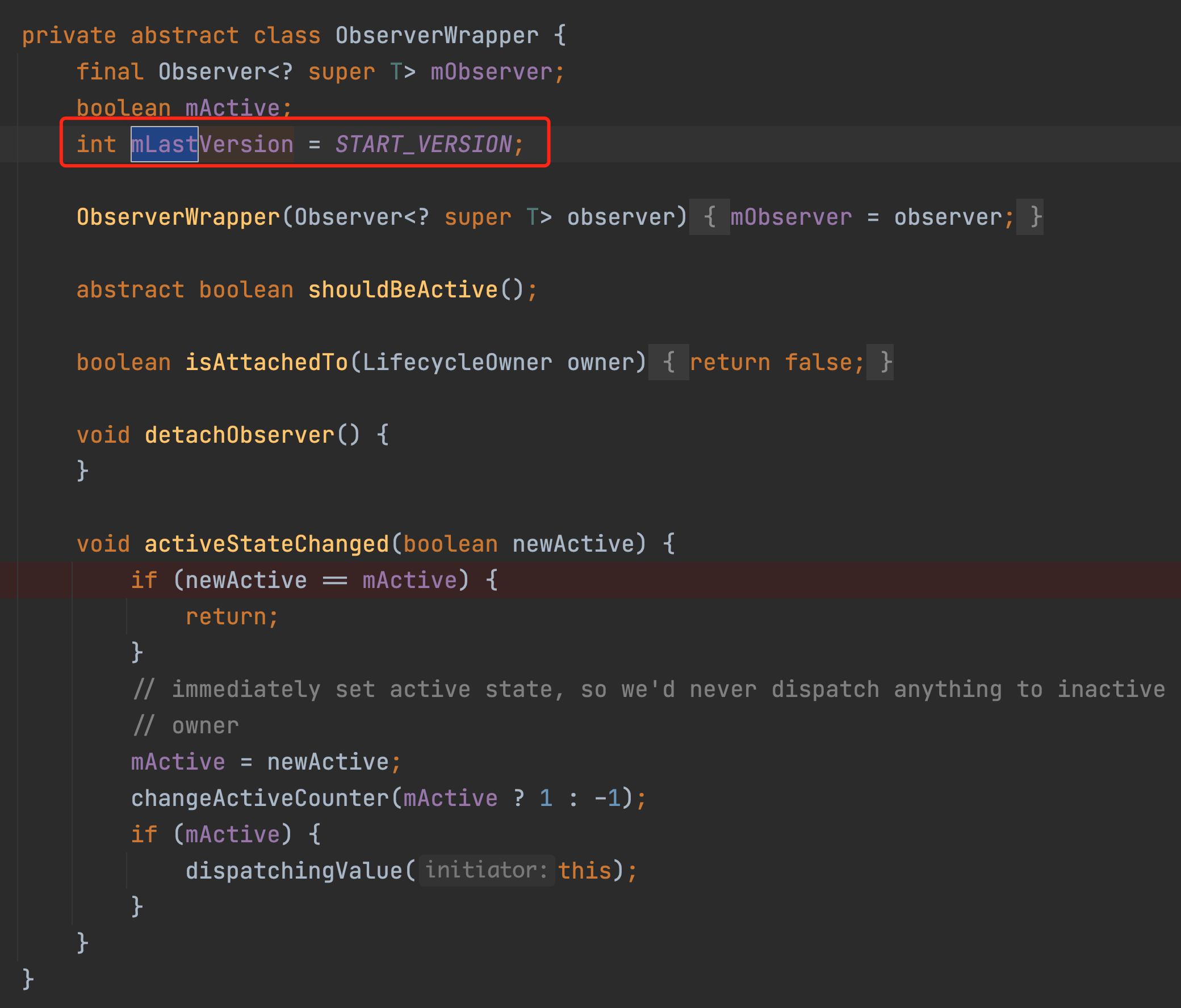
Let’s see how these two values change. First look at this mVersion.

You can see that this value defaults to start_version, which is -1, but it is added by 1 each time the value is set.

The initial value of mLastVersion in our observer is -1.
To conclude.
- The initial value of Livedata’s mVersion is -1.
- After one setValue, her value becomes 0.
- An ObserverWrapper is created each time you observe.
- The Wrapper has a mLastVersion inside which is -1. Observe function calls will eventually go through a series of processes to the considerNotify method.
- 0 is obviously greater than the observer’s mLastVersion-1, so the observer’s listener function will definitely be triggered at this point.
Be careful with ActivityViewModels
This feature of Livedata can have disastrous consequences in certain scenarios, for example, in a single Activity with multiple Fragments, it is very inconvenient to synchronize the Activity-Fragment without the Jetpack-mvvm component, but with the Jetpack-mvvm component, it is very easy to implement this mechanism. But with the Jetpack-mvvm component, it is very easy to implement this mechanism. Here is an example from the website.
|
|
Just make the set of ActivityViewModel shared between the 2 fragments. It’s easy to use, but in some scenarios it can lead to some serious problems. Let’s take a look at this scenario, we have an activity that shows the ListFragment by default, after clicking on the ListFragment we will jump to the DetailFragment.
Take a look at the code.
A further look at the core ListFragment.
|
|
You can see that our implementation mechanism is to click the button after we call the viewModel’s userClicksOnButton method to navigateToDetails this livedata value to true, and then listen to this LiveData value, if it is true, then jump to Detail this details fragment.
This process at first glance is no problem, after clicking can indeed jump to the DetailFragment, but when we clicked the return button in the DetailFragment page, the theory will return to the ListFragment, but the actual implementation results are back to the ListFragment immediately after jumping to the DetailFragment.
Why is this? When you press the return button, the onViewCreated of the ListFragment will be executed again, and this time you observe, the value before Livedata is true, so it will trigger the process of jumping to DetailFragment again. The result is that your page never goes back to the list page.
Solution One: Introducing an Intermediate Layer
As the old saying goes, all problems in computing can be solved by introducing an intermediate layer. Here too, we can try the idea of “a message is only consumed once” to solve the above problem. For example, if we wrap the LiveData values in a layer.
|
|
This way we can just call the method getContentIfNotHandled() when we do the listening.
Solution 2: Hook LiveData’s observe method
We have analyzed the previous article, each time observe, mLastVersion value is less than the value of mVersion is the root of the problem, then we use reflection, each time the observer will be set to the value of mLastVersion and version equal to it.
|
|
Solution 3: Use Kotlin-Flow
If you’re still using Kotlin, the solution to this problem is much simpler, and even the process is made more manageable. At this year’s Google I/O conference, Yigit made it clear in the Jetpack AMA that Livedata exists to take care of Java users and will continue to be maintained in the short term (what that means is something you can taste for yourself), and that Flow, the replacement for Livedata, will become mainstream in the future (after all, Kotlin is becoming mainstream now). If you use Flow, the above scenario can be solved.
Rewrite the viewModel.
then just rewrite the way it listens.
|
|
We focus on the constructor for SharedFlow, a heat flow.

The default value is 0. So our code above will not receive the previous message. Here you can try changing this replay to 1 to reproduce the previous Livedata problem. The only drawback is that Flow does not support Java, only Kotlin.
Summary
On the whole, even with Kotlin Flow, LiveData is still an indispensable part of the current Android client architecture components, after all, its lifecycle safety and memory safety are too fragrant, which can effectively reduce the burden of our usual business development, and when using him we just need to pay attention to 3 aspects to avoid the pitfalls.
- Be careful with the lambda smart hints given by Android Studio
- Pay more attention to whether you really need Observe to register the message before listening
- Be careful when using ActivityViewModel between Activity and Fragment.