The Go source code directory structure and corresponding code files provide an insight into Go’s implementation of network I/O modes on different platforms. For example, it is based on epoll on Linux, kqueue on freeBSD, and iocp on Windows.
Since our code is deployed on Linux, this article uses the epoll wrapper implementation as an example to explain the source code implementation of I/O multiplexing in Go.
Introduction
I/O multiplexing
The term I/O multiplexing refers to the select/epoll family of multiplexers: they support a single thread listening to multiple file descriptors (I/O events) at the same time, blocking and waiting, and receiving a notification when one of the file descriptors is available for reading or writing. Just in case many students are not as familiar with select or epoll, here are a few words about these two selectors.
First let’s talk about what a file descriptor is, which, according to its initials, is also referred to as a FD, an abstraction used to represent a reference to a file. It is an index value that points to a table of records maintained by the kernel for each process that opens a file. When a program opens an existing file or creates a new file, the kernel returns a file descriptor to the process.
select
writefds, readfds, and exceptfds are three sets of file descriptors. select iterates through the first nfds of each set to find the descriptors that are readable, writable, and error-prone, collectively known as the ready descriptors.
The timeout parameter indicates the length of time blocking when select is called. If all file descriptors are not ready, the calling process blocks until a descriptor is ready, or until the blocking exceeds the set timeout, and then returns. If the timeout parameter is set to NULL, it will block indefinitely until a descriptor is ready; if the timeout parameter is set to 0, it will return immediately without blocking.
When the select function returns, the ready descriptor can be found by traversing the fdset.
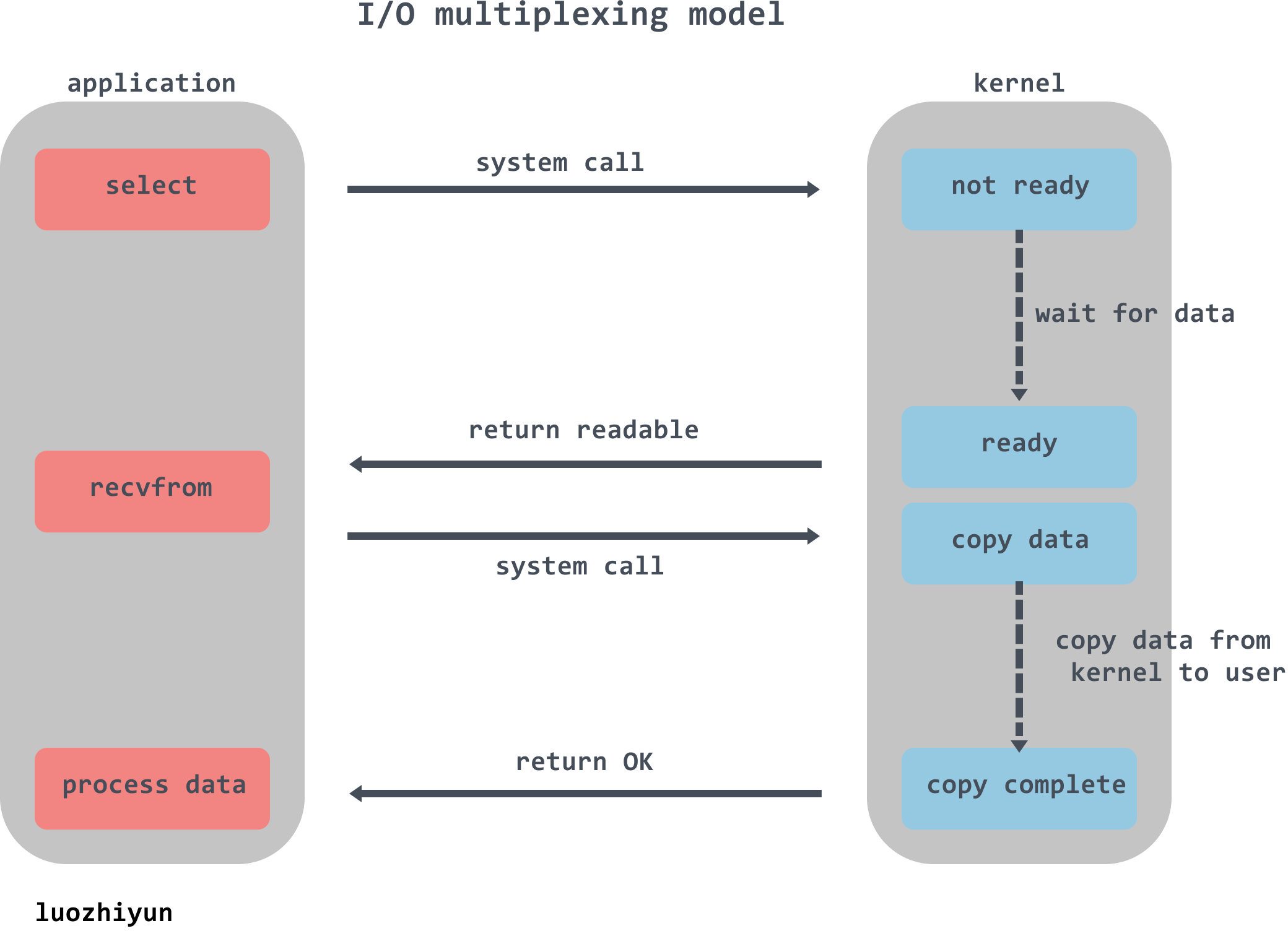
The disadvantages of select are also listed.
- The biggest drawback of select is that there is a limit to the number of fd’s that can be opened by a single process, which is set by FD_SETSIZE; the default value is 1024;
- Each time select is called, the set of fd’s needs to be copied from user state to kernel state, which is a significant overhead when there are a lot of fd’s;
- Each kernel needs to scan the entire fd_set linearly, so its I/O performance decreases linearly as the number of descriptor fd’s monitored grows;
epoll
epoll is an enhanced version of selec, avoiding the disadvantages of “high performance overhead” and “small number of file descriptors”.
To understand what follows, let’s look at the usage of epoll.
First create an epoll object instance epfd with epoll_create and return a file descriptor that references the instance. The returned file descriptor only points to the corresponding epoll instance and does not represent a real disk file node.
Internal storage for epoll instances.
- list of listeners: all file descriptors to listen to, using a red-black tree.
- ready list: all ready file descriptors, using a chain table.
The fd to be monitored is then added to epfd via epoll_ctl, and a callback function is set for the fd, and the event event is listened for and added to the list of listeners. When an event occurs, the callback function is called and the fd is added to the ready queue of the epoll instance.
Finally epoll_wait is called to block and listen for I/O events for all fd’s on the epoll instance. When there is already data in the ready list, then epoll_wait returns directly, solving the problem that select needs to be polled every time.
Advantages of epoll.
The epoll listener list is stored in a red-black tree. The fd’s added by the epoll_ctl function are placed in one of the nodes of the red-black tree, which has a stable insertion and deletion performance, a time complexity of O(logN), and can store a large number of fd’s, avoiding the limit of 1024 fd’s.
epoll_ctl specifies a callback function for each file descriptor and adds it to the ready list when it is ready, so there is no need to iterate through each file descriptor to detect it, as with select, but only to determine whether the ready list is empty.
Analysis
netpoll is essentially a wrapper around I/O multiplexing technology, so naturally it is the same as epoll, with the following steps.
- netpoll creation and its initialization.
- adding the tasks to be monitored to the netpoll.
- fetching the triggered events from netpoll.
The three functions provided by epoll are wrapped in go.
the netpollinit function is responsible for initializing the netpoll.
netpollopen is responsible for listening for events on the file descriptor.
netpoll blocks waiting for the return of a set of Goroutines that are ready to be used.
The following is a TCP server written in the Go language.
Here we follow the source code of this TCP server to see where netpoll is used to complete the epoll call.
net.Listen
This TCP server calls net.Listen to create a socket and return the corresponding fd, which is used to initialize the listener’s netFD (the go-level wrapper network file descriptor), and then calls the netFD’s listenStream method to complete the bind& listen and netFD.
The call process is as follows.
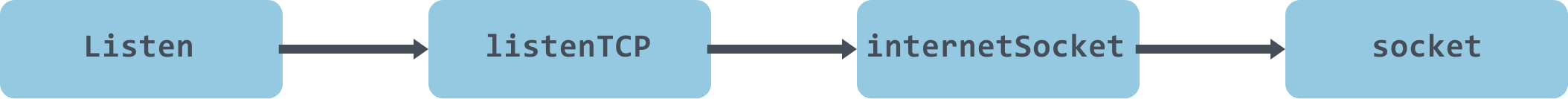
|
|
The sysSocket method will initiate a system call to create a socket, newFD will create a netFD, then call the listenStream method of the netFD to perform bind&listen operations and init the netFD.
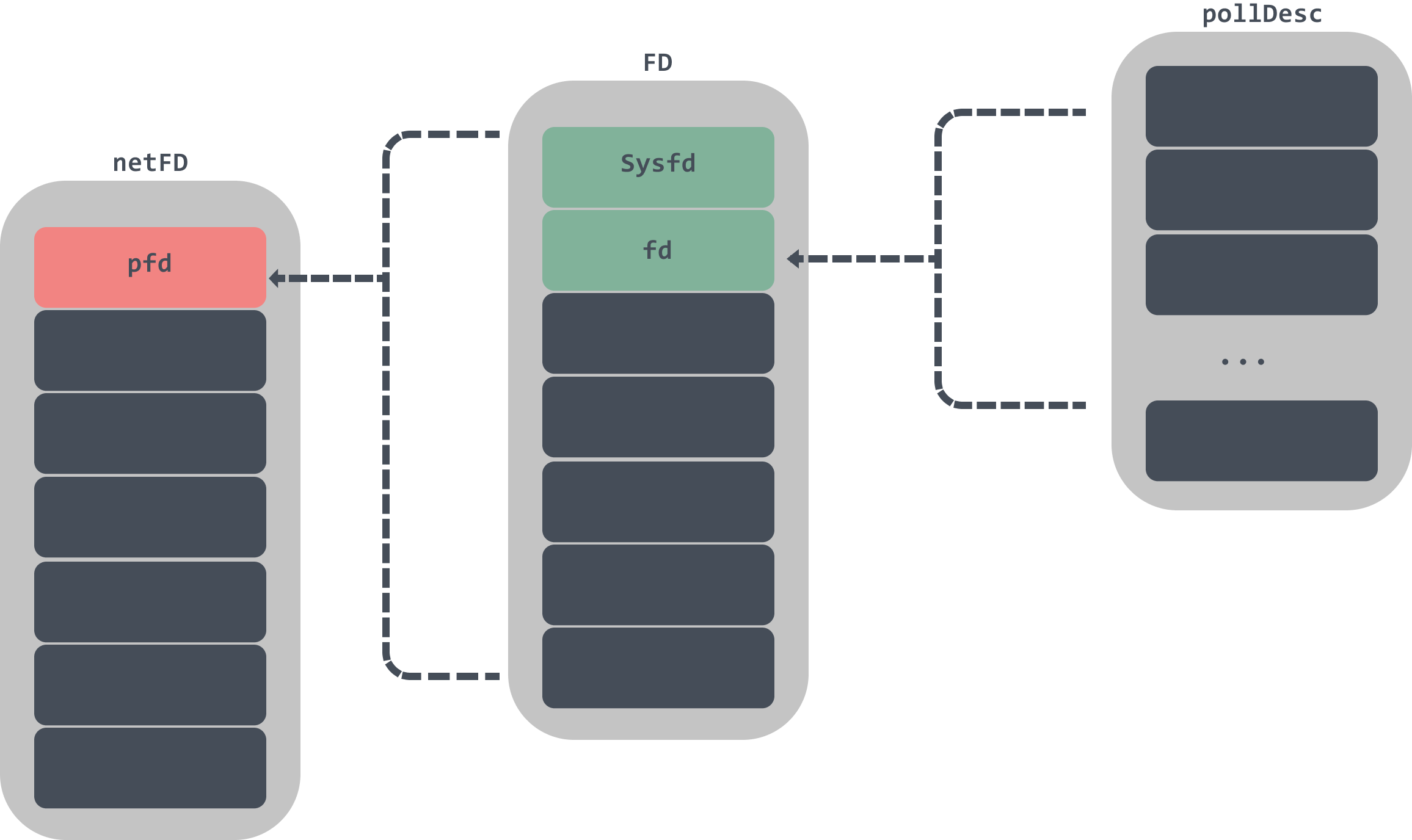
netFD is a file descriptor wrapper. netFD contains an FD data structure, which contains two important data structures, Sysfd and pollDesc. Sysfd is the socket system file descriptor returned by sysSocket, and pollDesc is used to monitor whether the file descriptor is readable or writable.
Let’s move on to listenStream.
|
|
The listenStream method will call the Bind method to complete the fd binding operation, then call listenFunc to listen, then call the init method of the fd to complete the FD, pollDesc initialization.
runtime_pollServerInit is wrapped in Once to ensure that it can only be called once; this function creates an epoll file descriptor instance on Linux platforms.
poll_runtime_pollOpen calls netpollopen which registers the fd to the epoll instance and returns a pollDesc.
netpollinit initialization
netpollGenericInit calls the platform specific implementation of netpollinit, which in Linux calls into the netpollinit method of netpoll_epoll.go.
|
|
Calling the epollcreate1 method creates an instance of an epoll file descriptor, it should be noted that epfd is a global property. Then a pipe is created for communication and epollctl is called to add the file descriptor for reading data to the listener.
netpollopen joins the event listener
Here’s another look at the poll_runtime_pollOpen method.
|
|
The poll_runtime_pollOpen method initializes a pollDesc structure with a total size of about 4KB via pollcache.alloc. Then it resets the properties of pd and calls netpollopen to add a new polling event to the epoll instance epfd to listen for the readable and writable state of the file descriptor.
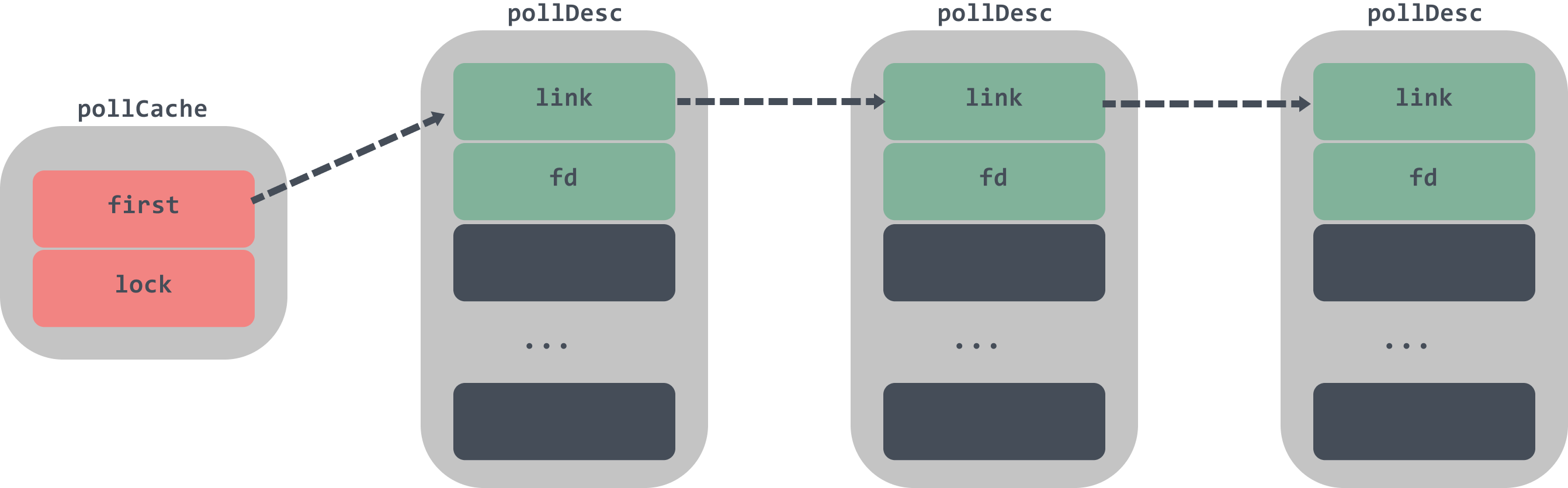
Let’s look at how pollCache initialises pollDesc again.
|
|
The pollCache’s chain table head, if empty, initializes the first node, which is a pollDesc’s chain table head, and each call to this structure returns the pollDesc whose chain table head has not yet been used.
This completes the analysis of net.Listen, so let’s look at listener.Accept.
Listener.Accept
The Listener.Accept method will eventually be called into the netFD’s accept method.

|
|
This method will first call Accept to the FD to accept a new socket connection and return the fd corresponding to the new socket, then call newFD to construct a new netfd and initialise it with the init method.
We have already seen the init method above, so let’s look at the Accept method.
|
|
The FD.Accept method receives new connections using the linux system call accept, creates the corresponding socket, and if there are no readable messages, waitRead is blocked. These parked goroutines will be woken up by calling runtime.netpoll in the goroutine’s dispatch.
pollWait event wait
pollDesc.waitRead actually calls runtime.poll_runtime_pollWait.
|
|
poll_runtime_pollWait will call the netpollblock function with a for loop to determine if an expected I/O event has occurred, and will not exit the loop until netpollblock returns true indicating io ready.
The netpollblock method will determine if the current state is in pdReady, if so then return true directly; if not then set gpp to pdWait via CAS and exit the for loop. The current goroutine is parked by gopark until a read/write or other I/O event occurs on the corresponding fd.
These parked goroutines will be woken up by calling runtime.netpoll in the goroutine’s dispatch.
netpoll polling and waiting
The core logic of runtime.netpoll is to set the timeout value of the call to epoll_wait based on the input delay, call epoll_wait to get the list of IO-ready fd’s from epoll’s eventpoll.rdllist bidirectional list, iterate through the list of fd’s returned by epoll_wait Assemble a runnable goroutine based on the context information encapsulated in the call to epoll_ctl to register the fd and return it.
After executing netpoll, a list of goroutines corresponding to the list of ready fd’s is returned, and the ready goroutines are then added to the scheduling queue to wait for scheduling to run.
|
|
netpoll calls epollwait to get a list of ready fd’s, the corresponding epoll function is epoll_wait. toRun is a chain of g’s that stores the goroutines to be resumed and finally returns them to the caller. If the n returned by epollwait is greater than zero, then it means that there is a pending event in the monitored file descriptor, and then a for loop needs to be called to process it. Inside the loop the mode will be set according to the time type and then the corresponding pollDesc will be taken out and the netpollready method will be called.
Here we look at netpollready again.
|
|
Having covered the source code of runtime.netpoll there is one thing to note, there are two calls to runtime.netpoll.
runtime.schedule()is executed in the scheduler, andruntime.findrunable()is executed in that method, whereruntime.findrunable()callsruntime.netpollto get the goroutine to be executed.- Go runtime creates a separate sysmon monitor thread when the program starts. sysmon runs every 20us~10ms, and each run will check if the last netpoll execution is more than 10ms away, and if so will call
runtime.netpollonce.
If you are interested in these entry calls, you can check them out for yourself.
Summary
This article started with I/O multiplexing to explain select and epoll, and then went back to the go language to see how it implements such a structure. By tracing the source code, you can see that go also wraps its own functions based on epoll.
These three functions are used to create instances, register, and wait for events on epoll.
Students who do not know much about I/O multiplexing can also take this opportunity to learn more about network programming and expand their knowledge.