Earlier in 2021, Python author Guido van Rossum was rehired by Microsoft to continue work on CPython, and they have proposed a faster-cpython project to improve the performance of CPython by a factor of 5 over 4 years. The whole project is open on GitHub’s faster-cpython group, and some of the ideas have been implemented and verified through Activity.
In this article, we will read and analyse the source code of one of the project’s key proposals, PEP 659, and learn how to optimise virtual machine performance at the bytecode level. We hope this will be of interest to you.
Proposal Explained
PEP 659 was created in April 2021 and is called Specializing Adaptive Interpreter. There are two keywords here: Specializing and Adaptive, which can be simply understood as Adaptive for specific location code, replacing it with special specializing) to improve the speed of execution of location-specific operations. For example, if we observe that the code for a particular dict does not change during multiple executions, we can optimise this code by caching the index of the dict entry directly, thus avoiding the hashtable lookup process in the next query and improving performance. The process of replacing the code corresponds to Specializing.
The above example is not exact, but is just to help you get a first impression of the Specializing Adaptive Interpreter, and we will now extract key statements from the proposal to explain them.
Firstly, it should be clear that PEP 659 is not a JIT solution, as it is intended to allow users who cannot directly use a JIT compiler such as PyPy to enjoy the benefits of faster CPython. For example, on iOS, user processes are limited by the fact that the executable code pages dynamically created by codesign are rejected on a page break because they do not contain a legal signature, and therefore cannot directly use the Python virtual machine with the JIT Compiler.
Some of you may be concerned about the scope and benefits of optimizing at the VM level without using JIT. In PEP 659, the authors also provide some explanation.
Specialization is typically done in the context of a JIT compiler, but research shows specialization in an interpreter can boost performance significantly, even outperforming a naive compiler.
That is, the study found that Specialization optimisation at the Interpreter level alone can yield significant performance gains that can outperform even some rudimentary JIT solutions. The authors also cite a previous paper of their own, which can be found in the references section of the PEP 659 proposal if you are interested.
We need to exhaust all possible optimisation cases and prepare the code in advance, replacing bytecode when matching optimisation conditions are observed, and being able to gracefully fall back to the pre-optimisation code to ensure correctness when the optimisation conditions are not met.
In order to be able to exhaust optimisation cases and switch code, it is necessary to choose the appropriate granularity of optimisation, the original proposal reads
By using adaptive and speculative specialization at the granularity of individual virtual machine instructions, we get a faster interpreter that also generates profiling information for more sophisticated optimizations in the future.
For example, in CPython, both globals and builtins are retrieved by the LOAD_GLOBAL instruction, which first looks in globals, and then fallsback to There are only 2 possible cases here, so we can add two new instructions to the virtual machine, LOAD_GLOBAL_MODULE and LOAD_GLOBAL_BUILTIN, and when we find that LOAD_GLOBAL in a bytecode segment keeps looking for globals, we can optimise it to the former and vice versa We can also cache the entry index of the globals and builtins dict to avoid repeated accesses to the hashtable of the dict, and roll back to the LOAD_GLOBAL instruction when we find that the optimisation conditions are not met (e.g. the find fails, or the dict is modified) to ensure correctness.
The above process from LOAD_GLOBAL to LOAD_GLOBAL_MODULE / LOAD_GLOBAL_BUILTIN is in fact Specializing in the PEP header, and the process of choosing whether to replace the instruction with LOAD_GLOBAL_MODULE or LOAD_GLOBAL_BUILTIN is in fact Adaptive, which is the process of choosing whether to replace the instruction with LOAD_GLOBAL_MODULE or LOAD_GLOBAL_BUILTIN. The process of choosing whether to replace an instruction with LOAD_GLOBAL_MODULE or LOAD_GLOBAL_BUILTIN is in fact Adaptive, which is responsible for observing the execution of the instructions in a given code and selecting the correct optimisation instruction for it, the process of observation is also the process of execution of the VM code, so an additional Adaptive instruction LOAD_GLOBAL_ADAPATIVE is introduced here to perform the observation and replacement logic.
Although Specializing can speed up the process by reducing judgements and increasing caching, the process of moving from the original instruction to the Adaptive instruction and from the Adaptive observation to the Specializing instruction is also lossy and therefore needs to be optimised based on certain strategies rather than mindlessly trying to optimise all instructions in the code, as mentioned in the original article.
Typical optimizations for virtual machines are expensive, so a long “warm up” time is required to gain confidence that the cost of optimization is justified.
This is because we need to insert optimisation code into large loops of bytecode execution, even requiring additional processing logic in each loop, while much of the code may only be executed once and it would be a waste of time to optimise them. One of the main features of such code is that it is called frequently. We can add a counter to each PyCodeObject (the object in CPython that holds the bytecode and environment information) and only execute the optimisation logic if the number of executions exceeds a certain threshold, a process called warm up.
At the virtual machine level, when a bytecode object PyCodeObject is executed (which can simply be interpreted as the bytecode corresponding to a piece of Python code being executed) or when an absolute jump occurs, the co_warmup counter of the code object is added up and when the threshold is reached all optimizable instructions in the bytecode are replaced with Adaptive instructions for observation and When the optimisation condition of the Specializing instruction is broken, we do not roll back to the Adaptive instruction immediately, but allow a certain number of misses to prevent bumps between optimisation and de-optimisation, and similarly when the de-optimisation is rolled back to the We also suspend the observation and optimisation logic when the de-optimisation rolls back to the Adaptive instruction, allowing the instruction to run according to the original logic for a period of time, a process known as deferred, the state diagram of which is as follows.
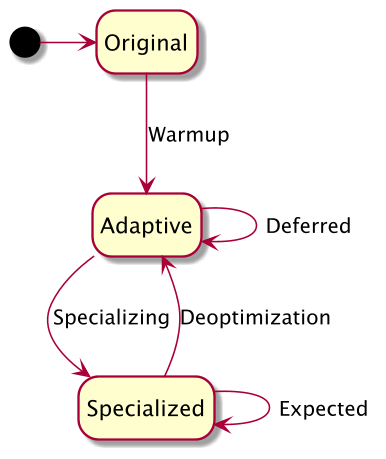
By now we have a good understanding of how PEP 659 works, but there are still many details that need to be explored in order to implement this optimizer in a high-performance way, such as which instructions to optimize, how to gracefully replace instructions and revert, and how to design instruction caches. 3.11, so we’ll combine this with the source code implementation of PEP 659 in Python.
Source code analysis
The infrastructure of PEP 659 and some of the optimization instructions are already present in the CPython 3.11 branch, so we’ll use the LOAD_GLOBAL transformation as an example to analyze the process in detail. The judgement is also relatively straightforward, clear enough to explain the problem without making it difficult to read because of the obscurity of the instructions.
The whole optimisation process consists of several stages - Warmup, Adaptive, Specializing & Deoptimize - and we will analyse and explain the functionality and core code of each stage.
Warmup
As mentioned above, warmup solves the problem of finding code that is really executed frequently and avoiding optimizing code that will never be executed again, so instead of counting the frequency of code execution, we just set a threshold and count the number of executions of a particular bytecode object PyCodeObject and consider the warmup complete when the threshold is reached. We have introduced a new field co_warmup for PyCodeObject
|
|
When the PyCodeObject object is created, the initial value of co_warmup is set to QUICKENING_WARMUP_DELAY, which is a negative value. co_warmup is set to +1 whenever the PyCodeObject is executed or when an absolute jump occurs within the code, and when the threshold of 0 is reached, the optimization logic is entered.
|
|
Adaptive
When co_warmuphas been accumulated to 0, it goes to the _Py_Quicken function to perform the optimisation logic, where a copy of the original bytecode co_code is officially stored in quickened because of the bytecode adjustments involved, and all subsequent changes occur in quickened.
|
|
You may wonder why quickened contains extra space other than bytecode. In fact, it is difficult to optimise just by replacing instructions, we also need to cache as many objects as possible for instruction operations. In CPython, the dictionary is a hashtable, so its complexity is greater than O(1) in case of hash collisions. In order to optimise dictionaries that do not change frequently, we can cache the hashtable index of the key, which obviously corresponds one-to-one with the instruction, so the extra space in quickened is used to store additional information about the optimised instruction.
quickened is a bi-directional array, with cache on the left and bytecode on the right, and a cache entry at the leftmost end of the array to store the cache count, which allows us to quickly locate the bytecode array. The first_instruction we saw earlier was located from quickened to instr 0 by means of cache_count.
|
|
Each optimized instruction requires a separate cache entry, and we need a means of O(1) indexing from the instruction to the cache. The official choice is to use offset + operand to build the secondary index, where offset is used to determine the block range of the index (it’s a bit like a page table search, where offset is PAGE and operand is PAGEOFF), operand is used to fix offset, and operand overridden by the index is stored in the cache. The above design was originally described in PEP 659 as follows.
For instructions that need specialization data, the operand in the quickened array will serve as a partial index, along with the offset of the instruction, to find the first specialization data entry for that instruction.
For LOAD_GLOBAL, the main information to be cached is the version of the dict and the key index, in addition to some additional information required by the optimizer, as follows.
- the version of the dictionary key-value pair dk_version, since both globals and builtins are involved here, we need to cache two dk_versions, each of which is a uint32_t, so the total dk_version needs to be an 8B, i.e. a cache entry.
- the index corresponding to the key, which is a uint16_t, can only use an additional cache entry here as we have already taken up one cache entry.
- since the original operand is used for the partial index, we also need an additional uint8_t to store the original_oparg, which can be combined with the uint16_t in 2.
- in the proposal reading section we mentioned that conversions between Adaptive, Specilization and Deoptimize need a counter buffer to avoid bumps and a counter is needed, officially a uint8_t is used here.
Putting the above analysis together, LOAD_GLOBAL requires two cache entries, the first storing orignal_oparg + counter + index and the second storing the dk_version of globals and builtins.
When a LOAD_GLOBAL hits globals in the Adaptive logic, we optimize it to LOAD_GLOBAL_MODULE and cache the index and module_keys_version; when a LOAD_GLOBAL does not hit globals, we need to cache both module_keys_version and builtin_keys_version, because when the globals change, it may cause the next This is because a change in globals may result in the next LOAD_GLOBAL not hitting the builtins, where we optimise this to LOAD_GLOBAL_BUILTIN, a process of optimised selection and caching that is effectively Adaptive.
##s# Specializing & Deoptimize
As mentioned above, after the Warmup and Adaptive processes, the bytecode object PyCodeObject has become Specialized, e.g. LOAD_GLOBAL is now all in the form of LOAD_GLOBAL_MODULE or LOAD_GLOBAL_BUILTIN. (Deoptimize is not considered here). In plain English, the instructions in the bytecode have been optimally adapted to the current environment, so let’s see how the adapted code looks like.
In fact, after the above analysis, I believe that you have already guessed the adaptation code, so let us take the more complex LOAD_GLOBAL_BUILTIN as an example and analyse the source code.
|
|
Let’s ignore DEOPT_IF for a moment and look at the main logic. First we take out the cache entries of the current command, the first entry records index, the second entry records the dk_version of globals and builtins. If the cache hits, we can simply fetch the key-value pair from hashtable[index] and return its value, which is much faster than checking the globals dict first and then the builtins dict.
But don’t rejoice too soon, the reduction is actually not less than one, we know that only when globals cannot be found will we look for builtins, if globals changes then the cache is bound to fail, in addition our index cache is based on the premise that builtins dict cannot change, combined with the above two points we must first make sure that both dictionaries’ dk_version version of both dictionaries before we can continue, which is actually one of the triggers for Deoptimize, which is exactly what DEOPT_IF does.
|
|
What DEOPT_IF does is jump to the cache miss branch of the instruction, for LOAD_GLOBAL it is LOAD_GLOBAL_miss, the miss branch does something very fixed, the first thing that is clear is that it will fallback to the regular LOAD_GLOBAL branch (JUMP_TO_INSTRUCTION at the bottom), but it will never roll back the instruction to LOAD_GLOBAL, only between Adaptive and Specialized instructions. INSTRUCTION), but it will never roll back instructions to LOAD_GLOBAL, only between Adaptive and Specialized instructions. To avoid cache bumps, the code above will degrade to the Adaptive instruction only when counter decrements to 0, and will always try to access the cache first until then.
This concludes our analysis of the whole optimisation and de-optimisation process, which is complex, but has a clear set of rules that make it easier to adapt other instructions once the Cache and Adaptive infrastructures have been built. One of the difficulties in accelerating instructions in this way is how to design the cache to reduce branching, as the presence of DEOPT_IF makes it difficult to directly reduce the preceding conditional judgements, but only to translate them into a more efficient form.