Previously, I only knew a little bit about percolator, and my impression of it is that it can implement transaction capability on top of a common distributed KV storage, but the overhead of 2PC + raft process is considerable. A few days ago, I heard that cockroachdb has made some engineering optimizations compared to percolator, so I’d like to learn how to implement this part.
The same as percolator, crdb also implements multi-line transaction management according to decentralized transaction manager. The difficulty lies in the fact that each row operation may have concurrent competing conditions. The transaction commit protocol uses a single machine’s atomic transaction capability to arbitrate concurrent operations in order to achieve atomic multi-row transaction commits, and also uses a single machine’s atomic transaction to promote exception recovery for exceptions at different stages.
The difference with percolator is that percolator is based on existing lower-level general-purpose KV storage, allowing transaction meta-information to be embedded in common KVs, while crdb can be designed more end-to-end to do some of its own form of storage for transaction meta-information.
This paper is organized broadly in the following sections.
- Transaction meta-information and regular transaction processes
- Concurrency control
- Parallel Commit Optimization
TransactionRecord and WriteIntent
crdb slices data into ranges, similar to regions in tidb, each range is about 64mb in size, and each range can execute a single transaction internally.
Within each range, crdb allocates separate regions to hold TransactionRecord and WriteIntent, which are the main meta-information related to transactions.
- TransactionRecord will be used to hold the status of the transaction (PENDING, COMMITTED, ABORTED), with a timeout.
- WriteIntent is equivalent to a write lock and a staging area for new data. At most one WriteIntent can exist at the same time for the same Key and is used for pessimistic mutual exclusion, and each WriteIntent in a transaction will point to the same TransactionRecord.
Recall that the percolator selects the first row written in the transaction as Primary Row, and then makes the other Rows point to Primary Row, and the concurrent operations of other Keys are aligned to Primary Row, and the overall state of the transaction is determined by the commit status saved in Primary Row.
The first row of the transaction is also selected to play a special role in crdb, and the TransactionRecord is saved in the same range as the first row, so that all WriteIntent in the transaction points to the TransactionRecord. This is where it differs from the percolator at first glance.
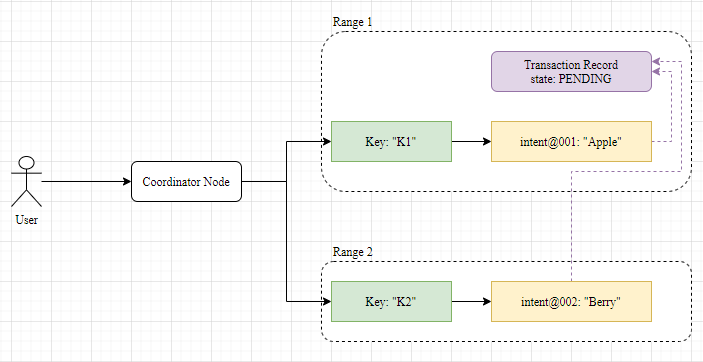
The Coordinator Node is the node that users connect to when they access the crdb cluster, and it makes itself the Coordinator to drive the transaction process forward.
Once all the keys have been written in one phase, the Coordinator drives the commit phase, which is a two-phase commit: the Transaction Record is marked as COMMITTED, which serves as a Commit Point to return a successful commit to the user, and the Coordinator drives the asynchronous cleanup of the Write Intent. If a user accesses the WriteIntent during this period, the status of the Transaction Record is queried and a cleanup convergence operation is performed.
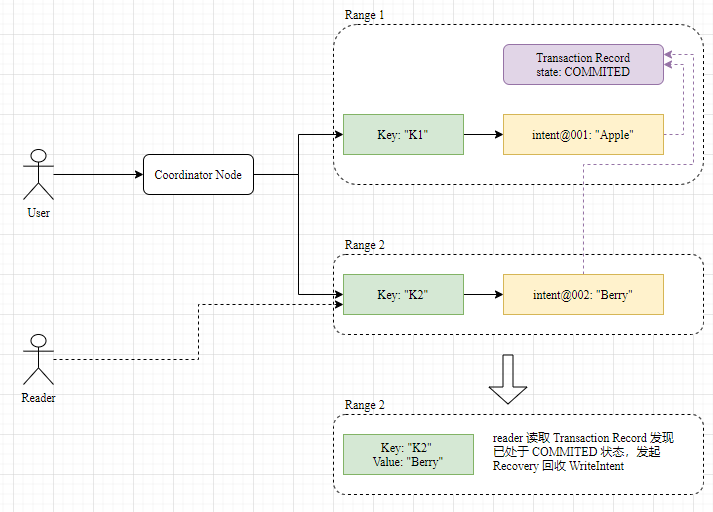
Eventually both the WriteIntent and TransactionRecord are cleared and the transaction is complete.
Unlike percolator, crdb, as a Serializable isolation level, has only one commit timestamp for the whole transaction, not two timestamps, startTs and commitTs. The timestamp here should only be used for MVCC, and the concurrency control level relies on the pessimistic concurrency control of locking. This single timestamp is also the logical embodiment of Serializable: Serializable is equivalent to all transactions executing sequentially, with transactions starting and ending in an atomic amount of time.
What happens if the Coordinator hangs
Each range already has a Raft, and the upper layers can generally assume they are reliable. But the Coordinator is a single point, and the probability of it hanging in the middle is not low enough to rely on it to guarantee the reliability of transactions. By design, crdb arranges for the Coordinator to drive the full lifecycle of the transaction, but when the Coordinator hangs, other visitors can still make the transaction go through the visitor-driven cleanup process if they encounter a leftover WriteIntent. Here is the same idea as percolator.
- If the transaction execution is interrupted before Commit Point, the key visitor drives the Rollback process, marking the transaction status as interrupted and cleaning up the transaction meta information on the key;
- If there is an interruption after Commit Point, the visitor drives the Roll Forward process to bring the latest value written by the transaction into effect and clean up the transaction meta information.
Unlike percolator, where each lock has a timeout, the timeout in crdb is maintained in the TransactionRecord, and the WriteIntent has no timeout. coordinator periodically renews the TransactionRecord heartbeat, and other visitors who find the If other visitors find that the TransactionRecord has timed out, they will consider the Coordinator dead and initiate the cleanup process, putting the TransactionRecord into the ABORTED state.
When a Key is accessed and a Write Intent is found to exist, the TransactionRecord is found along with the reference to the Write Intent and processed differently, taking into account its status.
- If it is found to be in COMMITTED state, the value in the WriteIntent is read directly and WriteIntent cleanup is initiated at the same time.
- If it is in the ABORTED state, the value in this WriteIntent is ignored and cleanup of the WriteIntent is initiated.
- If the PENDING state is encountered, a transaction in progress is considered to have been encountered.
- If the transaction is found to have expired, it is marked in the ABORTED state.
- If the transaction has not expired, conflict detection is performed in conjunction with the timestamp.
The logic for conflict detection is looked at in detail later.
Timestamp Cache and Read Refreshing
The Write Intent can be used to track write conflicts, but crdb is Serializable and needs to track read records as well, detecting conflicts for both read and write operations.
The crdb approach is to keep a Timestamp Cache in each range, which is used to store the timestamp of the last read operation of the Key in the range. As the name implies, the Timestamp Cache is a piece of in-memory data stored in the range and is not raft copied.
Whenever a write occurs, the timestamp of the current transaction is checked to see if it is less than the latest value of the Key in the Timestamp Cache. If it is, the current transaction’s write operation will invalidate the most recent read by another transaction. In a normal Serializable transaction process, the transaction conflict should be declared a failure at this point.
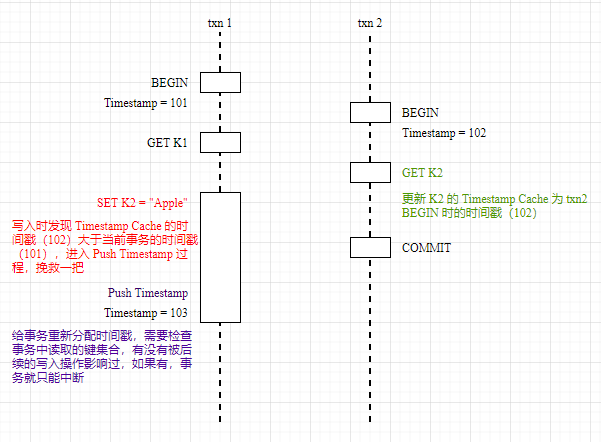
However, crdb does not exit directly from the transaction conflict here, but still retains a hand. The idea is: the current transaction has a Write after Read conflict with other transactions, can I push the timestamp of the transaction back to the current time, and then run a Write After Read conflict check to be OK.
However, the Push Timestamp has to satisfy a certain predicate, that is, whether there is a new write operation in the [original timestamp, new timestamp] range for the key read by the current transaction. If unfortunately there is a new write, there is no way to save it, and the transaction conflict is considered to have failed. This check is called Read Refreshing.
Push Timestamp is lighter and more user-friendly than directly reporting a transaction conflict and then retrying the entire transaction on the upper level of the user. I think this is also a place where pessimistic concurrency control is better than optimistic concurrency control.
Transaction Conflicts
There are several scenarios of transaction conflicts.
Read after Write: The Write Intent of an uncommitted transaction is read with a timestamp smaller than the current transaction. crdb adds the current transaction to the TxnWaitQueue queue to wait for the completion of dependent transactions. If the timestamp of the Write Intent read is greater than the current transaction, then there is no need to wait and the key is read directly by MVCC, which is equivalent to reading a snapshot of the current transaction moment.
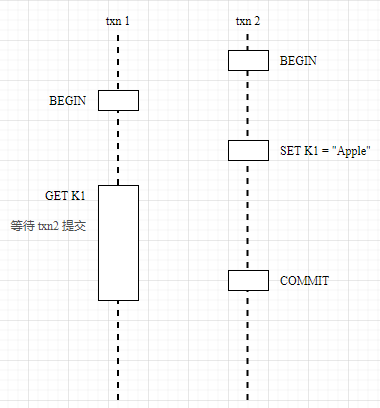
Write after Read: When writing, the timestamp of the current transaction must be greater than or equal to the timestamp of the last time the Key was read, and if there is a conflict, try to Push Timestamp to continue the transaction.
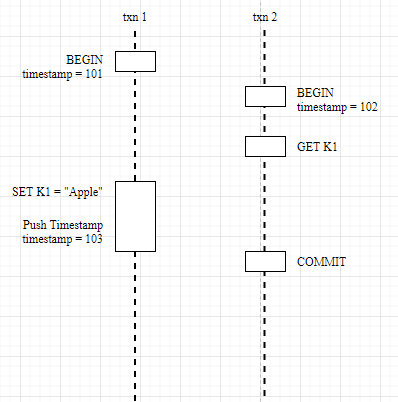
Write after Write: When writing, if an earlier uncompleted Write Intent is encountered, wait for that transaction to complete first. If an updated timestamp is encountered, the timestamp is pushed back by the Push Timestamp itself.
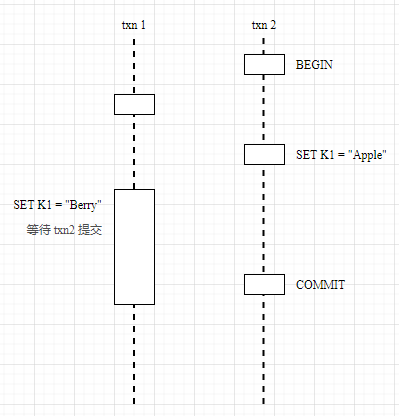
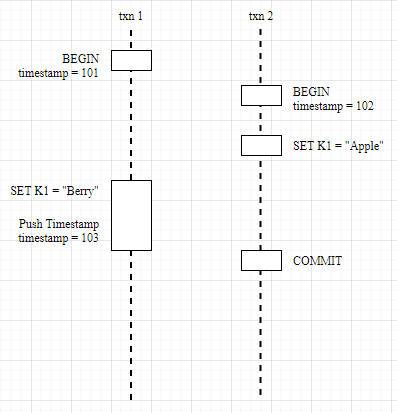
To summarize, there are two strategies for transactions to encounter conflicts.
- wait: mainly used when the start time of other transactions is earlier than the current transaction, and when a dependency is encountered, the current transaction waits for the other transaction to complete before executing.
- Push Timestamp: mainly used when the start time of the current transaction is earlier than the other transactions, and when a dependency is encountered, the current transaction first tries to push back the timestamp so that it becomes later than the other transactions, but the push back timestamp needs to go through the Read Refreshing precheck to ensure that the current transaction read set has not been modified, otherwise the transaction should also be interrupted.
Parallel Commit
The performance of the original percolator is very poor: Prewrite of each row of data needs to be replicated, and then each row of data is replicated again by Commit. If the lower level uses Raft to do replication, N rows of data, it is equivalent to perform 2 * N Raft consensus, and each Raft consensus is at least one fsync() trip. In contrast, a standalone DB only fsync() once, no matter how many rows of transactions.
In order to optimize the performance of commit, crdb first does Write Pipelining, where multiple rows of data written in a transaction are scheduled into a pipeline to initiate the consensus process in parallel, which reduces the waiting time from O(N) to O(2), with Prewrite and Commit going through two rounds of consensus process respectively.
Is it possible to further optimize the commit process? crdb introduces a new commit protocol, Parallel Commit, which enables one round of consensus process to complete the commit. The general idea is that in a two-stage commit, as long as all pre-writes have completed, the commit will not fail and the user can be safely returned with a successful commit.
So, how do you determine that all writes are complete? Two changes are made to the Transaction Record: 1. introduce the STAGING state, which indicates that the transaction has entered commit; 2. add the InFlightWrites field, which records the list of keys written by the current transaction. In addition, Transaction Record is no longer created at the beginning of the transaction, but at the time of user Commit(), so that we can know which keys have been modified by the transaction.
As per the example in the official documentation, the process of a transaction roughly proceeds as follows.
- The client contacts the Transaction Coordinator to create the transaction.
- The client tries to write a Write Intent with the key K1 valued at “Apple”, which generates the ID of the Transaction Record and makes the Write Intent point to it, but does not actually create the Transaction Record.
- The client tries to write a Write Intent with the key K2 valued at “Berry”, again making it point to the ID of the Transaction Record, which also does not exist.
- The client initiates a Commit(), which creates the Transaction Record with a status of STAGING and makes its InFlightWrites point to the [“Berry”, “Apple”] WriteIntents.
- Wait for concurrent writes of Write Intent and Transaction Record to complete to return success to the user.
- The Coordinator initiates the commit phase, makes the Transaction Record COMMITTED, and causes the Write Intent to be flushed to primary storage.
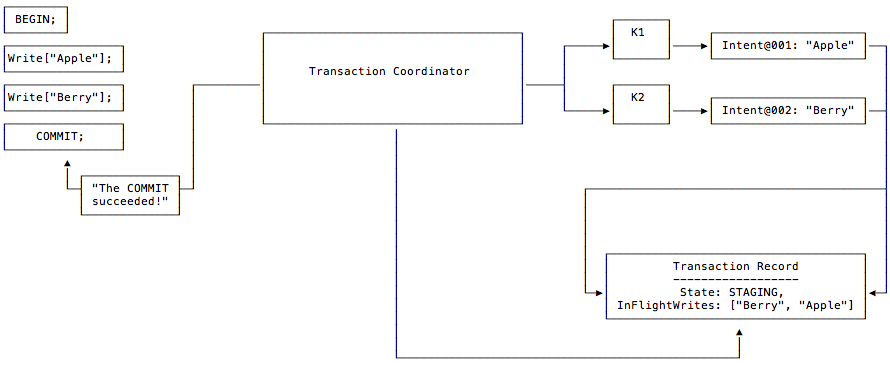
If the Coordinator hangs after a commit, the visitor reading the Write Intent’s Key first reads the corresponding Transaction Record and then accesses each Key via InFlightWrites to determine if the write was successful.
- If unsuccessful and the Transaction Record has timed out, the visitor drives the Transaction Record into the ABORTED state.
- If all Keys have been written successfully, they are considered to be in the Implicit Committed state, and the visitor drives the Transaction Record into the explicit COMMITTED state and causes the associated Write Intent to be flushed to primary storage.
It can be seen that while Parallel significantly reduces the wait time for the commit process, the visitor-driven exception recovery process becomes more expensive. crdb still wants to drive the commit process through the Coordinator as soon as possible in the normal process, so that the visitor-driven recovery process only serves as a last resort.