What is RESTful API?
REST: The full name is Resource Representational State Transfer, or Representational Layer State Transfer. Look at the concept, I guess no one can understand. Explain in a human word: URL to locate resources, using HTTP verbs (GET, POST, PUT, DELETE) to describe the operation.
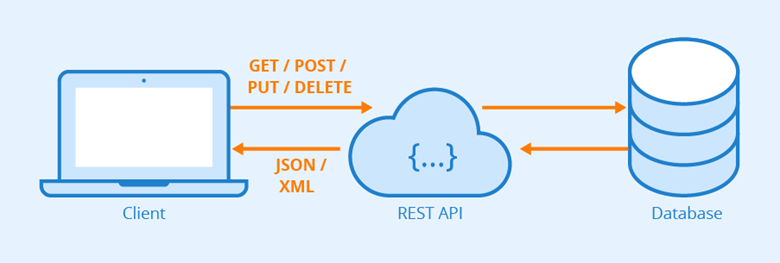
Resources
A “resource” is an entity on the Web, or a specific piece of information on the Web. It can be a piece of text, a picture, a song, a service, in short, a concrete reality. You can point to it with a URI (Uniform Resource Identifier), each resource corresponds to a specific URI. to get this resource, access its URI on it, so the URI becomes the address or unique identifier of each resource.
- URI: Uniform Resource Identifier
- URL: Uniform Resource Location
To “surf the web” is to interact with a series of “resources” on the Internet by calling its URI.
Representation
A “resource” is an information entity that can have multiple external representations. We call the specific presentation of a “resource” its “Representation”.
For example, text can be represented in txt format, HTML format, XML format, JSON format, or even binary format; images can be represented in JPG format or PNG format.
URI only represents the entity of the resource, not its form. Strictly speaking, the “.html” suffix at the end of some URLs is unnecessary because it represents the format and belongs to the “presentation layer”, while the URI should only represent the “resource " location. Its specific presentation should be specified in the HTTP request headers with the Accept and Content-Type fields, which are the description of the “presentation layer”.
State Transfer
Visiting a website represents a process of interaction between the client and the server. In this process, data and state changes are inevitably involved. The Internet communication protocol, HTTP, is a stateless protocol. This means that all state is stored on the server side. Therefore, if the client wants to operate the server, it must, by some means, allow the server side to undergo a “state transfer” (State Transfer). This transformation is built on top of the presentation layer, so it is called “presentation layer state transfer”. The means used by the client can only be the HTTP protocol. Specifically, the HTTP protocol has four verbs that indicate the operation: GET, POST, PUT, DELETE, which correspond to four basic operations.
- GET is used to obtain resources
- POST is used to create new resources (can also be used to update resources)
- PUT is used to update resources
- DELETE is used to delete resources.
The basic principles of REST
- C-S architecture: the storage of data on the Server side, the Client side just use it. The two ends are developed separately, without interfering with each other
- Stateless: http request itself is stateless, based on the C-S architecture, each request from the client side with sufficient information to enable the server side to identify. The server is able to return the response to the client correctly based on the various parameters of the request, without saving the client’s state.
- The REST interface constraint is defined as: the resource you want to operate is marked by uri, the operation to be performed is identified by the request action (http method), and the status code is returned to indicate the result of this request. The result of the request is indicated by the status code returned.
- Consistent data format: The server returns data in either XML or Json format, or directly as a status code.
- Cacheable: On the World Wide Web, the client can cache the response content of the page. Therefore responses should all be implicitly or explicitly defined as cacheable, or if not cacheable to avoid the client responding with old or dirty data after multiple requests.
- On-demand coding, customizable code: REST allows clients to extend client-side functionality by downloading and executing some scripting programs from the server. This simplifies the development of client-side functionality, such as common mobile webviews, web mini-games, etc.
Restful API Maturity Levels
In the Richardson Maturity Model model, RESTful is classified into 4 levels.
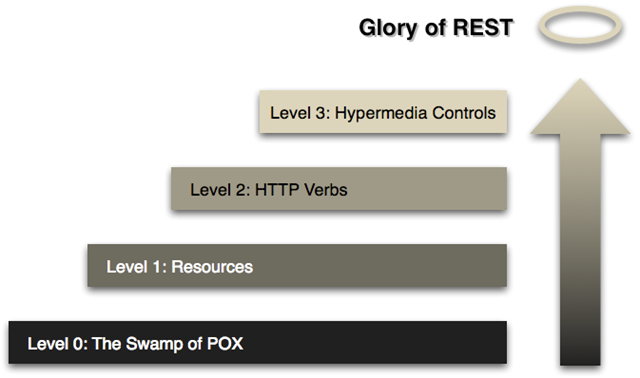
The 4 levels are.
- Web services at Level 1 (Level 0) use only HTTP as a transport and are really just a concrete form of Remote Method Call (RPC). both SOAP and XML-RPC fall into this category.
- Level 2 (Level 1) Web services introduce the concept of resources. Each resource has a corresponding identifier and expression.
- Level 3 (Level 2) Web services use different HTTP methods to perform different operations and use HTTP status codes to represent different results. For example, HTTP GET method to fetch a resource and HTTP DELETE method to delete a resource.
- Level 4 (Level 3) Web services use HATEOAS, which includes link information in the representation of resources. The client can discover the actions that can be performed based on the links.
RESTful API Design Essentials
Composition of URLs
Protocol
The API provided to the user, try to use HTTPs protocol. The use of HTTPs protocol or HTTP protocol itself is not related to the RESTful API, but it is important to improve the security of the site
Domains
APIs should be deployed under dedicated domains as much as possible.
|
|
If it is determined that the API is simple and will not be further extended, consider placing it under the main domain.
|
|
Version
The API is really not evolvable, then different versions of the API must be provided. version control allows to release incompatible and significantly changed APIs in new versions without breaking the client.
There are two most popular methods of version control.
- Versioning via URLs
- Versioning via Accept HTTP Header (content negotiation)
Versioning via URLs
Simply place the version number of the API in the URL of each resource. There is no need to use a secondary version number (“v1.2”) because you should not have to release API versions too often.
|
|
Pros.
- Very simple for API developers.
- Also very simple for client-side access.
- URLs can be copied and pasted.
Disadvantages.
- Not RESTful. (This approach causes URLs to change)
- Breaks URLs. Clients must maintain and update URLs.
Due to its simplicity, this approach is widely used by major vendors such as Facebook, Twitter, Google/YouTube, Bing, Dropbox, Tumblr, and Disqus.
Version control (content negotiation) via Accept HTTP Header
A more RESTFul approach is to use content negotiation via the Accept HTTP request header.
Pros.
- URLs remain the same
- RESTFul approach
- HATEOAS friendly
Disadvantages.
- Slightly difficult to use. Customers must pay attention to the title.
- Can no longer copy and paste URLs.
Github uses this approach.
Keep in mind that the API is a public contract between the server and the client. If you make a change to the API on the server and those changes are not backwards compatible, then you break that contract and the client will ask you to support it again. To avoid such a thing, you have to both ensure that the application evolves gradually and keep the client happy. Then you must introduce a new version of the API while keeping the old one still available.
If you are simply adding a new feature to the API, such as a new property on a resource or adding a new endpoint, you don’t need to increase the version of the API. Because these don’t cause backward compatibility issues, you just need to change the documentation. Over time, you may declare that some older versions of the API are no longer supported. declaring that a feature is not supported does not mean turning it off or breaking it. Rather, it tells the client that the old version of the API will be removed at a specific time and suggests that they use the new version of the API.
As systems evolve, there will always be APIs that fail or migrate, returning 404 not found or 410 gone for failed APIs and 301 redirects for migrated APIs.
Path (Endpoint)
The path, also known as the “endpoint”, represents the specific URL of the API.
In the RESTful architecture, each URL represents a resource, so there can be no verbs in the URL, only nouns, and the nouns used often correspond to the names of tables in the database. Generally speaking, tables in a database are “collections” of the same kind of records, so the nouns in the API should also use the plural.
For example, an API that provides information about the zoo, including various animals and employees, would have a path like the following.
https://api.example.com/v1/zooshttps://api.example.com/v1/animalshttps://api.example.com/v1/employees
Reduce path nesting
In some resource data modules with nested parent/child paths, the paths may have very deep nesting relationships, for example:
- /orgs/{org_id}/apps/{app_id}/dynos/{dyno_id}
It is recommended to specify resources under the root path to limit the nesting depth of the path. Use nesting to specify the scope of the resource, for example in the following case, under the dyno attribute app scope and under the app attribute org scope:
- /orgs/{org_id}
- /orgs/{org_id}/apps
- /apps/{app_id}
- /apps/{app_id}/dynos
- /dynos/{dyno_id}
Overly deep navigation tends to lead to url bloat that is not easily maintained, e.g. GET /zoos/1/areas/3/animals/4, or you can use query parameters instead of entity navigation in the path, e.g. GET /animals?zoo=1&area=3.
URI specification
- No capitalization
- Use middle bar-no lower bar_
- The parameter list should be encoded
Use a unified resource path
Use two URLs per resource
Use one URL for a collection of resources and one URL for a specific resource.
- /employees #URL of the resource collection
- /employees/56 # URL of a specific resource
Replaces verbs with nouns for resources
This gives you a cleaner API and a smaller number of URLs. Don’t design it like this.
- /getAllEmployees
- /getAllExternalEmployees
- /createEmployee
- /updateEmployee
Better design.
- GET /employees
- GET /employees?state=external
- POST /employees
- PUT /employees/56
Recommended plural nouns
The noun used often corresponds to the table name of the database, which is a collection of records, so the noun in the URL means a collection of resources, so the noun in the URI should be in the plural
Recommended.
- /employees
- /employees/21
Not recommended.
- /employee
- /employee/21
In fact, it is a matter of personal preference, but the plural form is more common. Also, use the GET method on the resource collection URL, it is more intuitive, especially GET /employees?state=external, POST /employees, PUT /employees/56. But most importantly: avoid mixing plural and singular nouns, which seems very confusing and error-prone.
Non-resource request with verb
Sometimes API calls do not involve resources (e.g., computation, translation, or conversion). Example.
- GET /translate?from=de_DE&to=en_US&text=Hallo
- GET /calculate?para2=23¶2=432
In this case, the API response does not return any resources. Instead, it performs an action and returns the result to the client. Therefore, you should use verbs rather than nouns in the URL to clearly distinguish between resource requests and non-resource requests.
Asynchronous tasks
For time-consuming asynchronous tasks, the server side should return a successfully created task resource containing the execution status of the task after accepting the parameters passed by the client. The client can rotate the task to get the latest execution progress.
Submitting tasks.
Response:
|
|
If the execution status of a task includes more information, you can abstract the “execution status” into a combined resource, and the client can query the status resource to know the execution status of the task.
Submitting a task.
response
|
|
Hypermedia API
RESTful APIs should ideally be Hypermedia, i.e. provide links to other API methods in the returned results, so that the user knows what to do next without checking the documentation.
For example, when a user makes a request to the root of api.example.com, they will get a document like this.
The above code indicates that there is a link attribute in the document, which the user reads to know what API to call next. rel indicates the relationship between this API and the current URL (collection relationship, and gives the URL of the collection), href indicates the path of the API, title indicates the title of the API, and type indicates the return type.
The design of the Hypermedia API is called HATEOAS. The Github API is of this design, and visiting api.github.com will give you a list of all available API URLs.
As you can see from above, if you want to get information about the current user, you should go to api.github.com/user and then you get the following result.
The above code indicates that the server gives the prompt message, as well as the URL of the document.
Correct use of HTTP verbs
The specific type of operation for a resource is indicated by an HTTP verb.
The following five HTTP verbs are commonly used (the corresponding SQL commands are in parentheses)
- GET (SELECT): Retrieves a resource (one or more) from the server.
- POST (CREATE): Creates a new resource on the server.
- PUT (UPDATE): Update a resource at the server (the client provides the complete resource after the change).
- PATCH (UPDATE): Update a resource at the server (the client provides the changed attributes).
- DELETE (DELETE): Deletes a resource from the server.
There are also two less commonly used HTTP verbs.
- HEAD: Gets the metadata of the resource.
- OPTIONS: Gets information about which properties of the resource can be changed by the client.
Here are some examples.
- GET /zoos: list all zoos
- POST /zoos: create a new zoo
- GET /zoos/ID: Get information about a specific zoo
- PUT /zoos/ID: update the information of a specified zoo (provide all the information of that zoo)
- PATCH /zoos/ID: update the information of a specified zoo (provides partial information of the zoo)
- DELETE /zoos/ID: Deletes a zoo
- GET /zoos/ID/animals: lists all animals in a given zoo
- DELETE /zoos/ID/animals/ID: Deletes a specified animal from a specified zoo
2 URLs multiplied by 4 HTTP methods is a great set of functions. Take a look at this table.
| POST (create) | GET (read) | PUT (update) | DELETE (delete) | ||
|---|---|---|---|---|---|
| /employees | Create a new employee | List all employees | Batch update employee information | Delete all employees | |
| /employees/56 | (Error) | Get information about employee #56 | Update employee #56 | Delete employee #56 |
The difference between POST and GET
There is usually confusion between POST and GET when it comes to web development, the main reason for the confusion is that basically any problem that POST can solve GET can solve, and vice versa.
GET: literally means to get resources
- GET requests are idempotent by standard (the user should think that the request is safe - the resource will not be modified, so here it should be said that the server side does not guarantee that the resource will not be modified)
- GET requests can be cached by the browser; responses can also be cached (based on cache headers)
- GET requests can be saved in the browser history and can be distributed or shared as links, and can be bookmarked
- The data of the GET request is in the URL, so it can be easily retrieved from the browser (so it cannot carry plaintext data such as passwords)
- The length of the GET request is limited (for example, the total path length for IE must be less than 2048 characters)
- The data of GET requests can only contain ASCII characters
POST: literally means posting a new resource
- POST requests are not idempotent by standard (users should consider the request as having side effects - may result in resource modification)
- POST request URLs can be cached by the browser, but POST data is not cached; responses can be cached (based on cache headers)
- POST requests are not easy to distribute or share, as POST data is lost and cannot be bookmarked.
- POST requests are not limited in length and can be used for scenarios where the “requested data” is large (as long as it does not exceed the server-side processing capacity)
- POST request data is not limited to ASCII characters and can contain binary data
The above explanation of the difference between the two may not be very well understood, idempotent (idempotent, idempotence) is actually a mathematical or computer science concept, commonly found in abstract algebra. Idempotency is expressed concretely as follows
- For monomial operations, an operation is said to be idempotent if the result of performing it multiple times for all the numbers in the range is the same as the result of performing it once. An example of this is the absolute value operation, where in the set of real numbers there is abs(a) = abs(abs(a)).
- For binomial operations, it is required that when the two values involved in the operation are equal, the operation is said to be idempotent if it satisfies the result of the operation is equal to the two values involved, such as the function to find the maximum of two numbers, i.e. max(x,x) = x.
In layman’s terms idempotent means that multiple requests for the same URL should return the same result. But it is not really very strict, for example, the front page of a news site is constantly updated. Although a second request will return a different batch of news, the operation is still considered and idempotent, since it always returns the current news. Essentially, if the goal is that when a user opens a link, he can be sure that no resources have changed from his point of view.
Early Web MVC framework designers did not consciously view and design URLs as abstract resources, so it led to a more serious problem that traditional Web MVC frameworks basically support only two HTTP methods, GET and POST, and do not support PUT and DELETE methods.
Allows overriding HTTP methods
Some proxies only support POST and GET methods, in order to use these limited methods to support the RESTful API, a way to override the original methods of http is needed.
Use the custom HTTP header X-HTTP-Method-Override to override the POST method.
Using HTTP status codes
The RESTful Web Service shall use the appropriate HTTP status code to respond to the client’s request.
- 2xx - Success - Everything is fine.
- 4xx - Client Error - If there is a failure of the client (e.g., the client sent an invalid request or was unauthorized)
- 5xx - Server error - fault on the server side (error while trying to process the request, e.g. database failure, dependent service unavailable, coding error or status that should not happen)
Note that Http status codes provide more than 70 status codes, and using all too many HTTP status codes may be confusing for API users. So you should keep using a streamlined set of HTTP status codes. Commonly used status codes are as follows.
- 2xx: Success, operation was successfully received and processed
- 200: The request was successful. Generally used for GET and POST requests
- 201: Created. The request was successful and a new resource was created
- 3xx: Redirected, further actions are required to complete the request
- 301: Permanently moved. The requested resource has been permanently moved to the new URI, the return message will include the new URI, and the browser will automatically redirect to the new URI. any future new requests should use the new URI instead
- 304: unmodified. The requested resource is unmodified and no resources will be returned when the server returns this status code. Clients typically cache accessed resources by providing a header indicating that the client expects only resources modified after the specified date to be returned
- 4xx: client error, the request contains a syntax error or the request could not be completed
- 400: Client request has a syntax error that the server cannot understand
- 401: The request requires the user’s identity
- 403: The server understood the request from the requesting client, but refused to execute the request
- 404: The server was unable to find the resource (web page) based on the client’s request. With this code, the web designer can set a personalized page with “The resource you requested could not be found”.
- 410: The resource requested by the client no longer exists. 410 is different from 404, if the resource was there before and is now permanently deleted, use the code 410, the site designer can specify the new location of the resource with the code 301
- 5xx: server error, an error occurred while the server was processing the request
- 500: internal server error, the request could not be completed
Do not overuse 404. be as precise as possible in your use of status codes. If the resource is available but access is forbidden to the user, return 403. if the resource used to exist but has been removed or deactivated, use 410.
Result filtering, sorting and searching
It is best to keep basic resource URLs as simple as possible. Complex result filters, sorting requirements, and advanced searches (when limited to a single type of resource) can be easily implemented as query parameters on top of the base URL.
Filtering Filters
Filtering using a unique query parameter.
- GET /cars?color=red Returns red cars
- GET /cars?sees<=2 Returns the set of cars with less than two seats
Alternatively, the JSON API can be used to filter.
- GET /employees?filter[state]=internal&filter[title]=senior
- GET /employees?filter[id]=1,2
Sorting sorting
Allow sorting against multiple fields
- GET /cars?sort=-manufactorer,+model
This returns a collection of cars sorted in descending order by producer and ascending order by model
Paging pagination
The two popular paging methods are.
- Offset-based paging
- Keyset-based paging, also known as continuation tokens, also known as cursors (recommended)
Offset-based paging
The general approach to paging is to use the parameters offset and limit to.
- /epics?offset=30&limit=15 # Return epics from 30 to 45
If the parameters are not filled in, the default values (offset=0, limit=100) can be used.
- /epics # Returns epics from 0 to 100
It is also possible to provide links to the previous and next pages in the response data.
Request.
- /epics?offset=30&limit=15 # Returns epics from 30 to 45
Response.
In order to send the total to the client, use the customized HTTP header: X-Total-Count.
The link to the next or previous page can be set in the Link setting of the HTTP header, following the Link setting:
|
|
Offset-based paging is simple to implement, but has two drawbacks.
- Slow query. SQL offset clause execution can be slow when there is a large amount of data.
- Insecure. Changes during paging.
Key set based paging, also known as continue tokens, also known as cursors (recommended)
Simply put, paging is done using an index column. Suppose epic has an index column data_created, we can use data_created for paging.
- GET /epics?pageSize=100 # The client accepts the top 100 epic messages, sorted using the data_created field
- GET /epics?pageSize=100&createdSince=1504224000000 # The dataCreated` field value of the oldest epic for this paging is 1504224000000 (= Sep 1, 2017 12:00:00 AM), and the client requests 100 epics data after 1504224000000.
The top epic of this paging was created on 1506816000000. this paging approach solves many of the drawbacks of offset-based paging, but is less convenient for the caller.
A better way to improve reliability and efficiency is to create a so-called continuation token by adding additional information (such as id) to the date. In addition, dedicated fields should be provided to the payload of this token so that the client does not have to look through the elements to figure it out. Even further, a link to the next page can be provided.
So a GET /epics?pageSize=100 request would return the following.
Next page links make the API truly RESTful style, as clients can view collections simply by following these links (HATEOAS). In addition, the server side can simply change the URL structure without breaking the client, ensuring the evolution of the interface.
Field selection
Mobile is able to display some of these fields, and they don’t actually need all the fields of a resource, giving API consumers the ability to select fields, which will reduce network traffic and improve API availability.
- GET /cars?fields=manufacturer,model,id,color
Search Search
Sometimes basic filtering doesn’t cut it, and that’s when you need the power of full-text search. Perhaps you are already using ElasticSearch or other search technologies based on Lucene. When full-text search is used as a mechanism to obtain a resource instance of a particular resource, it can be exposed in the API as a query parameter to the resource endpoint, which we call “q”. Search-type queries should be given directly to the search engine, and the output of the API should have the same format, with a common list as the result.
Putting these together, we can create some of the following queries:
- GET /tickets?sort=-updated_at - get the most recently updated tickets
- GET /tickets?state=closed&sort=-updated_at - Get tickets that were recently updated and have a status of closed.
- GET /tickets?q=return&state=open&sort=-priority,created_at - Get tickets with the highest priority, created first, with the status open, and with the ‘return’ character.
Bookmarker shortcuts
- Frequently used, complex queries are labeled to reduce maintenance costs.
- e.g. GET /trades?status=closed&sort=created,desc
- Shortcut: GET /trades#recently-closed
- Or: GET /trades/recently-closed
Return useful error hints
In addition to the appropriate status codes, useful error hints and detailed descriptions should be provided in the body of the HTTP response. Here is an example. Request.
- GET /employees?state=super
Response.
Error validation for PUT, PATCH and POST requests will require a field decomposition. The following is probably the best pattern: use a fixed top-level error code to validate the error and provide detailed error information in additional fields, like this:
Use friendly JSON output
JSON is better visualized and more traffic efficient than XML, so try not to use XML.
JSON-P
If there is a parameter callback in any GET request with a non-empty string value, then the interface will return data in the following format
|
|
Use small-hump nomenclature
Use the small-hump nomenclature as an attribute identifier.
|
|
Do not use underscores (year_of_birth) or big-hump nomenclature (YearOfBirth). Typically, RESTful web services will be used by clients written in JavaScript. The client will convert the JSON response to a JavaScript object (by calling var person = JSON.parse(response)) and then call its properties. Therefore, it is best to follow the JavaScript code common specification.
For comparison.
- year_of_birth // not recommended, violates the JavaScript code general specification
- yearOfBirth // Not recommended, JavaScript constructor naming
- yearOfBirth // Recommended
Null fields
The interface follows the “input is tolerant, output is strict” principle, the value of the null field in the output data structure is always null
Ensures nice printing and gzip support by default
An API that provides whitespace-compressed output is not aesthetically pleasing to view from a browser. While some ordered query parameters (such as ?pretty=true) can be provided to enable pretty printing, an API that does pretty printing by default is more approachable. The cost of additional data transfer is negligible, especially when you compare the cost of not performing gzip compression.
Consider some use cases: Suppose analyzing an API consumer is debugging and has their own code to print out the data received from the API - this should be readable by default. Or, if the consumer grabs the URL generated by their code and accesses it directly from a browser - by default this should be readable. These are the little things. Doing the little things right will make an API more enjoyable to use!
Let’s look at a practical example. I’ve pulled some data from the GitHub API, and by default this data uses pretty print. I’ll also do some GZIP compression for comparison.
The size of the output file is as follows.
- without-whitespace.txt - 1252 bytes
- with-whitespace.txt - 1369 bytes
- without-whitespace.txt.gz - 496 bytes
- with-whitespace.txt.gz - 509 bytes
In this example, spaces increase the extra output size by 8.5% when GZIP compression is not enabled, compared to 2.6% when GZIP compression is enabled. On the other hand, GZIP compression saves 60% of the bandwidth. Since the cost of pretty printing is relatively small, it is best to use pretty printing by default and make sure that GZIP compression is supported.
Rate Limiting
To prevent abuse, it is standard practice to add some type of rate limit to the API. An HTTP status code 429 too many requests is introduced in RFC 6585 to do this. You can use the token bucket algorithm technique to quantify the request limit.
In any case, it is useful to inform users of the existence of a limit before they are actually subject to it. This is an area where standards are still lacking, but there are already some popular and common ways of using HTTP response headers.
At a minimum, the following headers are included (using Twitter’s naming convention for headers, usually without capitalization of the middle word):
- X-Rate-Limit-Limit - the number of requests allowed in the current period
- X-Rate-Limit-Remaining - the number of requests remaining for the current period
- X-Rate-Limit-Ret - the number of seconds remaining in the current period
Why don’t you use timestamps instead of seconds for X-Rate-Limit-Ret?
A timestamp contains a variety of information, such as date and time zone, but they are not required. An API user really just wants to know when a request can be initiated again, and for them a second number answers that question with minimal extra processing. It also circumvents the problem of clock deviation.
Some APIs give X-Rate-Limit-Reset using UNIX timestamps (number of seconds since epoch). Don’t do this!
Why is it bad practice to use UNIX timestamps for X-Rate-Limit-Reset?
The HTTP specification already specifies to use RFC 1123 date format (currently used in date, If -Modified-Since & Last-Modified rfc2616/rfc2616-sec14.html#sec14.29) in the HTTP header information). If we intend to specify a new HTTP header that uses some form of timestamp, we should follow RFC 1123 and not use UNIX timestamps.
Caching
HTTP provides a built-in set of caching frameworks! All you have to do is include some additional outbound response headers and do a little bit of checksum work when you receive some inbound request headers.
There are two ways to do this: ETag and [Last-Modified](http://www.w3.org/Protocols/rfc2616/rfc2616-sec14.html# sec14.29)
- ETag: When a request is generated, it contains an HTTP header in which the ETag is placed with a hash or checksum value corresponding to the content of the expression. This value should change as the content of the expression changes. Now, if an inbound HTTP request contains an If-None-Match header and a matching ETag value, the API should return a 304 unmodified status code instead of the requested resource.
- Last-Modified: basically works like an ETag, except that it uses a timestamp. In the response header, Last-Modified contains a timestamp in RFC 1123 format, which uses If-Modified-Since for validation. Note that the HTTP specification already has 3 different acceptable date formats and the server should be ready to receive any of them.
Track each request with an id
Include a Request-Id header in every API response, usually with a unique identifier UUID. It is helpful to debug and track our network requests if both the server and the client print out their Request-Id.
Authentication
A RESTful API should be stateless. This means that authentication requests should not rely on cookies or sessions; instead, each request should carry some type of authentication credentials.
Since SSL is always used, authentication credentials can be reduced to a randomly generated access token passed in with a user name field using HTTP Basic Auth. The great advantage of this is that it is fully browser detectable - if the browser receives a 401 unauthorized status code from the server, it only needs a popup box to request the credentials.
However, this authentication method, based on a basic authentication token, is only available when the following scenario is met, i.e., the user can copy the token from an administrative interface to an API user environment. When this is not possible, OAuth 2 should be used to generate security tokens and pass them to third parties. OAuth 2 uses Bearer tokens and relies on SSL for the underlying transport encryption.
An API that needs to support JSONP will require a third authentication method, as JSONP requests cannot send HTTP Basic Auth credentials or Bearer tokens. In this case, a special query parameter access_token can be used. note that there is an inherent security problem with using the query parameter token, namely that most web servers log the query parameter to the service log.
It is worthwhile to note that all three methods above are just ways of passing tokens across both ends of the API boundary. The actual underlying tokens themselves may all be the same.
Token and Sign
The API needs to be designed to be stateless, so the client needs to provide a valid Token and Sign at each request, which in my opinion are used for the following purposes respectively.
- Token is used to prove the user to which the request belongs, generally the server generates a random string (UUID) after login and binds it to the logged-in user, and then returns it to the client. The other is to keep the Token alive for a fixed period of time, but return a Token for refreshing, so that when the Token expires it can be refreshed instead of logging in again.
- The Sign is used to prove that the request is reasonable, so generally the client will stitch the request parameters and encrypt them as the Sign to the server, so that even if the packet is caught, the other party only modifies the parameters but cannot generate the corresponding Sign, it will be detected by the server. Of course, the timestamp, request address and Token can also be mixed into the Sign, so that the Sign also has the owner, timeliness and destination.