ClickHouse is one of the more popular online analytical processing (OLAP) data stores recently. Compared to our common traditional relational databases such as MySQL and PostgreSQL, data stores such as ClickHouse, Hive and HBase for online analytical processing (OLAP) scenarios tend to use columnar storage.
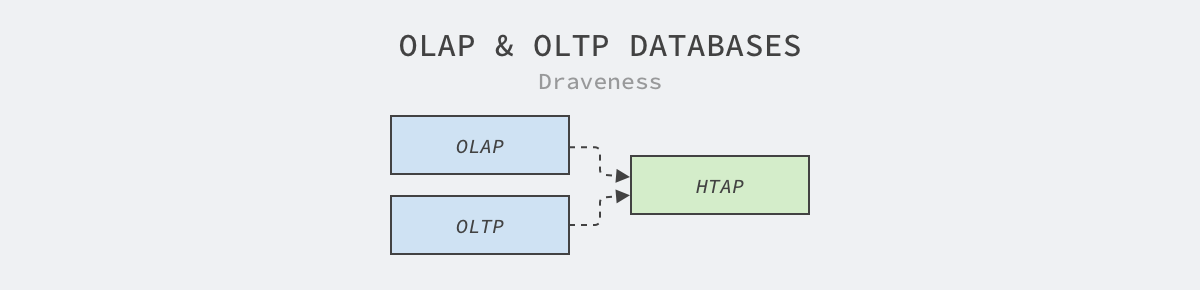
Readers who know a little about databases know that Online Transaction Processing (OLTP) and Online Analytical Processing (OLAP) are the two most common scenarios of databases, and these two scenarios are not the only two, from which there are also concepts derived from Hybrid Transactional/Analytical Processing (HTAP).
Online transaction processing is the most common scenario. Online services need to provide services for users in real time, and the process of providing services may have to query or create some records; while the scenario of online analytical processing requires batch processing of user data, and data analysts will analyze user behavior and portrait, output reports and models based on user-generated data.
The columnar storage mentioned in the title corresponds to the row storage of traditional relational database, as shown in the figure below, where row storage manages data with data rows or entities as logical units, and data rows are stored continuously, while column storage manages data with data columns as logical units, and the adjacent data are all with the same type of data.
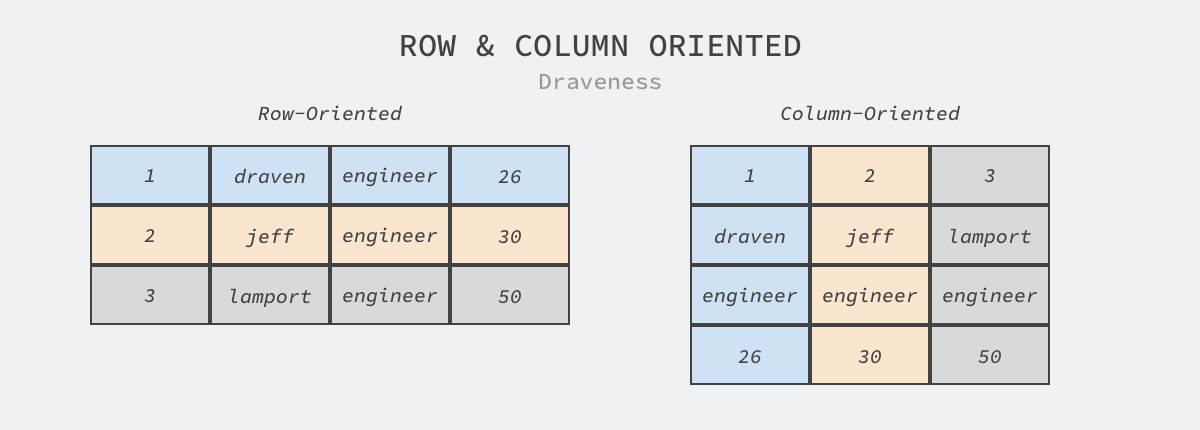
Now that we have understood the two concepts mentioned in the title: OLAP and columnar storage, we will then analyze why columnar storage is more suitable for OLAP scenarios in the following two ways.
- Columnar storage can meet the need for fast reading of specific columns, online analytical processing often requires reading specified columns in a wide table of hundreds of columns for analysis.
- Columnar storage stores data in close proximity to the same column, using compression algorithms to obtain higher compression rates and reduce the disk space occupied by storage.
Read on demand
Online services need to cope with user-initiated additions, deletions, and changes. Although the demand for queries is often several times or even dozens of times greater than the demand for write requests, the problem of responsible consistency brought about by write operations becomes a problem that online service data storage has to solve, and transactions provided by MySQL and PostgreSQL, etc. using relational databases can provide a good solution.
It is because most operations in the OLTP scenario are performed on a record-by-record basis, so it is logical to store data that is often used at the same time next to each other, but if we use databases such as MySQL for OLAP scenarios, the most common queries may also require traversing all the data in the entire table.

As shown above, when we only need to get the age distribution in the above table, we still need to read all the data in the table and discard the unneeded rows in memory, where the yellow part is the data we don’t care about, which wastes a lot of I/O and memory resources. While we can use auxiliary indexes to solve these problems, we are overwhelmed by the wide tables with tens or even hundreds of columns that are common in OLAP.
Columnar storage stores data by column, which means that when reading a specific column in a data table, we only need to find the starting location of the corresponding memory space and then read this contiguous memory space to get all the data of interest.

Even if you find a few specific columns in a large table with hundreds of columns, you don’t need to traverse the whole table, you just need to find the starting position of the column to quickly get the relevant data, reducing the waste of I/O and memory resources, which is why column-oriented storage systems are more suitable for use in OLAP scenarios.
Data Compression
Because columnar storage stores data from the same column together, using compression algorithms can get a higher compression ratio and reduce the disk space occupied by storage. The basic principle of the compression algorithm is actually quite simple, it uses a data representation of the original data based on specific rules. The string shown below contains consecutive identical characters and we can reduce the length of the string using the most intuitive compression algorithm.
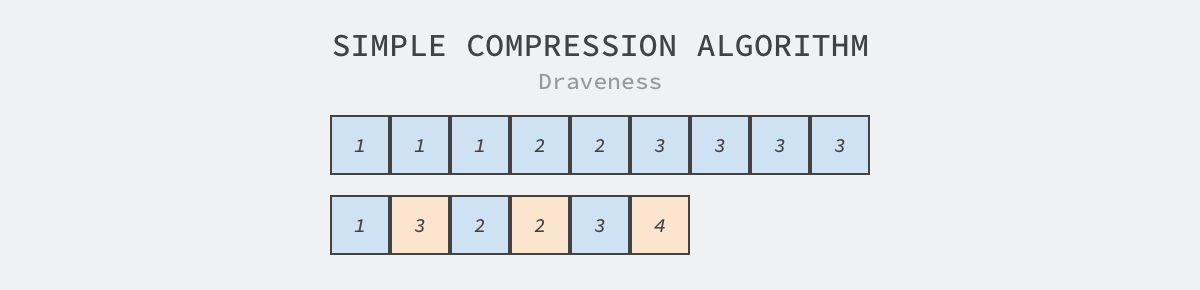
All the yellow squares in the above figure indicate the number of repetitions of the preceding string. This simple compression strategy can compress the length of the string by 33% with no loss, but the compression rate is determined by both the compression algorithm and the characteristics of the data. Compared to row-oriented data storage, column-oriented data storage stores the same type of data in close proximity, which gives more room for the compression algorithm to play.
Although compression algorithms are actually a strategy that uses CPU time in exchange for I/O time and space, in most cases, this business is a sure bet. Compression algorithms improve I/O performance by reducing data size, reducing disk seek time, reducing data transfer time, and improving buffer hit rates, and the I/O time saved can easily compensate for the additional CPU overhead it brings.
Summary
The scenario of online analytical processing has always existed, though with the evolution of the digital wave, we have only recently captured massive amounts of user data. Because past systems were unable to meet the analysis and processing needs of today’s massive data, systems designed for segmented scenarios have emerged, and column-oriented storage systems have shone in the OLAP scenario because of their following features.
- Columnar storage can meet the demand for fast reading of specific columns. Online analytical processing often requires reading specified columns in a wide table of hundreds of columns for analysis, while traditional row-based storage often requires the use of indexes or traversal of the entire table when analyzing data, which brings a very large additional overhead.
- Columnar storage stores data in close proximity to the same column, using compression algorithms to obtain higher compression rates and reduce the disk space occupied by storage, which brings additional overhead in CPU time, but saves more I/O time than the additional overhead brought about.
Columnar storage has all the advantages in the OLAP scenario, but it is not a silver bullet in data storage either, and still has many disadvantages, but we won’t discuss them here. At the end of the day, let’s look at some of the more open related issues, interested readers can think carefully about the following questions.
- What are the disadvantages of columnar storage in an OLTP scenario?
- What are the disadvantages of columnar storage in an OLTP scenario?