Memory is an important resource for computers, and while most services today do not require as much memory, databases and Hadoop services are big consumers of memory, consuming GBs and TBs of memory to speed up computations in production environments.
The Linux operating system has introduced a number of strategies to manage this memory better and faster and reduce overhead, and today we are going to introduce HugePages, or large pages.
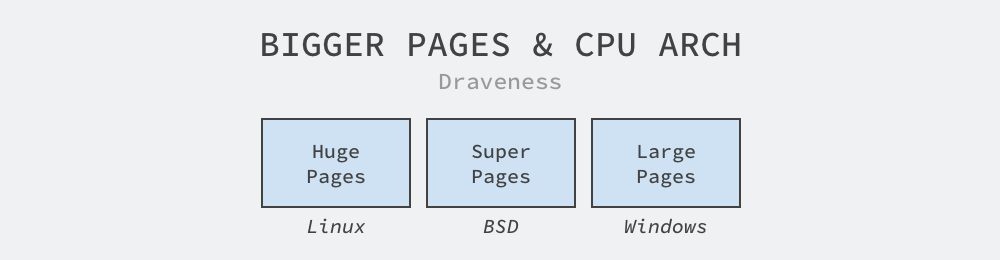
Most CPU architectures support larger pages, but different operating systems use different terms, such as HugePages on Linux, SuperPages on BSD, and LargePages on Windows, all of which represent similar large page capabilities.
We all know that Linux manages memory in pages, and the default page size is 4KB. Although some processors use 8KB, 16KB, or 64KB as the default page size, 4KB is still the dominant default page configuration for operating systems, and although a 64KB page is 16 times larger than a 4KB page, a 64KB page is not large enough compared to the minimum 2MB HugePages, let alone the default 4KB.
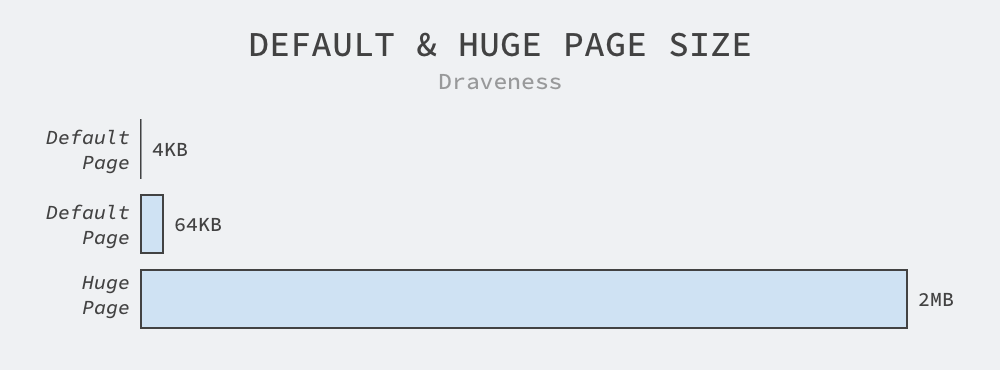
2MB is generally the default size of HugePages, and on arm64 and x86_64 architectures even large pages of 1GB are supported, which is 262,144 times the default page size of Linux, and we can view information about HugePages on the current machine using the following command.
From the above output, we can see that the default size of large pages on the current machine is 2MB and the number of large pages is also 0, i.e. no process is requesting or using large pages. You can try to execute the above command on Linux, if there is no additional configuration on the machine, then the output of the above command will not be much different from here.
The data stored in /proc/sys/vm/nr_hugepages is the number of large pages, and although by default it is always 0, we can request or release large pages from the operating system by changing the contents of this file to.
In Linux, in the same way as any other memory request and release, we can pass the MAP_HUGETLB flag to the mmap system call to request a large page of the operating system and use munmap to release the memory, using the following code snippet to request a 2MB large page in the operating system.
Although HugePages are requested in a similar way to the default memory, they are actually special resources managed separately by the operating system, and Linux displays the data about HugePages separately in /proc/meminfo.
|
|
As a new feature introduced to Linux from 2.6.32, HugePages can improve the performance of memory-intensive services such as databases and Hadoop full home buckets, which do not help much with common web services and back-end services, but may affect the performance of the services. Performance of services such as databases.
- HugePages can reduce the management overhead of in-memory pages.
- HugePages can lock memory and disable memory swapping and freeing by the operating system.
Management Overhead
While HugePages mostly require additional configuration by development or operations engineers to enable, enabling HugePages in an application can reduce the management overhead of in-memory pages in the following ways.
- Larger memory pages reduce the page table hierarchy in memory, which not only reduces the memory footprint of the page table, but also reduces the performance loss of the transition from virtual to physical memory.
- A larger memory page means a higher cache hit rate and a higher chance that the CPU can fetch the corresponding physical address directly in the TLB (Translation lookaside buffer).
- Larger memory pages reduce the number of fetches of large memory, using HugePages to fetch 2MB of memory at a time, which is 512 times more efficient than the default page of 4KB.
Because the address space of processes is virtual, the CPU and the operating system need to record the correspondence between pages and processes. The more pages in the operating system, the more time we need to spend to find the physical memory corresponding to the virtual memory in the five-level page table structure as shown below, we will access the directory (Directory) in the page table according to the virtual address in turn to finally find the corresponding physical memory.

As shown above, if we use the default 4KB memory page in Linux, the CPU needs to read PGD, PUD, PMD and PTE respectively to access the physical memory when accessing the corresponding memory, but the large 2MB memory can reduce the number of directory accesses.

Since a 2MB memory page occupies a 21-bit address, we also no longer need the PTE structure in the five-level page table, which not only reduces the number of page table accesses when translating virtual addresses, but also reduces the memory footprint of the page table.
The CPU can always find the physical page corresponding to a virtual page by using the complex directory structure described above, but it is a very expensive operation to use the above structure every time the virtual address is translated. The operating system solves this problem by using the TLB as a cache, which is a part of the Memory Management Unit where the page table entries are cached to help us quickly translate virtual addresses.

Larger memory pages mean higher cache hit rates because the TLB cache has a certain capacity and can only cache a specified number of pages, in which case caching a large 2MB page can improve the overall performance of the system by increasing the cache hit rate for the system.
In addition to fewer page table entries and improved cache hit rate, using larger pages also improves memory access efficiency. For the same 1GB of memory, a 4KB memory page requires 262,144 system processes, but a large 2MB page requires only 512 processes, which can reduce the number of system processes required to access memory by several orders of magnitude.
Locking memory
Using HugePages locks memory and disables memory swapping and freeing by the operating system. Linux provides a swap partitioning mechanism that copies a portion of memory pages from memory to disk when memory is low, freeing up memory space occupied by memory pages that are swapped back into memory when accessed by the corresponding memory process. This mechanism can create the illusion of sufficient memory for the process, but it can also cause various problems.
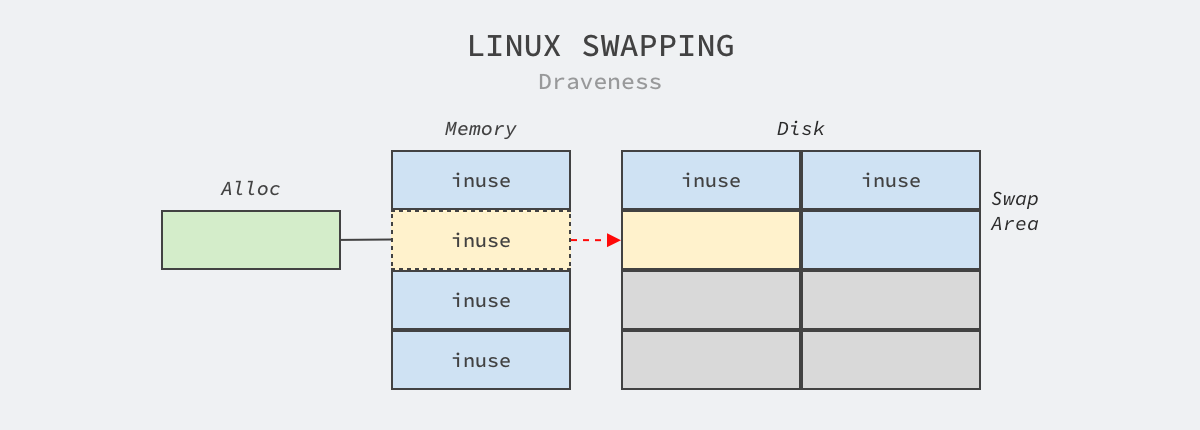
Swap may affect database performance when NUMA is enabled. Occasional swaps in the system are not unacceptable, but frequent reads and writes to disk can significantly slow down the operating system.
HugePages, unlike other memory pages, are pre-allocated by system engineers using commands on the operating system, and when processes request large pages through mmap or other system calls, they are given pre-allocated resources. HugePages in Linux are locked in memory, so even when the system runs out of memory, they are not This eliminates the possibility of important memory being swapped in and out frequently.
REHL 6 introduces Transparent Huge Pages (THP), which is an abstraction layer that automatically creates, manages, and uses large pages, hiding the complexity of large page usage for system administrators and developers, but is not recommended for databases and similar loads.
Summary
With more and more memory on a single machine and more memory consumed by services, Linux and other operating systems have introduced features like HugePages, which can improve the performance of memory-intensive services such as databases in two ways.
- HugePages can reduce the management overhead of memory pages by reducing the number of page table entries in a process, improving TLB cache hit rates and memory access efficiency.
- HugePages can lock memory, disallowing memory swaps and releases by the operating system from being swapped to disk to make way for other requests.
Although HugePages is relatively complex to manage and requires additional specific configuration by the system administrator, it can certainly serve to reduce management overhead and lock memory for specific types of workloads, thus improving system performance. In the end, let’s look at some of the more open related issues, and the interested reader can think carefully about the following questions.
- What problems can Transparent Huge Pages (THP) cause?
- What are the advantages of HugePages in a manual management system?