When installing MariaDB, I learned about TokuDB, which replaces InnoDB, and it’s great to see the introduction.
What is TokuDB?
The most popular MySQL engine that supports full transactions is INNODB, which is characterized by the fact that the data itself is organized by B-TREE, which is a huge B-TREE index clustered by primary key. So at this point, the write speed will be somewhat reduced, because to write each time to use an IO to do the index tree rearrangement. Especially when the amount of data itself is much larger than the memory, the CPU itself is too tangled up in disk IO to do anything else. At this point we have to consider how to reduce the IO to disk to relieve the CPU situation, common methods are.
- Increase the INNODB PAGE (default 16KB), but the increase also brings some defects. For example, the time to perform CHECKPOINT on disk will be delayed.
- Put the log file on a faster disk, such as an SSD.
TokuDB is a “new” transaction-enabled engine with excellent data compression, developed by TokuTek (now acquired by Percona). With excellent data compression, if you have more writes and less reads, and a large amount of data, it is highly recommended that you use TokuDB to save space costs and significantly reduce storage usage and IOPS overhead, but with a corresponding increase in CPU strain.
Features of TokuDB
1.Rich index types and fast index creation
TokuDB supports existing index types, but also adds (second) aggregate indexes to meet the diversity of queries covering indexes, and improves the efficiency of queries in terms of fast index creation
2.(Second) aggregate indexes
This type of index also contains all the columns in the table and can be used for queries that need to override indexes, such as the following example, which directly hits the index_b index in the where condition, avoiding another lookup from the primary key.
For more information, see. Introducing Multiple Clustering Indexes
3. Hot Index Creation
TokuDB allows to add indexes to tables directly without affecting the execution of update statements (insert, update, etc.). You can control whether this feature is enabled or not by the variable tokudb_create_index_online, but unfortunately it can only be created online by the CREATE INDEX syntax, not by ALTER TABLE. This is much slower than the usual creation process, which can be viewed by show processlist. However, tokudb does not support online deletion of indexes, and a global lock will be applied to the marker when the index is deleted.
4. Online column changes (Add, Delete, Expand, Rename).
TokuDB can allow the following operations with minor blocking of update or query statements.
- Adding or deleting columns in a table
- Expand fields: char, varchar, varbinary and int type columns
- Rename columns, unsupported field types: TIME, ENUM, BLOB, TINYBLOB, MEDIUMBLOB, LONGBLOB
These operations usually block (for a few seconds) the execution of other queries at table lock level, and when the table record is next loaded from disk to memory, the system will then modify the record (add, delete or expand), and in the case of rename operations, all operations will be completed within a few seconds of downtime.
The reason for the speed is probably due to the feature of the Fractal-tree index, which replaces random IO operations with sequential IO operations, and the feature of the Fractal-tree will broadcast these operations to all rows, unlike InnoDB, which needs to open table and create temporary table to complete.
Take a look at some of the official guidance on this feature:
- All of these operations are not performed immediately, but are done in the background by the Fractal Tree, including primary and non-primary key indexes. You can also force these operations manually, using the OPTIMIZE TABLE X command, TokuDB supports online completion of the OPTIMIZE TABLE command since 1.0, but it will not rebuild the indexes
- Don’t update multiple columns at once, do it separately for each column
- Avoid add, delete, expand or drop operations on a column at the same time
- The table lock time is mainly determined by the dirty pages in the cache, the more dirty pages, the longer the flush time. Every time you do an update, MySQL closes the table join to release the previous resources.
- Avoid deleting a column that is part of an index, which can be particularly slow, or remove the index from the column if you have to.
- The expand class only supports char, varchar, varbinary and int fields.
- rename one column at a time, operation on multiple columns will degrade to standard MySQL behavior, the column attributes must be specified in the syntax, as follows.
- The rename operation does not support the fields: TIME, ENUM, BLOB, TINYBLOB, MEDIUMBLOB, LONGBLOB.
- Update temporary table is not supported
5. Data compression
All compression operations in TokuDB are performed in the background, high level compression will degrade system performance, some scenarios will require high level compression. According to the official recommendation: standard compression is recommended for machines with less than 6 cores, otherwise you can use high level compression.
The compression algorithm is specified by ROW_FORMAT for each table when creating or altering the table.
ROW_FORMAT is by default controlled by the variable tokudb_row_format, which defaults to tokudb_zlib, and can have the following values:
- tokudb_zlib: uses the compression mode of the zlib library, providing a medium level of compression ratio and medium level of CPU consumption.
- tokudb_quicklz: Uses the compression mode of the quicklz library, providing a lightweight compression ratio and low basic CPU consumption.
- tokudb_lzma: Compression mode using the lzma library, providing a high compression ratio and high CPU consumption.
- tokudb_uncompressed: No compression mode is used.
Read free Replication feature
Thanks to the feature of Fractal Tree index, TokuDB’s slave side can apply changes on the master side with lower consumption than read IO, which mainly depends on the feature of Fractal Tree index and can be enabled in the configuration
- insert/delete/update operations can be partially inserted directly into the appropriate Fractal Tree index, avoiding the overhead of read-modify-write behavior;
- delete/update operations can ignore the IO overhead of uniqueness checking
The bad thing is, if the Read Free Replication feature is enabled, the Server side needs to do the following settings:
- master: the replication format must be ROW, because tokudb has not yet implemented locking for the auto-increment function, so multiple concurrent insert statements may cause uncertain auto-increment values, resulting in inconsistent data between master and slave.
- slave: turn on read-only; turn off uniqueness checking (set tokudb_rpl_unique_checks=0); turn off lookup (read-modify-write) function (set tokudb_rpl_lookup_rows=0);
The settings on the slave side can be set in one or more slave: only tables with primary keys defined in MySQL 5.5 and MariaDB 5.5 can use this feature, MySQL 5.6, Percona 5.6 and MariaDB 10.X do not have this restriction
7. Transactions, ACID and Recovery
- By default, TokuDB checks all open tables periodically and records all updates during the checkpoint, so in case of system crash, the table can be restored to its previous state (ACID-compliant), all committed transactions will be updated to the table, and uncommitted transactions will be rolled back. The default checkpoint cycle is every 60s, from the start time of the current checkpoint to the start time of the next checkpoint. If the checkpoint requires more information, the next checkpoint check will start immediately, but this is related to the frequent refresh of the log file. Users can also manually execute the flush logs command at any time to cause a checkpoint check; all open transactions are ignored during normal database shutdown.
- Manage log size: TokuDB keeps the latest checkpoing in the log file, when the log reaches 100M, a new log file will be started; each time checkpoint is made, any log older than the current checkpoint will be ignored, if the check period is set very large, the log cleaning frequency will be reduced. TokuDB also maintains a rollback log for each open transaction, the size of the log is related to the transaction volume, it is compressed and saved to disk, when the transaction ends, the rollback log will be cleaned up accordingly.
- Recovery: TokuDB automatically performs recovery operations, using logs and rollback logs to recover after a crash, recovery time is determined by the log size (including uncompressed rollback logs).
- Disable write caching: If you want to ensure transaction security, you have to consider hardware write caching. TokuDB also supports transaction safe feature in MySQL, for the system, the updated data of the database is not really written to disk, but cached, it will still lose data when the system crashes, for example, TokuDB cannot guarantee that the mounted NFS volume can be recovered properly, so if you want to be safe, it is better to So if you want to be safe, it is better to turn off write caching, but it may cause performance degradation. Normally you need to turn off the disk write cache, but for performance reasons, the XFS file system cache can be turned on, but after threading the error “Disabling barriers”, you need to turn off the cache. Some scenarios require turning off the file system (ext3) cache, LVM, soft RAID, and RAID cards with BBU (battery-backed-up) features
8. Procedure tracing.
TokuDB provides a mechanism for tracing long-running statements. For LOAD DATA command, SHOW PROCESSLIST can display process information, the first one is a status message like “Inserted about 1000000 rows”, the next one is a percentage of completion information, for example " Loading of data about 45% done"; When adding indexes, SHOW PROCESSLIST can show the process information of CREATE INDEX and ALTER TABLE, which will show the estimated number of rows, and also the percentage of completion; SHOW PROCESSLIST also shows the execution status of transactions, such as committing or aborting status.
9. Migrating to TokuDB
You can change the table storage engine in the traditional way, such as “ALTER TABLE … ENGINE = TokuDB” or mysqldump export and dump, INTO OUTFILE and LOAD DATA INFILE are also possible.
10. Hot Standby
Percona Xtrabackup does not yet support hot standby for TokuDB, Percona has also indicated that it intends to support it; for large tables you can use the LVM feature, or mysdumper. TokuDB officially provides a hot standby plugin [tokudb_backup.so](https://github.com/Tokutek/tokudb -backup-plugin), which allows online backups, but it relies on backup-enterprise and cannot compile so dynamic libraries, and is a commercial paid version, see TokuDB Installation server/5.6/tokudb/tokudb_installation.html).
Summary
Advantages of TokuDB:
- High compression ratio, using zlib for compression by default, especially for string (varchar, text, etc.) type has a very high compression ratio, more suitable for storing logs, raw data, etc.. The official claim is that it can reach 1:12.
- Add index online, does not affect the read and write operations
- HCADER features, support online field addition, deletion, extension, renaming operations, (instant or second to complete)
- Full ACID feature and transaction mechanism support
- Very fast write performance, Fractal-tree has an advantage in transaction implementation, no undo log, officially at least 9 times higher than innodb.
- Support show processlist progress view
- Data volume can scale to several terabytes.
- No index fragmentation.
- Support hot column addition,hot indexing,mvcc
TokuDB Disadvantages.
- Does not support foreign key (foreign key) function, if your table has a foreign key, this constraint will be ignored after switching to TokuDB engine.
- TokuDB is not suitable for large number of read scenarios, because of compression and decompression, CPU usage will be 2-3 times higher, but because of the small space after compression, IO overhead is low, the average response time is about 2 times.
- online ddl does not work for text, blob and other types of fields.
- No perfect hot backup tool, only logical backup by mysqldump
Applicable scenarios.
- Data that is not frequently accessed or historical data archiving
- Data tables are very large and require DDL operations from time to time
TokuDB’s Index Structure: Fractal Tree
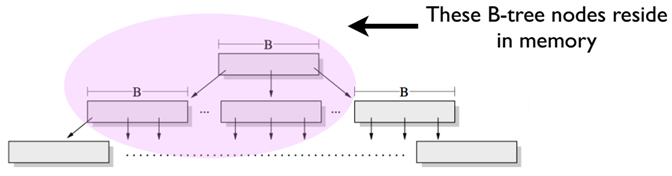
The biggest difference between TokuDB and InnoDB is that TokuDB uses an index structure called Fractal Tree, which makes it a great improvement in handling randomly written data. Currently both SQL Server and MySQL’s innodb use B+Tree (SQL Server uses standard B-Tree) index structure. innoDB is a B+Tree structure organized by primary key, and data is ordered by primary key. The difference between Fractal Tree and B-Tree mainly lies in the internal nodes of index tree, the internal structure of B-Tree index only has The internal structure of B-Tree index only has pointers to parent and child nodes, while the internal nodes of Fractal Tree not only have pointers to parent and child nodes, but also have a Buffer area. When data is written, it will first fall into this Buffer area, which is a FIFO structure, and writing is a sequential process, just like other buffers, when it is full, data will be flushed at once. So inserting data on TokuDB basically becomes a sequential adding process.
Comparison of BTree and Fractal tree.
| Structure | Inserts | Point Queries | Range Queries |
|---|---|---|---|
| B-Tree | Horrible | Good | Good (young) |
| Append | Wonderful | Horrible | Horrible |
| Fractal Tree | Good | Good | Good |
Introduction to Fractal tree
A fractal tree is a write-optimized disk index data structure. In general, the write performance of fractal tree (Insert/Update/Delete) is better, while it can ensure that the read performance of fractal tree is similar to that of B+ tree. According to Percona’s test results, TokuDB fractal tree has better write performance than InnoDB’s B+ tree), and slightly lower read performance than B+ tree.
ft-index disk storage structure
ft-index uses larger index pages and data pages (4M by default for ft-index, 16K by default for InnoDB), which makes the compression ratio of data pages and index pages higher for ft-index. In other words, with index page and data page compression on, ft-index takes less storage space when inserting the same amount of data. ft-index supports online modification of DDL (Hot Schema Change). In simple terms, users can still perform write operations while doing DDL operations (e.g. adding indexes), which is a feature naturally supported by ft-index tree structure. In addition, ft-index also supports transactions (ACID) and MVCC (Multiple Version Cocurrency Control) of transactions, and supports crash recovery. Because of the above features, Percona claims that TokuDB provides customers with significant performance improvements on the one hand, and reduces their storage costs on the other.
The index structure of ft-index is as follows.

The gray area indicates a page of the ft-index fractal tree, the green area indicates a key value, and between the two green areas indicates a son pointer. BlockNum indicates the offset of the page pointed by the son pointer, Fanout indicates the fanout of the fractal tree, i.e. the number of son pointers. NodeSize indicates the number of bytes occupied by a page. nonLeafNode indicates that the current page is a non-leaf node, LeafNode indicates that the current page is a leaf node, leaf node is the bottom node that stores Key-value key-value pairs, non-leaf node does not store value. Heigth indicates the height of the tree, the height of the root node is 3, the height of the node below the root node is 3, and the height of the node below the root node is 3. Depth denotes the depth of the tree, where the root node has depth 0 and the node next to the root node has depth 1.
The tree structure of a fractal tree is very similar to a B+ tree, which consists of several nodes (we call them Node or Block, in InnoDB, we call them Page or Page). Each node consists of an ordered set of keys. Suppose the key sequence of a node is [3, 8], then this key divides the whole interval (-00, +00) into 3 intervals (-00, 3), [3, 8), [8, +00), each of which corresponds to a son pointer (Child pointer). In a B+ tree, the Child pointer usually points to a page, while in a fractal tree, each Child pointer needs to point to a Node address (BlockNum) in addition to a Message Buffer (msg_buffer), which is a First-In-First-Out (FIFO) queue that is used to store the Insert/Disconnected messages. This Message Buffer is a FIFO queue used to hold update operations like Insert/Delete/Update/HotSchemaChange.
According to the ft-index source code implementation, a more rigorous description of the fractal tree in ft-index would be
- A node (block or node, in InnoDB we call it a Page or page) is composed of a set of ordered keys, with the first key set to a null key, indicating negative infinity.
- There are two types of nodes, one is a leaf node and the other is a non-leaf node. A leaf node’s son pointer points to a BasementNode, and a non-leaf node points to a normal Node. The BasementNode node stores multiple K-V key-value pairs, which means that all the final lookup operations need to locate the BasementNode in order to successfully retrieve the data (Value). This is also similar to the LeafPage of the B+ tree, where the data (Value) is stored in the leaf nodes and the non-leaf nodes are used to store the key values (Key) for indexing. When the leaf nodes are loaded into memory, in order to quickly find the data (Value) in the BasementNode, ft-index converts the key-value in the entire BasementNode into a weakly balanced binary tree, which has a funny name, called [scapegoat tree](https://en. wikipedia.org/wiki/Scapegoat_tree).
- The key interval of each node corresponds to a Child Pointer. The son pointer of a non-leaf node carries a MessageBuffer, and the MessageBuffer is a FIFO queue. It is used to hold update operations like Insert/Delete/Update/HotSchemaChange. The son pointer as well as the MessageBuffer are serialized and stored in the Node’s disk file.
- The number of sons of each Non Leaf Node must be within the interval [fantout/4, fantout]. Here fantout is a parameter of the fractal tree (B+ tree also has this concept), which is mainly used to maintain the height of the tree. When the number of sons of a non-leaf node is less than fantout/4, the node is considered too empty and needs to be merged with other nodes to form a single node (Node Merge), which reduces the height of the tree. When the number of son pointers of a non-leaf node exceeds fantout, then we consider the node too full and need to split a node into two (Node Split). By controlling this constraint, we can theoretically maintain the disk data in a normal and relatively balanced tree structure, which can control the upper limit of insertion and query complexity.
- Note: In ft-index implementation, the conditions to control the tree balance are more complicated, for example, in addition to considering the fantout, we also need to ensure that the total number of bytes of nodes is in the interval of [NodeSize/4, NodeSize], which is generally 4M, and when it is not in this interval, we need to do the corresponding Merge or Split operation.
Insert/Delete/Update Implementation of Fractal Trees
We said that fractal tree is a write-optimized data structure, and its write performance is better than that of B+ tree. So how exactly does it achieve better write performance? First, by write performance, we mean random write operations. For a simple example, suppose we execute this SQL statement continuously in MySQL InnoDB table: insert into sbtest set x = uuid(), where there is a unique index field x in sbtest table. Due to the randomness of uuid(), the data inserted into sbtest table will be scattered in different leaf nodes (Leaf Node). In the B+ tree, a large number of such random write operations will result in a large number of hot data pages in the LRU-Cache falling in the upper level of the B+ tree (as shown in the figure below). This reduces the probability of the leaf nodes at the bottom hitting the Cache, resulting in a large number of disk IO operations, and thus a bottleneck in the random write performance of the B+ tree. However, the sequential write operation of the B+ tree is very fast because it makes full use of the local hotspots and the number of disk IO operations is greatly reduced.
Here is the flow of the fractal tree insertion operation. To facilitate the description later, the convention is as follows.
- Take Insert operation as an example, assuming that the inserted data is (Key, Value)
- Only when the cache is not hit, ft-index will read the data page into memory by seed locating the offset.
- Crash logging and transaction processing are not considered for now.
The detailed flow is as follows.
- load the Root node.
- determine whether the Root node needs to be split (or merged), and if the split (or merge) condition is met, split (or merge) the Root node. The specific process of splitting Root nodes, interested students can open their minds.
- When Root node height>0, i.e. Root is a non-leaf node, the key-value range where Key is located is found by dichotomous search, and (Key, Value) is wrapped into a message (Insert, Key, Value) and put into the Message of the Child pointer corresponding to the key-value range. Buffer. 4.
- When Root node height=0, i.e. Root is a leaf node, the message (Insert, Key, Value) is applied to the BasementNode, i.e. inserted into the BasementNode.
Here is a very strange place, in the case of a large number of insertions (including random and sequential insertions), the Root node will be regularly filled up, which will lead to a large number of splits in the Root node. Then, after the Root node does a lot of splitting, a lot of nodes with height=1 are created, and after the nodes with height=1 are full, a lot of nodes with height=2 are created, and finally the tree height gets higher and higher. The secret of the high performance of fractal tree write operations compared to B+ trees is hidden in this weirdness: each insertion operation lands on the Root node and returns immediately, and each write operation does not need to search the BasementNode at the bottom of the tree structure, which leads to a large amount of hot data concentrated in the upper layer of the Root node (the distribution of hot data is similar to the above figure), thus The localization of hot data is fully utilized, which greatly reduces disk IO operations.
The case of Update/Delete operation is similar to that of Insert operation, but the special point to note is that the random read performance of fractal tree is not as good as InnoDB’s B+ tree. Therefore, the Update/Delete operation needs to be subdivided into two cases, and the performance difference between these two tests can be huge.
- Overwrite Update/Delete (overwrite). That is, when the key exists, Update/Delete is performed; when the key does not exist, no operation is done and no error is reported.
- Strictly matching Update/Delete. When the key exists, update/delete is executed; when the key does not exist, an error is reported to the upper application. In this case, we need to check whether the key exists in the basementnode of ft-index first, so Point-Query silently drags the performance of Update/Delete operations backwards.
In addition, ft-index does some optimizations for sequential insert operations in order to improve the performance of sequential writes, such as Sequential Write Acceleration.
Point-Query implementation of fractal tree
In ft-index, a query like select from table where id = ? (where id is the index) is called a Point-Query; a query operation like select from table where id >= ? and id <= ? (where id is the index) is called Range-Query. As mentioned above, Point-Query read operations do not perform as well as InnoDB’s B+ tree, so here is a detailed description of the Point-Query process. (The key value to be queried is assumed to be Key here)
- Load the Root node and determine the Range of the key value range of the Root node by dichotomous search, and find the Child pointer of the corresponding Range.
- Load the node corresponding to the Child pointer. If the node is a non-leaf node, continue to search down the fractal tree until it stops at the leaf node. If the current node is a leaf node, then stop the search.
After finding a leaf node, we do not directly return the Value of the BasementNode in the leaf node to the user. Because the insertion operation of fractal tree is inserted by way of Message, we need to apply all the messages on the path from Root node to leaf node to the BasementNode of leaf node in turn. After all the messages are applied, the value corresponding to the key in the BasementNode is the value that the user needs to find. The user needs to find the value.
The lookup process of fractal tree is basically similar to the lookup process of InnoDB’s B+ tree, the difference is that the fractal tree needs to push down the messge buffer on the path from Root node to the leaf node and apply the message to the BasementNode. Note that the lookup process needs to push down the messages, which may cause some nodes on the path to be full, but ft-index does not split and merge the leaf nodes during the query process, because the design principle of ft-index is: Insert/Update/Delete operations are responsible for splitting and merging the nodes, Select operations are responsible for delaying the pushing down of the messages (the “merge” operation). is responsible for the Lazy Push of messages. In this way, the fractal tree applies Insert/Delete/Update operations to specific data nodes through future Select operations to complete the update.
Range-Query implementation for fractal trees
The following section describes the implementation of Range-Query. In simple terms, Range-Query for a fractal tree is basically equivalent to performing N Point-Query operations, and the cost of the operation is basically equivalent to the cost of N Point-Query operations. Since the fractal tree stores the update operation of the BasementNode in the msg_buffer of the non-leaf node, we need to look up the Value of each Key from the root node to the leaf node, and then apply the message on this path to the Value of the BasementNode. This process can be represented by the following diagram.
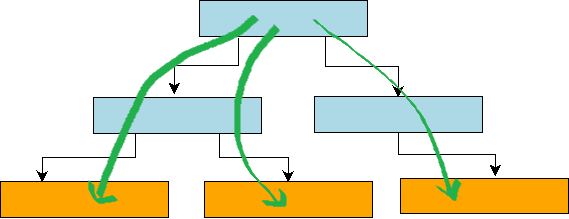
However, in the B+ tree, the underlying leaf nodes are organized into a bidirectional chain table by pointers, as shown in the figure below. Therefore, we only need to locate the first Key that satisfies the condition from the heel node to the leaf node, and then iterate the next pointer at the leaf node to obtain all the Key-Value keys of the Range-Query. Therefore, for the B+ tree Range-Query operation, except for the first traversal from the root node to the leaf nodes to do random write operations, the subsequent data reads can basically be regarded as sequential IO.
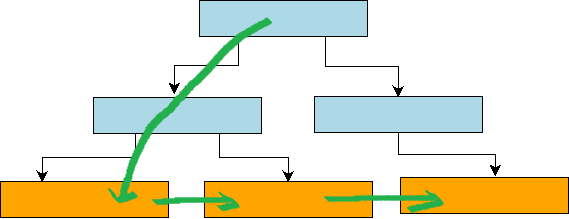
By comparing the Range-Query implementation of the fractal tree and the B+ tree, we can see that the Range-Query query cost of the fractal tree is significantly higher than that of the B+ tree, because the fractal tree needs to traverse the entire subtree of the Root node covering Range, while the B+ tree only needs to Seed to the starting Key of Range once, and the subsequent iterations are basically equivalent to sequential IO.
Summary
Overall, fractal tree is a write optimized data structure, its core idea is to make full use of the MessageBuffer cache of nodes to update operations, and make full use of the data locality principle to convert random writes to sequential writes, which greatly improves the efficiency of random writes. iiBench test results of Tokutek R&D team show that: the performance of TokuDB’s insert operation (random write) is much faster than InnoDB, while the performance of Select operation (random read) is lower than InnoDB’s performance, but the difference is smaller. This is the reason why Percona claims that TokuDB is higher performance and lower cost.
In addition, the online update table structure (Hot Schema Change) implementation is also based on MessageBuffer, but the difference with Insert/Delete/Update operation is that the former message push down is broadcast push down (a message from the parent node is applied to all son nodes), and the latter message push down is unicast push down (a message from the parent node is applied to the son nodes of the corresponding key value interval), because the implementation is similar to Insert operation, so I will not expand the description.
Multiple Version Concurrency Control (MVCC) for TokuDB
In traditional relational databases (e.g. Oracle, MySQL, SQLServer), transactions are arguably the most central element of development and discussion. And the most core nature of transaction is ACID.
- A denotes atomicity, which means that all subtasks that make up a transaction have only two outcomes: either all subtasks are successfully executed as the transaction is committed, or all subtasks are undone as the transaction is rolled back.
- C denotes consistency, which means that no matter the transaction commits or rolls back, it cannot break the consistency constraints on the data. These consistency constraints include key-value uniqueness constraints, key-value association relationship constraints, and so on.
- I denotes isolation, isolation is generally for multiple concurrent transactions, that is, at the same point in time, t1 transaction and t2 transaction read data should be isolated, these two transactions are like into the same hotel two rooms, each in their own room inside the activity, they can not see each other what each is doing.
- D means persistence, this nature ensures that once a transaction commits to the user successfully, then even if the succeeding database process crashes or the operating system crashes, as long as the disk data is not broken, then the execution result of the transaction can still be read after the next database start.
TokuDB currently fully supports ACID for transactions. From the implementation point of view, since TokuDB uses fractal tree as index, while InnoDB uses B+ tree as index structure, thus TokuDB is very different from InnoDB in the implementation of transactions.
In InnoDB, two kinds of logs are designed, redo and undo. redo stores the physical modification log of the page, which is used to ensure the persistence of the transaction; undo stores the logical modification log of the transaction, which actually stores multiple versions of a record under multiple concurrent transactions, and is used to realize the isolation of the transaction (MVCC) and rollback operation. Since TokuDB’s fractal tree uses message passing to do add, delete, change and update operations, a message is a version of the record modified by the transaction, therefore, there is no additional concept and implementation of undo-log in the TokuDB source code implementation, instead, there is a management mechanism of multiple messages for a record. Although the multiple messages per record approach can achieve transaction MVCC, it cannot solve the problem of transaction rollback, so TokuDB has designed the additional tokudb.rollback log file to help achieve transaction rollback.
Here we mainly analyze the implementation of TokuDB’s transaction isolation, which is often referred to as Multiple Version Concurrency Control (MVCC).
TokuDB Transaction representation
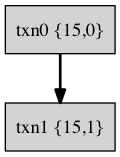
In tokudb, a transaction executed by a user is broken up into many smaller transactions at the storage engine level (such smaller transactions are denoted as txn). For example, a user executes a transaction such as
The log in the redo-log corresponding to the TokuDB storage engine is
|
|
The corresponding transaction tree is shown in the following figure.
For a more complex example of a transaction with a savepoint.
The corresponding redo-log records are
|
|
This transaction forms a transaction tree as follows:

In tokudb, a binary group like {parent_id, child_id} is used to record the dependencies of a txn and other txn. This way, a set of numbers from the root transaction to the leaf points can uniquely identify a txn, and this list of numbers is called xids, which I think can also be called transaction numbers. For example, xids for txn3 = {17, 2, 3 } , xids for txn2 = {17, 2}, xids for txn1 = {17, 1}, and xids for txn0 = {17, 0}.
So for each operation in a transaction (xbegin/xcommit/enq_insert/xprepare), there is an xids to identify the transaction number where this operation is located. Each message (insert/delete/update message) in TokuDB carries such an xids transaction number. This xids transaction number plays a very important role in the TokuDB implementation, and the functionality associated with it is particularly complex.
Transaction Manager
The Transaction Manager is used to manage the set of all transactions for the TokuDB storage engine.
- Active transaction list. The list of active transactions only records the root transaction, because the root transaction is actually the basis for finding all child transactions of the entire transaction tree. This transaction list holds all the root transactions that have started at this point in time but have not yet ended.
- The list of snapshot read transactions.
- A list of references to active transactions (referred_xids). This concept is not easy to understand. Suppose an active transaction starts (xbegin) at the time of begin_id and commits (xcommit) at the time of end_id. then referenced_xids is a binary that maintains (begin_id, end_id). the use of this binary is to find all active transactions of a transaction’s The use of this binary is to find all active transactions in the entire life cycle of a transaction, which is mainly used to do the full gc operation mentioned later.
Fractal tree LeafEntry
As mentioned above in the tree structure of the fractal tree, when doing operations like insert/delete/update, all messages from root to leaf are applied to the LeafNode node. In order to describe the apply process in detail later, we first introduce the storage structure of LeafNode.
A leafNode simply consists of multiple leafEntry, each leafEntry is a key-value pair {k, v1, v2, … }, where v1, v2 … denote multiple versions of a value corresponding to a key. The structure of a key corresponding to a leafEntry is detailed in the following figure.

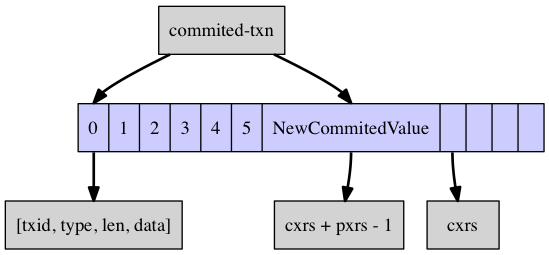
From the above figure, a leafEntry is actually a stack, and the bottom of the stack [0~5] represents the value of the transaction that has been committed (commited transaction). The top of the stack [6~9] represents the active transaction (uncommited transaction) that has not yet been committed. The single element in the stack is a quadruplet of (txid, type, len, data), which indicates the value of the transaction. More generally, the stack of [0, cxrs-1] represents committed transactions, which should not exist on the stack, but exist because other transactions refer to them by snapshot read. -1] of this stack will not be reclaimed unless all transactions referencing [0, cxrs-1] are committed. The [cxrs, cxrs+pxrs-1] segment of the stack represents the list of currently active uncommitted transactions. When this segment commits, cxrs will move backwards and eventually to the top of the stack.
MVCC Implementation
- Write operations
Here we consider three types of write operations, insert / delete / commit. For the two types of write operations, insert and delete, you only need to place an element at the top of the stack of LeafEntry. The following figure shows.
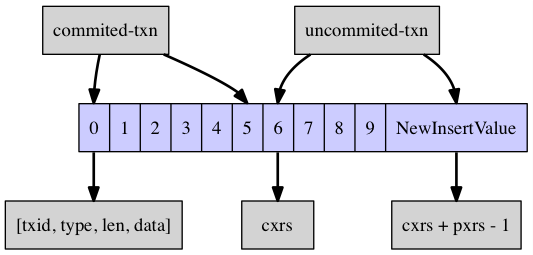
For commit operation, just put the top element of the stack of LeafEntry at the pointer cxrs, and then shrink the top pointer of the stack. The following figure shows.
- Read Operations
MySQL InnoDB supports Read UnCommitted (RU), Read REPEATABLE (RR), Read Commited (RC), SERIALIZABLE (S). Among them, RU has dirty reads (dirty reads refer to reading uncommitted transactions), RC/RR/RU have phantom reads (phantom reads generally refer to a transaction may update records that have already been committed by other transactions when updating).
TokuDB also supports the above 4 isolation levels, in the source code implementation, ft-index divides the transaction read operations into 3 categories according to the transaction isolation level:
- TXN_SNAPSHOT_NONE : This category does not require snapshot read, SERIALIZABLE and Read Uncommited belong to this category.
- TXN_SNAPSHOT_ROOT : The Read REPEATABLE isolation level belongs to this category. In this case, it means that the transaction only needs to read records that have been committed before the xid corresponding to the root transaction.
- TXN_SNAPSHOT_CHILD: READ COMMITTED belongs to this category. In this case, the son transaction A needs to find the snapshot read version according to the xid of its own transaction, because when this transaction A is opened, there may be other transaction B did the update and committed, then transaction A must read the result after the update of B.
Multi-version record recycling
As time goes by, more and more old transactions are committed and new transactions start to execute. The number of commited transactions in the LeafNode in the fractal tree will increase, and if we don’t find a way to clean up these expired transaction records, it will cause the BasementNode nodes to occupy a lot of space, and also cause the TokuDB data files to store a lot of useless data. In TokuDB, the operation of cleaning up these expired transactions is called Garbage Collection. In fact, InnoDB also has such a process as recycling expired transactions, multiple versions of InnoDB’s Value of the same Key are stored on the undo log page, when the transaction expires, there is a purge thread in the background dedicated to complex cleanup of these expired transactions, thus freeing up the undo log page for later transactions. This can control the infinite growth of undo log.
TokuDB storage engine does not have a purge thread similar to InnoDB to clean up the expired transactions, because the expired transactions are cleaned up by GC during the update operation. In other words, when Insert/Delete/Update operations are executed, it will determine whether the current LeafEntry satisfies the GC condition, and if it does, it will delete the expired transactions in the LeafEntry and reorganize the memory space of the LeafEntry. According to the TokuDB source code implementation, there are two types of GCs.
- Simple GC: Every time a message is applied to a LeafEntry, it carries a gc_info, which contains the oldest_referenced_xid field. So what is the meaning of simple_gc? simple_gc is to do a simple GC, directly clean up the list of commited transactions (remember to leave a commited transaction record, otherwise how to find this commited record next time? ). This is simple_gc, simple, violent and efficient.
- Full GC: The trigger conditions and gc process of full gc are more complicated, but the basic intention is to clean up the expired committed transactions. Here is not to expand.
Summary
This article introduces the isolation principle of TokuDB transactions, including the transaction representation of TokuDB, the structure of LeafEntry of fractal tree, the implementation process of MVCC, and the multi-version record recovery method. TokuDB does not have undo log because the update message in the fractal tree itself records the version of the transaction record. In addition, TokuDB does not need to open a background thread to recycle expired transactions asynchronously as InnoDB does, but only during the execution of update operations. In short, since TokuDB implements transactions on top of fractal tree, there are big differences in all aspects of thinking, which is the innovation of TokuDB team, I think.
Reference.