What is a hash ?
Hash is the transformation of an input of arbitrary length (also called pre-image) into an output of fixed length by a hashing algorithm, and that output is the hash value. This transformation is a compressed mapping, i.e., the space for the hash value is usually much smaller than the space for the input, and different inputs may be hashed into the same output, and it is not possible to uniquely determine the input value from the hash value.
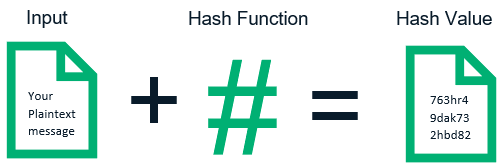
The mathematical expression is: h = H(M) , where H()-one way hash function, M-any length plaintext, and h-fixed length hash value.
Hash algorithms applied in the field of information security also need to satisfy other key properties.
- one-way, the hash value can be obtained simply and quickly from the pre-map, and it is computationally impossible to construct a pre-map such that the hash result is equal to a particular hash value, i.e., it is not feasible to construct the corresponding M=H-1(h). In this way, the hash value is a statistically unique representation of the input value, hence the cryptographic Hash, also known as “message digest”, which requires that the “message” can be conveniently “digest”, but it is not possible to get more information about the “message” in the “digest” than in the “digest” itself. information than the summary itself.
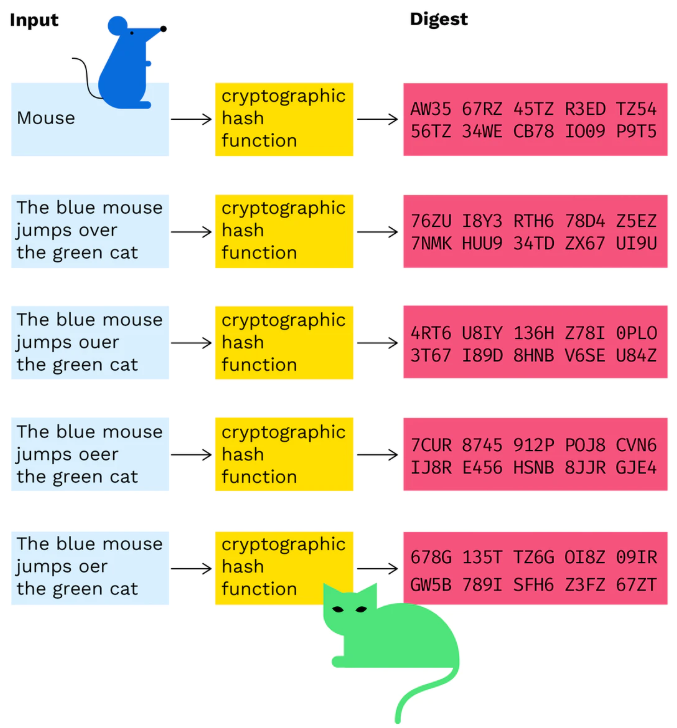
- collision-resistant , i.e., it is statistically impossible to generate 2 pre-maps with the same hash value. Given M, it is computationally impossible to find M’ that satisfies H(M)=H(M’), which is weakly conflict-resistant; it is also computationally difficult to find an arbitrary pair of M and M’ that satisfies H(M)=H(M’), which is strongly conflict-resistant. The requirement of “strong conflict resistance” is mainly to prevent the so-called “birthday attack”, in a group of 10 people, the probability that you can find someone with the same birthday as you is 4%, while in the same group, there are 2 The probability of having the same birthday in the same group is 7%. Similarly, when the pre-mapping space is large, the algorithm must be strong enough to ensure that people with the “same birthday” cannot be found easily. Uniformity of mapping distribution and uniformity of difference distribution, the total number of bits of 0 and 1 in the hash result should be approximately equal; a change of one bit in the input will change more than half of the bits in the hash result, which is also called “avalanche effect “To achieve a 1-bit change in the hash result, at least half of the bits in the input must be changed. The essence is that each bit of information in the input must be reflected as evenly as possible in each bit of the output; each bit of the output is the result of the combined effect of as many bits of information as possible in the input.
Damgard and Merkle defined the so-called “compression function”, which transforms a fixed-length input into a shorter fixed-length output, and this has had a significant impact on the design of Hash functions in cryptographic practice. The Hash function is designed to be based on the process of “compressing” the input group and the result of the previous compression process through a specific compression function repeatedly until the entire message is compressed, with the final output being the hash of the entire message. Although a rigorous proof is lacking, the vast majority of researchers in the industry agree that if the compression function is safe, then it will be safe to hash a message of arbitrary length in the form described above.
The difference between Hash and Encrypt
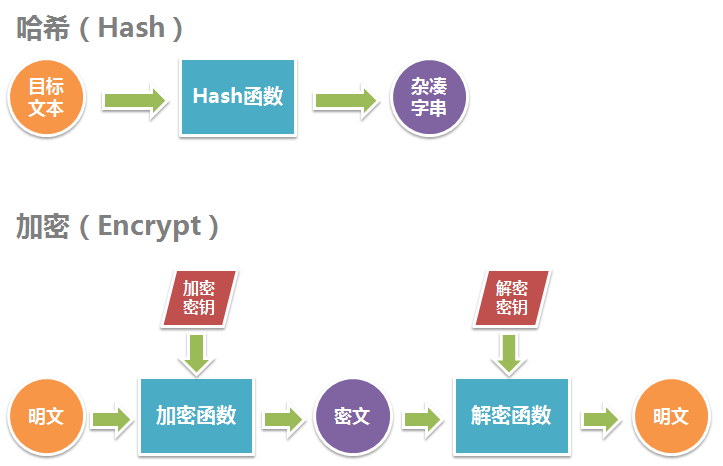
To summarize, Hash converts the target text into an irreversible hashed string (or message digest) of the same length, while Encrypt converts the target text into a reversible cipher text of a different length.
Mathematically speaking, both hashing and encryption are a mapping. Both are formally defined as follows.
- A hashing algorithm R = H(S) is a many-to-one mapping, where given a target text S, H can uniquely map it to R, and for all S, R has the same length. Since it is a many-to-one mapping, there is no inverse mapping S=H-1(R) for H such that R is converted to a unique S.
- An encryption algorithm R=E(S,KE) is a one-to-one mapping, where the second parameter is called the encryption key, and E can uniquely map a given plaintext S to a ciphertext R in combination with the encryption key KE, and there exists another one-to-one mapping S=D(R,KD) that can uniquely map a ciphertext R to a corresponding plaintext S in combination with KD, where KD is called the decryption key.
The following diagram illustrates the hashing and encryption process.
Application of Hash function
Error correction
Using a hash function it is intuitive to detect errors that occur when data is being transmitted. On the sender side of the data, a hash function is applied to the data to be sent and the result of the calculation is sent with the original data. On the receiving side, the same hash function is applied again to the received data, and if the results of the two hash functions are not the same, then there is an error somewhere in the data transmission process. This is called redundancy checksum.
Speech recognition
For applications like matching an MP3 file from a known list, one possible solution would be to use a traditional hash function - such as MD5 - but such a solution would be very sensitive to time shifts, CD read errors, different audio compression algorithms or volume adjustment implementation mechanisms. Using something like MD5 is good for quickly finding audio files that are strictly identical (in terms of the binary data of the audio file), but finding audio files that are all identical (in terms of the content of the audio file) would require the use of other, more advanced algorithms.
Information Security
The application of Hash algorithm in information security is mainly in the following 3 areas.
File checksum
We are familiar with the parity check algorithm and CRC check, these two checks do not have the ability to resist data tampering, they can detect and correct the channel error in data transmission to a certain extent, but can not prevent the malicious destruction of data. The “digital fingerprint” feature of MD5 Hash makes it one of the most widely used Checksum algorithms for file integrity.
Digital Signatures
Hash algorithms are also an important part of modern cryptographic systems. The one-way hash function plays an important role in digital signature protocols because of the slow speed of asymmetric algorithms. Digitally signing a Hash value, also known as a “digital digest”, can be considered statistically equivalent to digitally signing the document itself. And there are other advantages to such a protocol.
Forensic Protocols
Authentication protocols are also known as challenge-authentication models: a simple and secure method when the transmission channel is listenable, but not tamperable.
Introduction to Common Hash Functions
MD5 and SHA1 are arguably the most widely used Hash algorithms, and they are both designed on the basis of MD4.
- MD4 (RFC 1320) was designed by Ronald L. Rivest of MIT in 1990, and MD stands for Message Digest. It is suitable for high-speed software implementation on a 32-bit word length processor - it is based on bit manipulation of 32-bit operands.
- MD5 (RFC 1321) is an improved version of MD4 by Rivest in 1991. MD5 is more complex and slower than MD4, but is more secure and better at resisting analysis and differencing.
- SHA1 was designed by the NIST NSA for use with DSA and produces a 160-bit hash for inputs less than 264 in length, so it is more brute-force resistant. SHA-1 was designed based on the same principles as MD4 and mimics that algorithm.
Modernizing the Hash Algorithm
Jenkins Hash
In 1997 Bob Jenkins published an article on hash functions in the Dr. Dobbs Journal [“A hash function for hash table lookup”](http://www. burtleburtle.net/bob/hash/doobs.html), which since its publication now has more extensions online. In this article, Bob included a wide range of existing hash functions, including his own so-called “lookup2”. Then in 2006, Bob released lookup3, which is widely used because it is fast (0.5 bytes/cycle, as Bob claims) and has no serious flaws. lookup3 is the Jenkins Hash. more For more on Bob’s hash function see Wikipedia: Jenkins hash function. memcached’s hash algorithm, which supports two Algorithms: jenkins, murmur3, default is jenkins.
MurmurHash
Austin Appleby released a new hash function in 2008: MurmurHash. Its latest version is about twice as fast as lookup3 (about 1 byte/cycle), and it is available in both 32-bit and 64-bit versions. The 32-bit version uses only 32-bit math functions and gives a 32-bit hash, while the 64-bit version uses 64-bit math functions and gives a 64-bit hash. According to Austin’s analysis, MurmurHash has excellent performance, although Bob Jenkins claimed in Dr. Dobbs article that “I predict MurmurHash to be weaker than lookup3, but I don’t know the exact value because I haven’t tested it”. “MurmurHash is rapidly gaining popularity thanks to its excellent speed and statistical properties. The current version is MurmurHash3, which is used by Redis, Memcached, Cassandra, HBase, and Lucene.
CityHash
CityHash is a string hashing algorithm released by Google in 2011, which, like murmurhash, is a non-cryptographic hash algorithm. The development of the CityHash algorithm was inspired by MurmurHash. Its main advantage is that most of the steps contain at least two independent mathematical operations. Google wanted to optimize for speed rather than simplicity, so it did not take care of the special case of shorter inputs. two algorithms were released by Google: cityhash64 and cityhash128. they compute They compute 64 and 128 bit hashes based on the string. The speed of cityHash depends on the CRC32 instruction and is currently SSE 4.2 (Intel Nehalem and later).
SpookyHash
In 2011 Bob Jenkins released a new hash function of his own, SpookyHash (so named because it was released on Halloween). They both have 2x the speed of MurmurHash, but they both use only 64-bit math functions and no 32-bit version, SpookyHash gives 128-bit output.
FramHash
In 2014 Google released FarmHash, a new family of hash functions for strings. FarmHash inherits many tricks and techniques from CityHash and is its successor. farmHash has multiple goals and claims to improve on CityHash in several ways. Another improvement of FarmHash over CityHash is that it provides an interface on top of several platform-specific implementations. This allows FarmHash to meet the requirements when developers simply want a fast and robust hash function for hash tables that does not need to be the same on every platform. Currently, FarmHash only includes hash functions for byte arrays on 32-, 64-, and 128-bit platforms. Future development plans include support for integers, tuples, and other data.
Other Hash Algorithms
XXHash: https://github.com/Cyan4973/xxHash
SuperFastHash: http://www.azillionmonkeys.com/qed/hash.html
Which Hash function should I use?
Of course, the later release may be better in terms of functionality, but there may be some kind of limitation. For 32-bit machines, it is recommended to use MurmurHash, which is a bit faster than lookup3’s 32-bit.