In the process of learning Python, I have come across knowledge points related to multi-threaded programming, which I have not been able to understand thoroughly before. Today I’m going to spend some time to sort out the details as clearly as possible.
The difference between threads and processes
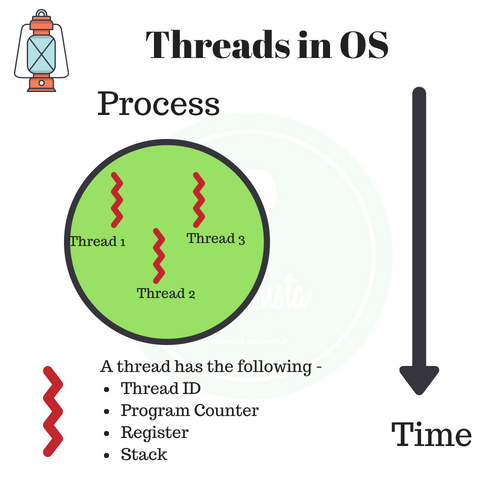
Processes (process) and threads (thread) are basic operating system concepts, but they are rather abstract and not easy to grasp. The most classic textbook quote about multiple processes and threads is " Processes are the smallest unit of resource allocation, threads are the smallest unit of CPU scheduling". A thread is a single sequential control process in a program. A relatively independent, schedulable unit of execution within a process is the basic unit of the system for independent scheduling and CPU assignment refers to the scheduling unit of a running program. Running multiple threads simultaneously in a single program to accomplish different tasks is called multithreading.
Difference between processes and threads
A process is the basic unit of resource allocation. All the resources associated with that process are recorded in the process control block PCB to indicate that the process owns these resources or is using them. In addition, the process is also the scheduling unit of the preemptive processor, which has a complete virtual address space. When scheduling of processes occurs, different processes have different virtual address spaces, while different threads within the same process share the same address space.
In contrast to a process, a thread is independent of resource allocation; it belongs to a particular process and shares the process’s resources with other threads within the process. A thread consists of only the associated stack (system stack or user stack) registers and the thread control table TCB. Registers can be used to store local variables within a thread, but not variables related to other threads.
Usually several threads can be included in a process, and they can take advantage of the resources available to the process. In operating systems that introduce threads, processes are usually used as the basic unit for allocating resources, while threads are used as the basic unit for independent operation and independent scheduling. Since threads are smaller than processes and basically do not own system resources, they can be scheduled with much less overhead and can increase the degree of concurrent execution between multiple programs in the system more efficiently, thus significantly improving the utilization of system resources and throughput. As a result, general-purpose operating systems introduced in recent years have introduced threads to further improve the concurrency of the system and consider it as an important indicator of modern operating systems.
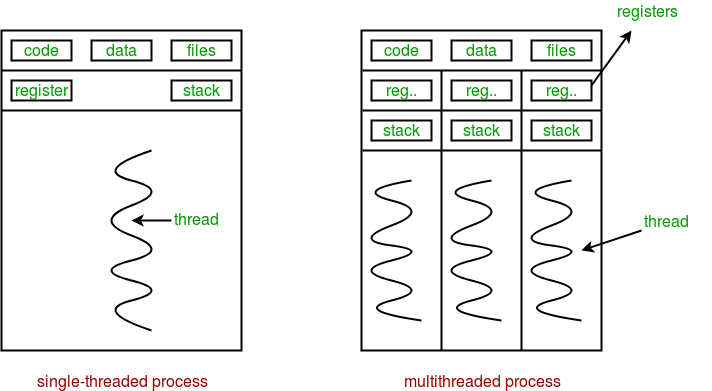
The difference between threads and processes can be summarized in the following 4 points.
- Address space and other resources (such as open files): processes are independent of each other and are shared between threads of the same process. Threads within a process are not visible to other processes.
- Communication: Inter-process communication IPC, threads can communicate with each other by directly reading and writing process data segments (e.g. global variables) - the assistance of process synchronization and mutual exclusion means is needed to ensure data consistency.
- Scheduling and switching: thread context switching is much faster than process context switching.
- In a multi-threaded OS, a process is not an executable entity.
Comparison of multi-process and multi-thread
| Comparison Dimension | Multiprocess | Multi-thread | Summary |
|---|---|---|---|
| Data sharing, synchronization | Complex data sharing, simple synchronization | Simple data sharing, complex synchronization | Each has advantages and disadvantages |
| memory, CPU | memory consumption, complex switching, low CPU utilization | memory consumption, simple switching, high CPU utilization | thread dominance |
| create, destroy, switch | complex, slow | simple, fast | threads take precedence |
| Programming, debugging | Simple to program, simple to debug | Complex to program, complex to debug | Process dominance |
| reliability | processes don’t affect each other | one thread hang will cause the whole process to hang | process dominance |
| distributed | for multi-core, multi-machine, scaling to multiple machines simple | for multi-core | process dominance |
To summarize, processes and threads can also be analogized to trains and carriages: the
- A thread travels under a process (a mere carriage cannot run)
- A process can contain multiple threads (a train can have multiple cars)
- It is difficult to share data between different processes (it is difficult for a passenger on one train to switch to another train, e.g., a station change)
- It is easy to share data between different threads under the same process (it is easy to change from carriage A to carriage B)
- Processes consume more computer resources than threads (using multiple trains is more resource-intensive than multiple cars)
- Processes do not affect each other, a thread hang will cause the whole process to hang (one train will not affect another train, but if a car in the middle of a train catches fire, it will affect all cars of that train)
- Processes can be expanded to multiple machines, and processes are suitable for up to multiple cores (different trains can drive on multiple tracks, and cars of the same train cannot be on different tracks of travel)
- Memory addresses used by processes can be locked, i.e. when a thread uses some shared memory, other threads must wait for it to finish before they can use that piece of memory. (e.g. bathroom on a train) - “Mutual exclusion lock (mutex)”
- The memory address used by a process can be limited in usage (e.g. a restaurant on a train, where only a maximum number of people are allowed to enter, and if it is full you need to wait at the door and wait for someone to come out before you can enter) - “semaphore”
Python Global Interpreter Lock GIL
Global Interpreter Lock (English: GIL), is not a Python feature, it is a concept introduced in the implementation of the Python parser (CPython). Since CPython is the default Python execution environment in most environments. So in many people’s conception CPython is Python, and they take it for granted that GIL is a defect of the Python language. So what is the GIL in the CPython implementation? Let’s look at the official explanation.
The mechanism used by the CPython interpreter to assure that only one thread executes Python bytecode at a time. This simplifies the CPython implementation by making the object model (including critical built-in types such as dict) implicitly safe against concurrent access. Locking the entire interpreter makes it easier for the interpreter to be multi-threaded, at the expense of much of the parallelism afforded by multi-processor machines.
The execution of Python code is controlled by the Python virtual machine (also called the interpreter main loop, in the CPython version), which was designed from the beginning with the idea that there would be only one thread executing at the same time in the interpreter’s main loop, i.e., only one thread running in the interpreter at any given moment. Access to the Python virtual machine is controlled by the Global Interpreter Lock (GIL), and it is this lock that ensures that only one thread is running at the same time.
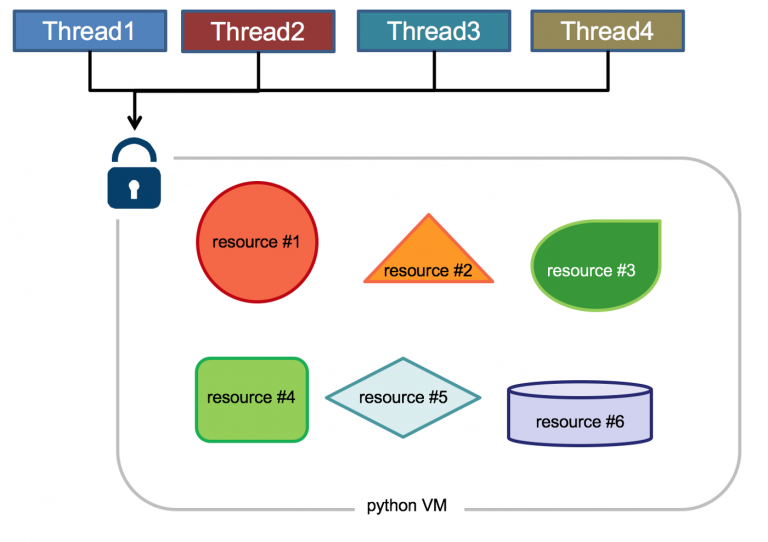
What are the benefits of GIL? Simply put, it’s faster in single-threaded situations and easier to use when combined with C libraries and without thread safety concerns, which was the most common application scenario and advantage of early Python. In addition, the design of GIL simplifies the CPython implementation by making the object model, including key built-in types such as dictionaries, implicitly accessible concurrently. Locking the global interpreter makes it relatively easy to implement support for multiple threads, but also loses the parallel computing power of multiprocessor hosts.
In a multi-threaded environment, the Python virtual machine performs as follows.
- set the GIL
- switch to a thread to run
- run until the specified number of bytecode instructions are completed, or the thread actively relinquishes control (either by calling sleep(0))
- set the thread to sleep
- unlock the GIL
- repeat all the above steps again
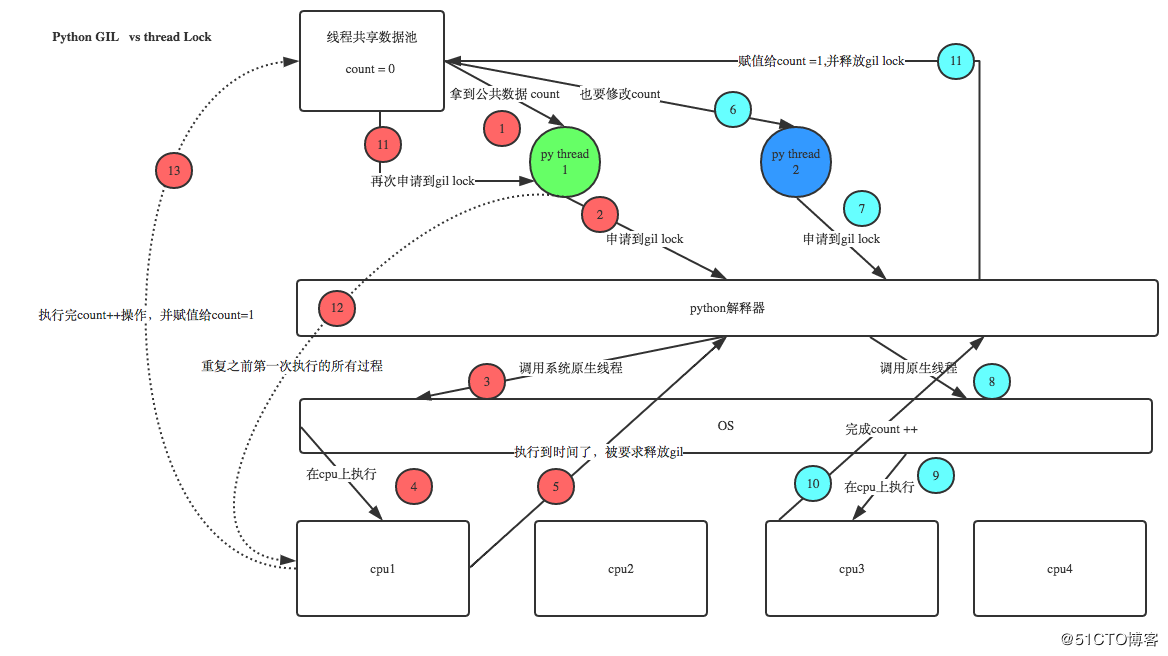
Before Python 3.2, the logic for releasing a GIL was to release it when the current thread encountered an IO operation or when the ticks count reached 100 (ticks can be thought of as python’s own counter that is used specifically for GILs and is reset to zero after each release, which can be adjusted via sys.setcheckinterval). Because a compute-intensive thread will request a GIL immediately after releasing it, and usually reacquire it before other threads have finished scheduling, once a compute-intensive thread has acquired a GIL, it will occupy it for a long time, even until the end of the thread’s execution.
Python 3.2 started using the new GIL, which uses a fixed timeout to instruct the current thread to relinquish the global lock. When the current thread holds the lock and another thread requests it, the current thread is forced to release the lock after 5 milliseconds. This improvement is better for single-core cases where a single thread occupies the GIL for a long time.
On single-core CPUs, it takes hundreds of interval checks to cause a thread switch. On multicore CPUs, there are severe thread bumps (thrashing). And each time the GIL lock is released, threads compete for locks and switch threads, which consumes resources. Under single-core multi-threading, every time the GIL is released, the thread that wakes up gets the GIL lock, so it can execute seamlessly, but under multi-core, after CPU0 releases the GIL, the threads on other CPUs will compete, but the GIL may be immediately obtained by CPU0 again, so the threads on other CPUs that are woken up will be awake and wait until the switchover time and then enter the pending scheduling state, which will cause thread bumps (thrashing), resulting in even lower efficiency.
In addition, it can be deduced from the implementation mechanism above that Python’s multithreading is more friendly to IO-intensive code than CPU-intensive code.
Countermeasures for GIL.
- Use a higher version of Python (optimized for the GIL mechanism)
- Use multi-processes instead of multi-threads (no GIL between multi-processes, but the processes themselves consume more resources)
- Specify cpu to run threads (using affinity module)
- Use GIL-free interpreters like Jython, IronPython, etc.
- Use multithreading only for fully IO-intensive tasks
- Use concurrent threads (efficient single-threaded mode, also called micro-threading; usually used with multi-processes)
- Write key components in C/C++ as Python extensions, and make Python programs directly call exported functions from C-compiled dynamic link libraries via ctypes. (with nogil to call out GIL restrictions)
Python’s multiprocessing package multiprocessing
Python’s threading package is mainly used for multi-threaded development, but due to GIL, multi-threading in Python is not really multi-threaded. If you want to use the full resources of a multi-core CPU, you need to use multi-processing in most cases. The multiprocessing package was introduced in Python version 2.6, and it replicates the complete set of interfaces provided by threading for easy migration. The only difference is that it uses multiple processes instead of multiple threads. Each process has its own independent GIL, so there is no GIL contention between processes.
With multiprocessing, you can easily make the transition from single process to concurrent execution. multiprocessing supports subprocesses, communication and shared data, performs different forms of synchronization, and provides components such as Process, Queue, Pipe, Lock, etc.
Background of the creation of Multiprocessing
In addition to dealing with Python’s GIL, another reason for multiprocessing is the inconsistency between the Windows operating system and the Linux/Unix system.
Unix/Linux operating systems provide a fork() system call, which is very special. A normal function is called once and returns once, but fork() is called once and returns twice, because the OS automatically makes a copy of the current process (parent) and then returns it in the parent and child processes respectively. The reason for this is that a parent process can fork many child processes, so the parent process has to write down the ID of each child process, and the child process only has to call getpid() to get the ID of the parent process.
Python’s os module encapsulates common system calls, including fork, that make it easy to create child processes in Python programs.
The above code executes on Linux, Unix and Mac with the following results.
With a fork call, a process can copy out a child process to handle a new task when it receives a new task. A common Apache server has a parent process listening on the port and forks out a child process to handle a new http request whenever there is a new http request.
Since Windows does not have fork calls, the above code will not work on Windows. Since Python is cross-platform, it is natural to provide a cross-platform multiprocessing support. multiprocessing module is a cross-platform version of multiprocessing module. multiprocessing module wraps the fork() call so that we don’t need to focus on the details of fork(). Since Windows does not have a fork call, multiprocessing needs to “emulate” the effect of fork.
Multiprocessing common components and functions
Create management process module.
- Process (for creating processes)
- Pool (for creating a pool of managed processes)
- Queue (for process communication, resource sharing)
- Value, Array (for process communication, resource sharing)
- Pipe (for pipe communication)
- Manager (for resource sharing)
Synchronized sub-process modules.
- Condition (condition variable)
- Event
- Lock (mutually exclusive lock)
- RLock (reentrant mutually exclusive lock (the same process can get it multiple times without causing blocking))
- Semaphore (semaphore)
Next, let’s learn how to use each component and function together.
Process (for creating processes)
The multiprocessing module provides a Process class to represent a process object.
In multiprocessing, each process is represented by a Process class.
Constructor: Process([group [, target [, name [, args [, kwargs]]]]])
- group: grouping, not actually used, value is always None
- target: the target of the call, i.e. the task to be performed by the child process, you can pass in the method name
- name: set the name for the child process
- args: positional arguments to be passed to the target function, passed as a tuple.
- kwargs: the dictionary parameter to be passed to the target function, passed as a dictionary.
Instance methods.
- start(): start the process and call p.run() in this subprocess.
- run(): the method that runs when the process starts, it is it that calls the function specified by target, we must implement this method in the class of our custom class
- terminate(): force the termination of the process p, will not perform any cleanup operations, if p created a child process, the child process will become a zombie process, the use of this method need to be particularly careful of this situation. If p still has a lock, it will not be released, which will lead to deadlock.
- is_alive(): Returns whether the process is running. If p is still running, return True
- join([timeout]): process synchronization, the main process waits for the child process to finish before executing the code that follows. The thread waits for p to terminate (emphasis: the main thread is in the wait state, while p is in the run state). timeout is an optional timeout (after this time, the parent thread no longer waits for the child thread and continues to execute), it should be emphasized that p.join can only join the process started by start, but not the process started by run
Properties
- daemon: the default value is False, if set to True, it means p is a daemon running in the background; when p’s parent process terminates, p will also terminate, and after setting to True, p cannot create its own new process; must be set before p.start()
- name: the name of the process
- pid: the pid of the process
- exitcode: the process is None at runtime, if it is -N, it means it is terminated by signal N (understand it)
- authkey: the authentication key of the process, the default is a 32-character string randomly generated by os.urandom(). The purpose of this key is to provide security for the underlying inter-process communication involving network connections, which can only succeed if they have the same authentication key (just understand)
Example usage: (Note: in windows Process() must be put under if __name__ == '__main__':)
|
|
Pool (for creating managed process pools)

Pool class is used when there are many targets to be executed and it is too cumbersome to limit the number of processes manually, or Process class can be used if there are few targets and the number of processes is not to be controlled. If the pool is not full, a new process is created to execute the request; however, if the number of processes in the pool has reached the specified maximum, the request waits until a process in the pool finishes, and then the processes in the pool are reused.
Constructor: Pool([processes[, initializer[, initargs[, maxtasksperchild[, context]]]]])
- processes : The number of processes to be created, if omitted, the number returned by cpu_count() will be used by default.
- initializer : The callable object to be executed when each worker process starts, defaults to None. if initializer is None, then each worker process will call initializer(*initargs) at the beginning.
- initargs: is the set of arguments to be passed to the initializer.
- maxtasksperchild: The number of tasks that can be completed before the worker process exits, replacing the original process with a new one after completion to allow idle resources to be freed. maxtasksperchild is None by default, meaning that the worker process will remain alive as long as the Pool exists.
- context: Used to set the context in which the worker process will start. Generally a pool is created using Pool() or the Pool() method of a context object, both of which set the context appropriately.
Instance methods.
- apply(func[, args[, kwargs]]): Execute func(args,*kwargs) in a pool process, and return the result. It should be emphasized that this operation does not execute the func function concurrently in all pool processes. To execute the func function concurrently with different arguments, you must call the p.apply() function from different threads or use p.apply_async(). It is blocking. apply is rarely used
- apply_async(func[, arg[, kwds={}[, callback=None]]]): Execute func(args,*kwargs) in a pool worker process and return the result. The result of this method is an instance of the AsyncResult class, and callback is the callable object that receives the input parameters. When the result of func becomes available, the understanding is passed to callback. callback prohibits any blocking operation, otherwise it will receive the result from other asynchronous operations. It is non-blocking.
- map(func, iterable[, chunksize=None]): The map method in the Pool class, which behaves essentially the same as the built-in map function usage, causes the process to block until the result is returned. Note that although the second argument is an iterator, in practice, the program must have the entire queue ready before the subprocess will run.
- map_async(func, iterable[, chunksize=None]): map_async has the same relationship to map as apply and apply_async
- imap(): The difference between imap and map is that map is when all processes have been executed and the result is returned, imap() returns an iterable iterable object immediately.
- imap_unordered(): The order of the returned results is not guaranteed to be the same as the order in which the processes are added.
- close(): closes the process pool to prevent further operations. If all operations hang continuously, they will complete before the working process terminates.
- join(): Wait for all working processes to exit. This method can only be called after close() or terminate(), so that it does not accept new Processes.
- terminate(): Ends the working process and does not process any more unprocessed tasks.
The return values of the methods apply_async() and map_async() are instances of AsyncResul obj. Instances have the following methods.
- get(): returns the result and waits for it to arrive if necessary. timeout is optional. If it has not arrived within the specified time, an exception will be thrown. If an exception is raised in a remote operation, it will be raised again when this method is called.
- ready(): Returns True if the call is completed.
- successful(): Returns True if the call completes and no exception is raised, or raises an exception if the method is called before the result is ready.
- wait([timeout]): wait for the result to become available.
- terminate(): terminates all working processes immediately, while not performing any cleanup or ending any pending work. This function will be called automatically if p is garbage collected
Usage examples.
|
|
|
|
Queue (for process communication, resource sharing)
When using Multiprocessing, it is better not to use shared resources. Normal global variables cannot be shared by child processes, only data structures constructed by Multiprocessing components can be shared.
Queue is a class used to create a queue for sharing resources between processes. Using Queue can achieve the function of data transfer between multiple processes (disadvantage: it is only applicable to Process class and cannot be used in Pool process pool).
Constructor: Queue([maxsize])
- maxsize is the maximum number of items allowed in the queue, omitted, there is no size limit.
Instance methods.
- If blocked is True (the default) and timeout is positive, the method blocks for the time specified by timeout until there is space left in the queue. If it times out, a Queue.Full exception will be thrown. If blocked is False, but the Queue is full, a Queue.Full exception is thrown immediately.
- If blocked is True (the default) and timeout is positive, then no element is fetched within the wait time and a Queue.Empty exception is thrown. If blocked is False, two cases exist, if the Queue has a value available, that value is returned immediately, otherwise, if the queue is empty, a Queue.Empty exception is thrown immediately. If you don’t want to throw an exception when empty, just make blocked True or set all parameters to null.
- get_nowait(): same as q.get(False)
- put_nowait(): same as q.put(False)
- empty(): Returns True if q is empty when this method is called. This result is not reliable, for example, if items are added to the queue in the process of returning True.
- full(): Returns True if q is full when this method is called. This result is unreliable, for example, if an item is taken from the queue in the process of returning True.
- qsize(): Returns the correct number of items currently in the queue. The result is also unreliable for the same reason as q.empty() and q.full()
Usage examples.
|
|
JoinableQueue is like a Queue object, but the queue allows the user of the item to notify the generator that the item has been successfully processed. The notification process is implemented using shared signals and condition variables.
Constructor: JoinableQueue([maxsize])
- maxsize: the maximum number of items allowed in the queue, omitted for no size limit.
Instance Methods
The instance p of JoinableQueue has, in addition to the same methods as the Queue object.
- task_done(): the user uses this method to signal that the returned items from q.get() have been processed. If the number of calls to this method is greater than the number of items removed from the queue, a ValueError exception will be raised
- join(): The producer calls this method to block until all items in the queue have been processed. The blocking will continue until every item in the queue calls the q.task_done() method
Usage examples.
|
|
Value, Array (for process communication, resource sharing)
The implementation principle of Value and Array in multiprocessing is to create ctypes() objects in shared memory to achieve the purpose of sharing data, the two implementations are similar, just choose different ctypes data type.
Value
Constructor: Value((typecode_or_type, args[, lock])
- typecode_or_type: Define the type of the ctypes() object, you can pass Type code or C Type, see below for the comparison table.
- args: arguments passed to the typecode_or_type constructor
- lock: default is True, creates a mutually exclusive lock to restrict access to the Value object, if passed a lock, such as an instance of Lock or RLock, will be used for synchronization. If False is passed, the instance of Value will not be protected by a lock and it will not be process safe.
Types supported by typecode_or_type.
|
|
Reference address: https://docs.python.org/3/library/array.html
Array
Constructor: Array(typecode_or_type, size_or_initializer, **kwds[, lock])
- typecode_or_type: same as above
- size_or_initializer: if it is an integer, then it determines the length of the array and the array will be initialized to zero. Otherwise, size_or_initializer is the sequence used to initialize the array and its length determines the length of the array.
- kwds: argument passed to the typecode_or_type constructor
- lock: same as above
Usage examples.
|
|
Note: Value and Array are only available for the Process class.
Pipe (for pipe communication)
Pipe can create a pipe between processes and return a tuple (conn1,conn2), where conn1 and conn2 represent the connection objects at both ends of the pipe, emphasizing the point that the pipe must be created before the Process object is created.
Construct method: Pipe([dumplex])
- dumplex: the default pipe is full duplex, if duplex is shot to False, conn1 can only be used for receiving, conn2 can only be used for sending.
Instance methods.
- send(obj): sends an object through a connection. obj is any object compatible with serialization
- recv(): receive the object sent by conn2.send(obj). If there is no message to receive, the recv method will always block. If the other end of the connection is already closed, the recv method throws an EOFError.
- close(): closes the connection. This method will be called automatically if conn1 is garbage collected
- fileno(): return the integer file descriptor used by the connection
- poll([timeout]):Returns True if data is available on the connection. timeout specifies the maximum time to wait. If this parameter is omitted, the method will return the result immediately. If timeout is shot to None, the operation will wait indefinitely for data to arrive.
- recv_bytes([maxlength]):Receives a full byte message sent by the c.send_bytes() method. maxlength specifies the maximum number of bytes to receive. If the incoming message, exceeds this maximum, an IOError exception will be raised and no further reading will be possible on the connection. If the other end of the connection is closed and no more data exists, an EOFError exception will be raised.
- send_bytes(buffer [, offset [, size]]): sends a buffer of byte data over the connection. buffer is any object that supports the buffer interface, offset is the byte offset in the buffer, and size is the number of bytes to be sent. The resultant data is sent as a single message and then received by calling the c.recv_bytes() function
- recv_bytes_into(buffer [, offset]): receives a full byte message and stores it in a buffer object, which supports a writable buffer interface (i.e. bytearray object or similar). offset specifies the byte shift in the buffer where the message is placed. The return value is the number of bytes received. If the message length is greater than the available buffer space, a BufferTooShort exception is thrown.
Usage examples.
|
|
Manager (for resource sharing)
The manager object returned by manager() controls a server process, which contains python objects that can be accessed by other processes through proxies. The Manager module is often used together with the Pool module.
The types supported by Manager are list,dict,Namespace,Lock,RLock,Semaphore,BoundedSemaphore,Condition,Event,Queue,Value and Array.
Managers are independently running subprocesses in which real objects exist and run as servers, and other processes access shared objects by using proxies that run as clients. manager() is a subclass of BaseManager and returns a started instance of SyncManager() that can be used to create shared objects and return proxies that access those shared objects and return proxies that access those shared objects.
BaseManager , the base class for creating the Manager server
Constructor: BaseManager([address[, authkey]])
- address: (hostname, port), specify the URL of the server, default is simply assign a free port
- authkey: authentication of the client connected to the server, default is the value of current_process().authkey
Instance methods.
- start([initializer[, initargs]]): start a separate child process and start the manager server in that child process
- get_server(): get the server object
- connect(): connect to the manager object
- shutdown(): shutdown the manager object, can only be called after the start() method is called
Instance properties.
- address: read-only property, the address being used by the manager server
SyncManager, The following types are not process-safe and require locking…
Instance methods.
- Array(self,*args,**kwds)
- BoundedSemaphore(self,*args,**kwds)
- Condition(self,*args,**kwds)
- Event(self,*args,**kwds)
- JoinableQueue(self,*args,**kwds)
- Lock(self,*args,**kwds)
- Namespace(self,*args,**kwds)
- Pool(self,*args,**kwds)
- Queue(self,*args,**kwds)
- RLock(self,*args,**kwds)
- Semaphore(self,*args,**kwds)
- Value(self,*args,**kwds)
- dict(self,*args,**kwds)
- list(self,*args,**kwds)
Example usage.
|
|
Synchronize subprocess modules
Lock (Mutual Exclusion Lock)
Locking locks are used to avoid access conflicts when multiple processes need to access a shared resource. Locking ensures that when multiple processes modify the same piece of data, only one modification can be made at the same time, i.e., serially, sacrificing speed but ensuring data security. lock contains two states - locked and non-locked - and two basic methods.
Construct method: Lock()
Instance methods.
- acquire([timeout]): Puts the thread into a synchronous blocking state to try to acquire the lock.
- release(): Releases the lock. The thread must have acquired the lock before using it, otherwise an exception will be thrown.
Usage examples.
RLock (reentrant mutex lock (the same process can get it multiple times without causing blocking)
RLock (reentrant lock) is a synchronization instruction that can be requested multiple times by the same thread. rlock uses the concepts of “owned thread” and “recursive hierarchy”. The thread that owns the RLock can call acquire() again and release() the same number of times when releasing the lock. Think of RLock as containing a lock pool and a counter with an initial value of 0. Each successful call to acquire()/release() will result in a counter of +1/-1, and 0 when the lock is in an unlocked state.
Construct method: RLock()
Instance methods.
- acquire([timeout]): same as Lock
- release(): same as Lock
Semaphore (signal volume)
A semaphore is a more advanced locking mechanism. A semaphore has an internal counter unlike a lock object that has an internal lock identifier, and a thread blocks only when the number of threads occupying the semaphore exceeds the semaphore. This allows multiple threads to access the same code area at the same time. For example, if the toilet has 3 pits, then only 3 people are allowed to go to the toilet at most, and the people behind can only wait for someone to come out inside before they can go in again. If the specified semaphore is 3, then one person gets a lock, the count is added to 1, and when the count is equal to 3, everyone behind needs to wait. Once released, someone can get a lock.
Constructor: Semaphore([value])
- value: set semaphore, default value is 1
Instance methods.
- acquire([timeout]): same as Lock
- release(): same as Lock
Usage examples.
|
|
Condition (condition variable)
Condition maintains an internal lock object (RLock by default), which can be passed as an argument when creating a Condigtion object. Condition also provides acquire, release methods, the meaning of which is the same as the lock acquire, release methods, in fact, it simply calls the corresponding method of the internal lock object. condition also provides some other methods.
Constructor: Condition([lock/rlock])
- You can pass a Lock/RLock instance to the constructor method, otherwise it will generate a RLock instance by itself.
Instance methods.
- acquire([timeout]): first do acquire, then judge some conditions. If the condition is not met then wait
- release(): release Lock
- wait([timeout]): Calling this method will cause the thread to enter the Condition’s waiting pool to wait for notification and release the lock. The thread must have acquired the lock before using it, otherwise an exception will be thrown. The thread in the wait state will re-determine the condition when it is notified.
- notify(): Calling this method will pick a thread from the wait pool and notify it. The thread that receives the notification will automatically call acquire() to try to get the lock (enter the lock pool); the other threads remain in the wait pool. Calling this method will not release the lock. The thread must have acquired the lock before using it, otherwise an exception will be thrown.
- notifyAll(): Calling this method will notify all threads in the waiting pool that they will all enter the locking pool to try to obtain a lock. Calling this method will not release the lock. The threads must have acquired the lock before using it, otherwise an exception will be thrown.
Usage examples.
|
|
Event
Event contains an internal flag bit, which is initially false. set() can be used to set it to true, or clear() can be used to set it to false again. is_set() can be used to check the status of the flag bit. The other most important function is wait(timeout=None), which is used to block the current thread until the internal flag of event is set to true or timeout is timed out. If the internal flag is true, then the wait() function understands the return.
Usage examples.
|
|
Other content
Difference between multiprocessing.dummy module and multiprocessing module: dummy module is multi-threaded, while multiprocessing is multi-processed, api are common. It is easy to switch code between multi-threaded and multi-processing. multiprocessing.dummy can usually be tried in an IO scenario, for example, by introducing a pool of threads in the following way.
from multiprocessing.dummy import Pool as ThreadPool
The difference between multiprocessing.dummy and the earlier threading seems to be that only one core is bound under a multi-core CPU (not verified).
Reference documentation.
- https://docs.python.org/3/library/multiprocessing.html
- https://www.rddoc.com/doc/Python/3.6.0/zh/library/multiprocessing/
Python Concurrency of concurrent.futures
The Python standard library provides us with threading and multiprocessing modules to write the corresponding multi-threaded/multi-processing code. Starting with Python 3.2, the standard library provides us with the concurrent.futures module, which provides two classes, ThreadPoolExecutor and ProcessPoolExecutor, that implement a higher level abstraction of threading and multiprocessing, and are useful for writing ThreadPool/ProcessPool provides direct support for writing thread pools/process pools. The concurrent.futures base modules are executor and future.
Executor
Executor is an abstract class, which cannot be used directly. It defines some basic methods for concrete asynchronous execution. ThreadPoolExecutor and ProcessPoolExecutor inherit from Executor and are used to create the code for thread pools and process pools respectively.
ThreadPoolExecutor object
The ThreadPoolExecutor class is a subclass of Executor that performs asynchronous calls using a thread pool.
|
|
Execute asynchronous calls using a pool of threads with max_workers number.
ProcessPoolExecutor object
The ThreadPoolExecutor class is a subclass of Executor that performs asynchronous calls using a pool of processes.
|
|
Execute asynchronous calls using a pool of processes with max_workers number, or the number of processors of the machine if max_workers is None (e.g. 4 processes are used for asynchronous concurrency when max_worker is configured for a 4-core machine).
submit() method
The submit() method is defined in Executor. The purpose of this method is to submit an executable callback task and return a future instance. future object represents the given call.
Executor.submit(fn, *args, **kwargs)
- fn: the function to be executed asynchronously
- *args, **kwargs: fn arguments
Usage examples.
map() method
In addition to submit, Exectuor also provides us with the map method, which returns a map(func, *iterables) iterator in which the callback execution returns an ordered result.
Executor.map(func, *iterables, timeout=None)
- func: function that needs to be executed asynchronously
- *iterables: iterable objects, such as lists, etc. Each time func is executed, it takes arguments from iterables.
- timeout: Set the timeout for each asynchronous operation. The value of timeout can be int or float. If the operation times out, raisesTimeoutError will be returned; if the timeout parameter is not specified, no timeout is set.
Usage examples.
shutdown() method
Free system resources, called after asynchronous operations such as Executor.submit() or Executor.map(). Use the with statement to avoid calling this method explicitly.
Executor.shutdown(wait=True)
Future
A future can be understood as an operation that will be completed in the future, which is the basis of asynchronous programming. Usually, when we perform io operations and access the url (below) blocking occurs until the result is returned and the cpu can’t do anything else, and the introduction of Future helps us to complete other operations during this time of waiting.
The Future class encapsulates callable asynchronous execution. future instances are created via the Executor.submit() method.
- cancel(): attempts to cancel the call. The method returns False if the call is currently executing and cannot be canceled, otherwise the call is canceled and the method returns True.
- cancelled(): Returns True if the call is successfully cancelled.
- running(): Returns True if the call is currently executing and cannot be canceled.
- done(): Returns True if the call was successfully canceled or finished.
- result(timeout=None): Returns the value returned by the call. If the call has not completed, then this method will wait for the timeout seconds. TimeoutError will be reported if the call does not complete within the timeout seconds. timeout can be a plastic or floating point value, if timeout is not specified or is None, the wait time is infinite. CancelledError will be reported if the futures is cancelled before completion.
- exception(timeout=None): Returns the exception thrown by the call, if the call has not completed, the method will wait for the timeout specified, if the call has not completed after that timeout, a timeout error will be reported futures. If timeout is not specified or is None, the wait time is infinite. CancelledError will be raised if the futures is cancelled before it completes. If the call completes and no exception is raised, return None.
- add_done_callback(fn): Bind a callable fn to a future. When the future is cancelled or finished, the fn will be called as the only argument to the future. If the future has finished running or is cancelled, fn will be called immediately.
- wait(fs, timeout=None, return_when=ALL_COMPLETED)
- Wait for the Future instance (possibly created by different Executor instances) provided by fs to finish running. Returns a named 2-tuple collection, with a sub-table representing completed and unfinished
- return_when indicates when the function should return. Its value must be one of the following.
- FIRST_COMPLETED :The function returns when any future ends or is cancelled.
- FIRST_EXCEPTION : The function returns when any future ends due to an exception, which is equal to if no future reports an error.
- ALL_COMPLETED : The function returns when all futures are finished.
- as_completed(fs, timeout=None) : The argument is a list of Future instances and the return value is an iterator that outputs Future instances at the end of the run .
Usage examples.
|
|
Reference links.