When you use Python to process data, you often need to handle data in Excel. Nowadays, you basically use Pandas to read data from Excel, but there are some Python packages other than Pandas that can satisfy the need to read Excel data.

Before we begin, learn the concepts involved in Excel.
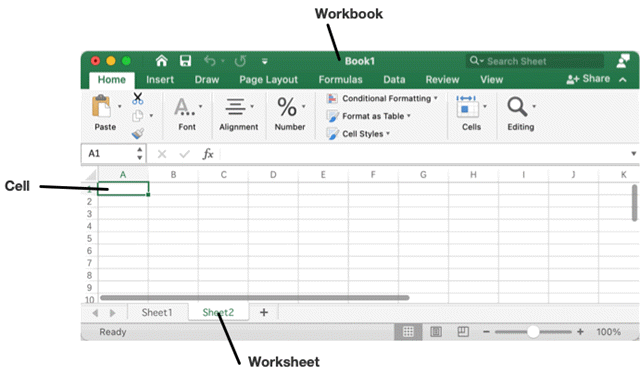
- workbook : In various libraries, a workbook is actually an excel file, which can be regarded as a database.
- sheet : In an excel file, there may be more than one sheet, a sheet can be regarded as a table in a database
- row : row is actually a row in a table, normally represented by the numbers 1, 2, 3, 4
- column : column is a column in a table, normally represented by the letters A, B, C, D
- cell : cell is a cell in a table, you can use the combination of row + column to represent, for example: A3
Differences between the file formats commonly used in Excel.
- XLS : The file format used before Excel version 2003, the binary way of saving files. xls files support a maximum of 65536 rows. xlsx supports a maximum of 1048576 rows. xls supports a maximum of 256 columns, xlsx is 16384 columns, this is the limit of the number of rows and columns is not from Excel version but the version of the file type.
- XLSX: XLSX is actually a ZIP file, that is, if you change the file name of XLSX to zip, and then you can use the unzip software to open the zip file directly, you open it to see the words, you will be able to see a lot of xml files inside.
Python Excel read/write package of xlrd, xlwt
xlrd, xlwt, xlutils is developed by Simplistix, the original website content is basically emptied, the project migrated to http://www.python-excel.org and open source in GitHub, see https://github.com/python-excel. On the website is also currently Very much not recommended for the above tools, the official currently also do not recommend the continued use of the main reasons.
- xlrd module: can read .xls, .xlsx tables
- xlwt module: can write .xls tables (can not write .xlsx files!!!)
- xlutils is not required, but additionally provides some tool functions to simplify the operation.
xlrd
Read file functionality is provided by the xlrd package. xlrd implements the xlrd.book.Book (hereafter referred to as Book), xlrd.sheet.Sheet (hereafter referred to as Sheet) and xlrd.sheet.Cell (hereafter referred to as Cell) types, which correspond to the workbook, sheet and cell concepts in Excel, where the cell is the minimum operational granularity.
xlrd load form files on a function open_workbook, commonly used parameters on two.
- filename, specify the path to open the Excel file
- on_demand, if it is True, then load the workbook on-demand form, if it is False, then directly load all forms, the default is False, in order to save resources is generally set to True, which is more obvious when the performance of large files.
After reading the Excel file to get the Workbook, the next step is to locate the Sheet. the Book class object has several important properties and methods for indexing Sheets.
- nsheets property, which indicates the number of Sheet objects contained
- sheet_names method, which returns the names of all sheets
- sheet_by_index, sheet_by_name methods, which index the sheets using the serial number and name, respectively
- sheets method, which returns a list of all Sheet objects
After getting the Sheet object, the next step is to index the rows/columns/cells and get the data of the rows/columns/cells. the Sheet class object has several important properties and methods to support the subsequent operations.
- the name property, which is the name of the form.
- nrows, ncols properties, indicating the maximum number of rows and columns read into the form. Since cells only support row number indexing, these two properties are necessary to check for out-of-bounds content.
- cell method, accepts 2 parameters, i.e. row and column serial numbers, returns Cell object, note that xlrd only supports indexing cells by row serial number, row serial number starts from 0.
- cell_value method, similar to the cell method, except that the value returned is the value in the cell, not the Cell object.
- cell_type method, returns the type of cell
- row, col method, returns a list of Cell objects composed of 1 whole row (column).
- row_types, col_types, return the type of cells in a number of columns (rows) within the specified row (column).
- row_values, col_values, returns the value of the cell in the specified row (column) of a number of columns (rows).
- row_slice, col_slice, return to the specified row (column) within a number of columns (rows) of cells, is a combination of types and values.
|
|
Note that xlrd reads excel workbooks with row and column indexes starting from 0.
- row = ws.row_values(i, ca, cb) # read the contents of the [ca, cb) column in row i, return list. note that the cb column is not included
- col = ws.col_values(i, ra, rb) # read the contents of the [ra, rb) row in column i, return to list. note that the rb row is not included
- cell= ws.cell_value(r, c) # read the contents of the cell in column j of row i
For predefined constants of data types
| predefined constants | numeric | strings |
|---|---|---|
| XL_CELL_EMPTY | 0 | empty |
| XL_CELL_TEXT | 1 | text |
| XL_CELL_NUMBER | 2 | number |
| XL_CELL_DATE | 3 | xldate |
| XL_CELL_BOOLEAN | 4 | boolean |
| XL_CELL_ERROR | 5 | error |
| XL_CELL_BLANK | 6 | blank |
The date data type is read as a floating point number and needs to be manually converted to time format, such as a cell date of 2020-2-5, xlrd module reads the value: 43866.0, there are two ways to convert a floating point number to the correct time format.
- xldate_as_tuple(xdate,datemode): returns a meta ancestor consisting of (year,month,day,hours,minutes,seconds), datemode parameter has 2 values, 0 means 1900 as the base timestamp (common), 1 means 1904 as the base timestamp. Dates before 1900-3-1 cannot be converted to tuples.
- xldate_as_datetime(xdate,datemode) (need to introduce datetime module first), return a datetime object directly, xlrd.xldate_as_datetime(xdate,datemode).strftime( ‘%Y-%m-%d %H:%M:%S’)
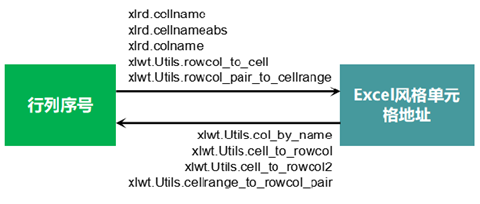
For indexing purposes, the cellname, cellnameabs, and colname functions of the xlrd package convert the row and column serial numbers to Excel-style cell addresses; the rowcol_to_cell and rowcol_pair_to_cellrange functions of the xlwt.Utils module can also convert the row and column serial numbers to Excel-style cell address; and col_by_name, cell_to_rowcol, cell_to_rowcol2, cellrange_to_rowcol_pair functions, the Excel-style cell address converted to row number.
The row number and cell address conversions are summarized in the following figure.
To iterate through all the cells in a sheet, usually by row and column order to get the cell by cell, and then read out the cell value to save for subsequent processing. You can also directly get a whole row (column), the whole row (column) to deal with the data.
|
|
xlwt
xlrd package can only read out the data in the form, can not do anything to rewrite the data, rewrite the data and save it to a file, by xlwt package. xlwt implements a set of xlwt.Workbook. Worksheet (hereinafter referred to as Worksheet) types, but unfortunately there is no inheritance relationship with the xlrd package, which results in the Book and Sheet objects read out of the xlrd package can not be used directly to create Workbook and Worksheet objects, but only to store the data temporarily for subsequent writing back, making the process very cumbersome.
The types, methods, functions and parameters exposed to the public by the xlwt package are also very concise and fit closely with the process of rewriting data and saving it to a file.
- Call the Workbook function of the Workbook module to create a Workbook object, the first parameter is encoding
- call the Workbook object’s add_sheet method to add Worksheet objects to Workbook, the first parameter sheetname specifies the name of the form, the second parameter cell_overwrite_ok determines whether to allow cell overwriting, it is recommended to set to True, to avoid the program may write data to the cell multiple times and throw an error.
- call the Worksheet object write method, to the Worksheet row / column / cell write data, the data used here in most cases from the xlrd package from the Excel file to read the results, the first two parameters for the row number, the third parameter is the value to be written, the fourth parameter is the cell style, such as no special needs default can be; * call the Workbook object write method, to write data to the Worksheet row / column / cell.
- Call the save method of the Workbook object to save the Workbook object to a file, with the parameters of the file name or file stream object.
Other properties, methods, functions are generally used less.
xlwt mainly involves three classes: Workbook corresponds to the workbook file, Worksheet corresponds to the worksheet, XFStyle object used to control the cell format (XF record).
|
|
Example.
|
|
There are two things to remember about saving.
- All Python libraries involving Excel operations do not support “edit and save in place”, and xlwt is no exception. “Save” is actually “Save As”, except that if you specify to save to the original file, the original file is overwritten.
- Even if you specify the extension .xlsx, the file format itself is still xls format.
Note that the date read from data.xls is essentially a numeric value, copied and written or numeric, you need to set the cell to date format in Excel to display as a date form.
xlwt also supports writing formulas, but more limited.
|
|
In addition, xlwr supports writing the contents of merged cells across rows or columns (rowx and colx starting from 0):
|
|
Setting excel cell styles
Set cell data formatting.
The style instance needs to be specified in ws.write() to take effect.
Example.
|
|
Or.
|
|
XFStyle is used to specify the cell content format, use the easyxf function to get an XFStyle object.
|
|
strg_to_parse is a string that defines the format, and can control the formatting properties including font (font), alignment (align), border form (border), color style (pattern) and cell protection (protection), etc. The specific formatting properties are listed in detail at the end of the article.
String strg_to_parse syntax format is as follows.
|
|
For example.
|
|
The parameter string num_format_str is used to specify the format of the number, e.g.
The following are some use cases for xlwt.Style.easyxf.
|
|
xlutils
xlutils depends on xlrd and xlwt and contains the following modules.
- copy: copy xlrd.Book object to xlwt.Workbook object
- display: to display information about xlrd related objects in a more friendly and secure way
- filter: a small framework for splitting and filtering existing Excel files to new Excel files
- margins: get how much useful information is contained in the Excel file
- Book object into an Excel file
- styles: a tool for formatting information in Excel files
- view: use the view information of the worksheet in workbook
Here we mainly introduce the use of two functions, the first xlutils.copy.copy(wb). From the above steps, if you are only generating a brand new Excel file, you can use the xlwt package. If you are “editing” some data in the Excel file, you must use xlrd to load the original file and make a copy of the original table, and then use xlwt to handle the cells that need to be edited, which is a cumbersome process. xlutils package copy is created to simplify this process, and can convert xlrd’s Book object to xlwt’s Workbook object.
The other is the function xlutils.filter.process(reader, *chain) in xlutils.filter.
The module xlutils.filter contains some built-in modules reader, writer and filter, and the function process() for stringing them together, with the main function of filtering and splitting Excel files.
- The reader is used to fetch data from the data source and convert it into a series of Book objects, which will then call the first filter-related method. There are some basic reader classes provided within the module.
- filterThe user gets the results needed for a specific task. Some specific methods have to be defined in the filter. The implementation of these methods can be filled with any functionality as needed, but will usually end with a call to the corresponding method of the next filter.
- writer handles the specific method in the last filter in the parameter chain. writer is usually used to copy information from the data source and write it to the output file. Since there is a lot of work involved in the writer and usually only writing binary data to the target location is slightly different, some basic writer classes are provided within the module.
- process(reader, *chain) can execute built-in or custom readers, writers and filters in tandem.
XFStyle format
format attributes
- font
- bold: boolean value, default is False
- charset: see next section for optional values, default is sys_default
- color (or color_index, color_index, color): see the next section for optional values, default is automatic
- escapement: optional value is none, superscript or subscript, default value is none
- family: a string containing the font family of the font, the default value is none
- height: the height value obtained by multiplying point size by 20, the default is 200, corresponding to 10pt
- italic: boolean value, default is False
- name: a string containing the name of the font, default is Arial
- outline: Boolean value, default is False
- shadow: Boolean value, default is False
- struck_out: Boolean value, default is False
- underline: boolean value or one of none, single, single_acc, double, double_acc. The default value is none
- alignment (or align)
- direction (or dire): one of the general, lr, rl, default general
- horizontal (or horiz, horz): one of the following: general, left, center|centre, right, filled, justified, center|centre_across_selection, distributed one of the following, the default value is general
- indent (or inde): indent value 0 to 15, default value 0
- rotation (or rota): integer value between -90 and +90 or stacked, one of none, default is none
- shrink_to_fit (or shri, shrink): boolean value, default is False
- vertical (or vert): one of top, center|centre, bottom, justified, distributed, default is bottom
- wrap: Boolean value, default is False
- borders (or borders)
- left: border style, see the next section for details
- right: border style, see next section
- top: border style, see next section
- bottom: border style, see next section
- diag: the border style, see the next section
- left_colour (or left_color): color value, see next section, default is automatic
- right_colour (or right_color): color value, see next section, default is automatic
- top_colour (or top_color): color value, see next section, default is automatic
- bottom_colour (or bottom_color): color value, see next section, default is automatic
- diag_colour (or diag_color): color value, see next section, default is automatic
- need_diag_1: Boolean value, default is False
- need_diag_2: Boolean value, default is False
- pattern
- back_colour (or back_color, pattern_back_colour, pattern_back_color): color value, see the next section, default is automatic
- fore_colour (or fore_color, pattern_fore_colour, pattern_fore_color): color value, see next section for details, default is automatic
- pattern: no_fill, none, solid, solid_fill, solid_pattern, fine_dots, alt_bars, sparse_dots, thick_horz_bands, thick_vert_bands, thick_ backward_diag, thick_forward_diag, big_spots, bricks, thin_horz_bands, thin_vert_bands, thin_backward_diag, thin_forward_diag, squares, and diamonds one of them, default is none
- protection
- cell_locked: Boolean value, default is True
- formula_hidden: Boolean value, default is False
Description of the values taken
Boolean
- True can be represented as 1, yes, true, or on.
- False can be 0, no, false, or off.
charset
The optional values for the character set are as follows.
|
|
color
The available values for color are as follows.
| aqua | dark_red_ega | light_blue | plum |
|---|---|---|---|
| black | dark_teal | light_green | purple_ega |
| blue | dark_yellow | light_orange | red |
| blue_gray | gold | light_turquoise | rose |
| bright_green | gray_ega | light_yellow | sea_green |
| brown | gray25 | lime | silver_ega |
| coral | gray40 | magenta_ega | sky_blue |
| cyan_ega | gray50 | ocean_blue | tan |
| dark_blue | gray80 | olive_ega | teal |
| dark_blue_ega | green | olive_green | teal_ega |
| dark_green | ice_blue | orange | turquoise |
| dark_green_ega | indigo | pale_blue | violet |
| dark_purple | ivory | periwinkle | white |
| dark_red | lavender | pink | yellow |
borderline
Can be an integer value from 0 to 13, or one of the following values.
|
|
Reference link.
- https://github.com/python-excel
- http://xlrd.readthedocs.io/en/latest/
- http://xlwt.readthedocs.io/en/latest/api.html
- http://xlutils.readthedocs.io/en/latest/
Python Excel writing tool for xlsxwriter
XlsxWriter is a Python module for writing documents in Excel 2007+ XLSX file format.
xlsxwriter can be used to write text, numbers, formulas and hyperlinks to multiple worksheets, supports formatting and more, and includes.
- 100% compatible with Excel XLSX files.
- Full formatting.
- Merge cells.
- Defined names.
- Charting.
- Automatic filtering.
- Data validation and drop-down lists.
- Conditional formatting.
- Worksheet png/jpeg/bmp/wmf/emf images.
- Rich multi-format strings.
- Cell annotation.
- Integration with Pandas.
- Text boxes.
- Support for adding macros.
- Memory-optimized mode for writing large files.
Pros.
- More powerful: Relatively speaking, this is the most powerful tool other than Excel itself. Font settings, foreground color background color, border settings, view zoom (zoom), cell merge, autofilter, freeze panes, formulas, data validation, cell comments, row height and column width settings, etc.
- Support for large file writes: If the amount of data is very large, you can enable constant memory mode, which is a sequential write mode that writes a row of data as soon as you get it, without keeping all the data in memory.
Disadvantages.
- No read and modify support: The author did not intend to make an XlsxReader to provide read operations. If you can’t read, you can’t modify. It can only be used to create new files. When you write data in a cell, there is still no way to read the information that has been written unless you have saved the relevant content yourself.
- XLS files are not supported: XLS is the format used in Office 2013 or earlier and is a binary format file. XLSX is a compressed package made up of a series of XML files (the final X stands for XML). If you have to create a lower version of XLS file, please go to xlwt.
- Pivot Table is not supported at this time.
xlsxwriter easy to use
|
|
We can also set the style to the excel table, set the style to the table using the add_format method.
|
|
The xlsxwriter package allows us to insert data by row and column, using the following methods.
|
|
Common functions of xlsxwriter module
Set cell formatting
Set the formatting directly by means of a dictionary.
Set the cell format by means of the format object.
There are many more operations like this for some cell tables, so you can study them according to your needs.
|
|
Common chart types.
- area: Creates an Area (solid line) style sheet.
- bar: Creates a bar style (transposed histogram) chart.
- column: Creates a column style (histogram) chart.
- line: Creates a line chart.
- pie: Creates a pie-style chart.
- doughnut: Creates a doughnut style chart.
- scatter: Creates a scatter chart style chart.
- stock: Creates a stock style chart.
- radar: Creates a radar style sheet.
Sample Code Explanation
|
|
Types supported by XlsxWriter
Excel often treats different types of input data, such as strings and numbers, differently, though usually transparently to the user. the XlsxWriter view emulates this with the worksheet.write() method, by mapping Python data types to the types supported by Excel.
The write() method serves as a generic alias for several more specific methods.
- write_string()
- write_number()
- write_blank()
- write_formula()
- write_datetime()
- write_boolean()
- write_url()
In the code here, we use some of these methods to handle different types of data.
This is mainly to show that if you need more control over the data you write to the worksheet, you can use the appropriate methods. In this simple example, the write() method actually works out well.
Date handling is also new to the program.
Dates and times in Excel are floating-point numbers applied in a numeric format to make it easier to display them in the correct format. If the date and time are Python datetime objects, then XlsxWriter will automatically do the required numeric conversion. However, we also need to add numeric formatting to ensure that Excel displays them as dates.
|
|
Finally, set_column() is needed to adjust the width of column B so that the date can be displayed clearly.
Reference links.
Python Excel Reading and Writing with OpenPyXL
And you can make detailed settings for the cells in the Excel file, including cell styles and other content, and even support the insertion of charts, print settings and other content. openpyxl can read and write xltm, xltx, xlsm, xlsx and other types of files.
The general process of using openpyxl is: create/read excel file -> select sheet object -> operate on form/cell -> save excel
Create/read excel files
sheet form operations
|
|
Cell object
|
|
Format style setting
|
|
Other
|
|
Python Excel manipulation of xlwings
xlwings is a BSD-licensed Python based library. It makes it easy to call each other between Python and Excel:
- Scripting: Automate the processing of Excel data in Python or interact with Excel using VBA-like syntax.
- Macros: Replace VBA macros with powerful and clean Python code.
- UDFs (User Defined Functions): Write User Defined Functions (UDFs) in Python, for windows only.
- REST API: Open Excel workbooks to the outside through the REST API.
- Support for Windows and MacOS
xlwings open source free , can be very easy to read and write data in Excel files , and cell formatting changes . xlwings can also seamlessly connect with matplotlib, Numpy and Pandas , support for reading and writing Numpy, Pandas data types , matplotlib visual charts into excel. The most important thing is that xlwings can call the program written by VBA in Excel file, and also can let VBA call the program written in Python. It supports reading of .xls files and reading and writing of .xlsx files.
The main structure of xlwings.
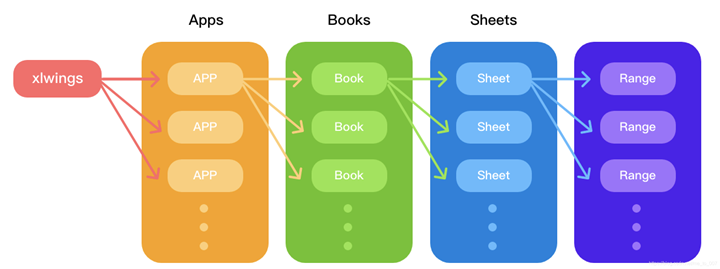
As you can see, the direct interface with xlwings is the apps, that is, the Excel application, then the workbook books and worksheet sheets, and finally the cell area range, which is quite different from openpyxl, and because of this, xlwings needs to still have the Excel application environment installed.
App common syntax
|
|
Book common syntax
|
|
Sheet common syntax
|
|
Range common syntax
|
|
Transformer
|
|
Reference link.
Python Excel Quick Write Tool PyExcelerate
PyExcelerate is claimed to be the best performing Python writing package for Excel xlsx files. It is also relatively easy to use.
|
|
Python read and write Excel tool pyexcel
PyExcel is an open source Excel manipulation library. It wraps a set of APIs for reading and writing file data , this set of APIs accept parameters including two keyword collections , one specifying the data source , the other specifying the destination file , each collection has many keyword parameters to control the read and write details . pyexcel package also implements a workbook , form types for accessing , manipulating and saving data , read and write operations are very fancy.
Read the file
pyexcel contains some get functions for reading files: get_array, get_dict, get_record, get_book, get_book_dict, get_sheet. These methods convert the file content to various types such as array, dict, sheet/book, etc., masking the file media to be csv/tsv text, xls/xlsx table files, dict/list types, sql database tables, and other details. There is also an equivalent set of iget series functions, the only difference being the return generator for efficiency.
- The get_sheet function takes the sheet_name parameter, which is used to specify the sheet to be read for Excel tables with multiple sheets, or the 1st sheet if default. get_sheet function also takes the name_columns_by_row/name_rows_by_column parameter for the specified row/column as the column/row name. The default value is 0, which represents the 1st row, and the sheet.Sheet class has a method with the same name for the same operation. Several other functions are more similar to get_sheet and accept the same parameters.
- The get_array function converts the file data into an array, i.e. a nested list, with each element of the list corresponding to one row of the table.
- The get_dict function converts the file data into an ordered dictionary, using the field in the first row as the key and subsequent rows of values forming a list as the value.
- get_record function converts the file data into a list formed by an ordered dictionary, each line of data corresponds to an ordered dictionary, and the dictionary uses the field of the first line of the file as the key and the line of data as the value.
- get_book function converts the file into a book.Book object. If read from a csv file, it contains only 1 sheet, the name is the file name; if read from an xls file, it contains all the sheets in the xls file.
- get_book_dict function converts the file data into an ordered dictionary of multiple sheets, with sheet name as key and sheet data in the form of a nested list as value, which is more useful in Excel tables containing multiple sheets; for csv files, as there is only 1 sheet, the returned ordered dictionary has only 1 item.
Data Access
Book and Sheet
Book and pyexcel.book.Sheet types are implemented in pyexcel, which correspond to the concept of book and sheet in Excel sheet files, and can be obtained as book/sheet objects by the above get series functions, or by pyexcel.Book()/ pyexcel.Sheet() function to create.
After getting the book object, the next step is to access the sheets in the book. pyexcel.book.Book class object can index the corresponding sheets by serial number, or you can call the sheet_by_index and sheet_by_name methods to get the specified sheet content, and call the sheet_names method to return Calling the sheet_names method returns the names of all the sheets contained in the book object.
The pyexcel.sheet.Sheet class object has a texttable property, which means that the text, in addition to the sheet name, and the dotted line character to draw the table border, directly print the variable sh and print sh.texttable effect is the same.
In addition, pyexcel.sheet.Sheet class has several very useful properties.
- content property, compared to displaying the sheet directly, there is less of the sheet name in the first row.
- csv property, the csv form of the sheet data, without the table box line.
- array property, the array form of the sheet data (nested list), the same as the get_array function returns.
- row/column property, very similar to nested list, supports accessing specified row/column by subscript, serial number starts from 0.
Rows and Columns
After getting pyexcel.sheet.Sheet object, besides using row/column property to get all the row/column objects collection for further iterative traversal, you can also index any row/column by serial number, which starts from 0. When the serial number exceeds the table row/column range, an IndexError error is thrown, and you can use the row_range/column_range methods of the sheet object to check the row/column range. row_at/column_at methods of pyexcel.sheet. The serial number index is equivalent.
Cells
The pyexcel.sheet.Sheet object supports binary serial number indexing of any cell, or replacing the serial number with a row/column name (please note the code comments below). It can also be indexed in its entirety as an Excel sheet cell address without any conversion.
Rewrite the file
Rewriting a file includes two steps: rewriting variable values and writing variable objects to the file, which is recommended to be done through pyexcel.book.Sheet or pyexcel.book.
For pyexcel.book.Sheet class object, row and column properties support add, delete and change operations like list, and both have save_as method for writing objects to file. In addition, pyexcel provides the save series wrapper functions: save_as, save_book_as to write to a file, and when specifying the destination file, the parameter names used are prefixed with “dest_” compared to the get series. For example, get series use file_name to specify the source of the data file, save series use dest_file_name to specify the destination file path; get series use delimiter parameter to specify the csv separator, save series use dest_delimiter to specify the separator used when writing to csv files. pyexcel. Sheet class object can be added, deleted or changed in whole rows/columns, and can also be positioned to assign values to specific cells, and the number of elements should be consistent with the number of columns/rows when using a list of whole rows/columns to assign values. For pyexcel.book.Book class object, you can either extend the whole book as a whole like an operation list, or index only some sheets and then stitch and assign values as a whole. pyexcel.book.Sheet also implements form transpose, region, cut, paste, and map application. paste, map application (map), row filtering (filter), formatting (format) and other fancy operations.
Book class object’s save_as method, which is simple and straightforward, and is recommended for operating Excel. You can also use the pyexcel package level save series wrapper functions, which are more suitable for file type conversion, and there is an equivalent set of isave series functions, the main difference is that the variables are only read in when writing, to improve efficiency. These save methods/functions above will automatically discern the format type based on the destination file extension. pyexcel.book.Sheet or pyexcel.book.Book classes also implement the save_to series of functions to write objects to database, ORM, memory, etc.
Summary
- The pyexcel package encapsulates the get series of functions for reading and converting data from files, all of which can flexibly support multiple ways of reading files. For manipulating Excel files, the get_sheet function is recommended to be preferred.
- pyexcel package support for different formats of files depends on different plug-in packages.
- pyexcel package internally implements the book.Sheet or pyexcel.book.Book type, which corresponds to the workbook and form concepts of Excel files, providing a variety of flexible methods for data access, deletion, and visualization.
- Book type has the save series of methods to write object variables to files, databases, memory, etc., which is recommended and preferred; also the pyexcel package level save_as series of wrapper functions are very convenient for converting file types; these methods/functions for writing to files automatically discriminate based on the destination file extensions The format type is automatically determined by the destination file extension.
- cookbook package encapsulates some utility functions, such as multi-type file merge, table split;
- book.Sheet and pyexcel.book.Book and other classes do not implement the full method, call some will throw an error, be aware of this big hole, this article in the ipython environment when writing examples of the error is not given, which is also the reason for the prompt number is not consecutive.
Reference links.
Other tools.
- Excel formula tool: https://github.com/vinci1it2000/formulas