What is the most likely to encounter, the most annoying, the most disgusting problem in program development? Character encoding problems! This article expects to solve this problem with the most detailed sorting.
What is encoding?
The information stored in the computer is expressed in binary numbers; and the characters we see on the screen, such as English and Chinese characters, are the result of binary number conversion. Generally speaking, according to what rules the characters are stored in the computer, such as what ‘a’ represents, is called “encoding”; conversely, the binary numbers stored in the computer are parsed and displayed, called “decoding “, just like encryption and decryption in cryptography. In the decoding process, if the wrong decoding rules are used, ‘a’ will be resolved into ‘b’ or garbled.
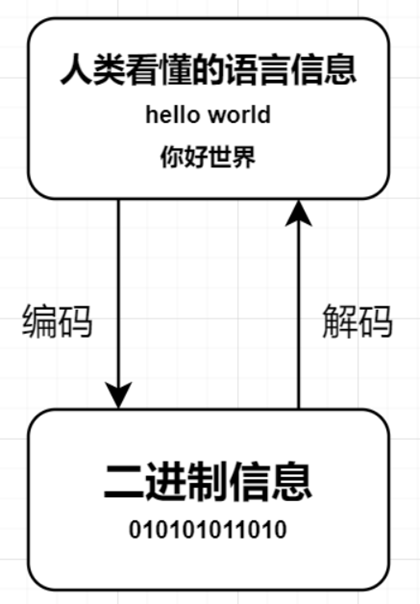
Two concepts about encoding.
- Character set (Charset) : It is a collection of all abstract characters supported by a system. Charset is a general term for various characters and symbols, including various national scripts, punctuation marks, graphic symbols, numbers, etc.
- Character Encoding : is a set of laws using which it is possible to pair a collection of characters of a natural language (such as an alphabet or syllabary), with a collection of something else (such as a number or an electrical pulse). That is, a correspondence is established between a collection of symbols and a system of numbers, and it is a fundamental technique for information processing. Usually people use a collection of symbols (in general, words) to express information. Computer-based information processing systems, on the other hand, use combinations of different states of components (hardware) to store and process information. The combination of different states of the components can represent the numbers of the digital system, so character encoding is the conversion of symbols into numbers of the digital system acceptable to the computer, called digital codes.
Common character set names: ASCII character set, GB2312 character set, BIG5 character set, GB18030 character set, Unicode character set, etc. To accurately process various character set characters, computers need to encode characters so that they can recognize and store various characters.
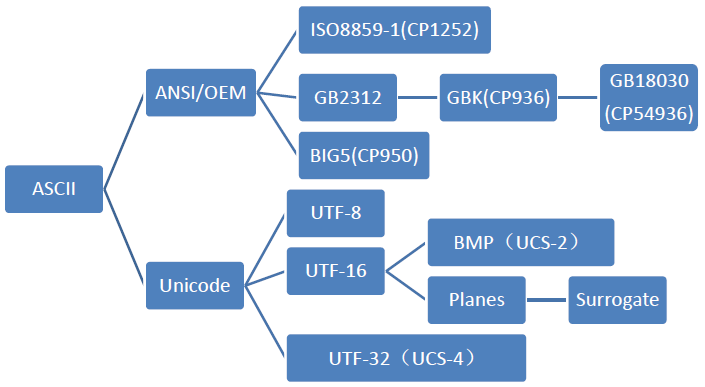
ASCII character set and ASCII encoding
ASCII (American Standard Code for Information Interchange) is a computer coding system based on the Latin alphabet. It is primarily used to display modern English, while its extended version, EASCII, can barely display other Western European languages. It is the most common single-byte coding system in use today, and is equivalent to the international standard ISO/IEC 646.
ASCII Character set : mainly includes control characters (carriage return, backspace, line feed, etc.); displayable characters (English case characters, Arabic numerals, and Western symbols).
ASCII encoding : Rules for converting the ASCII character set to a number system that the computer can accept. Use 7 bits (bits) to represent a character, a total of 128 characters; however, the 7-bit encoding character set can only support 128 characters, in order to represent more common European characters to ASCII was extended, ASCII extended character set uses 8 bits (bits) to represent a character, a total of 256 characters. ASCII character set mapping to numeric encoding rules are shown in the following figure.
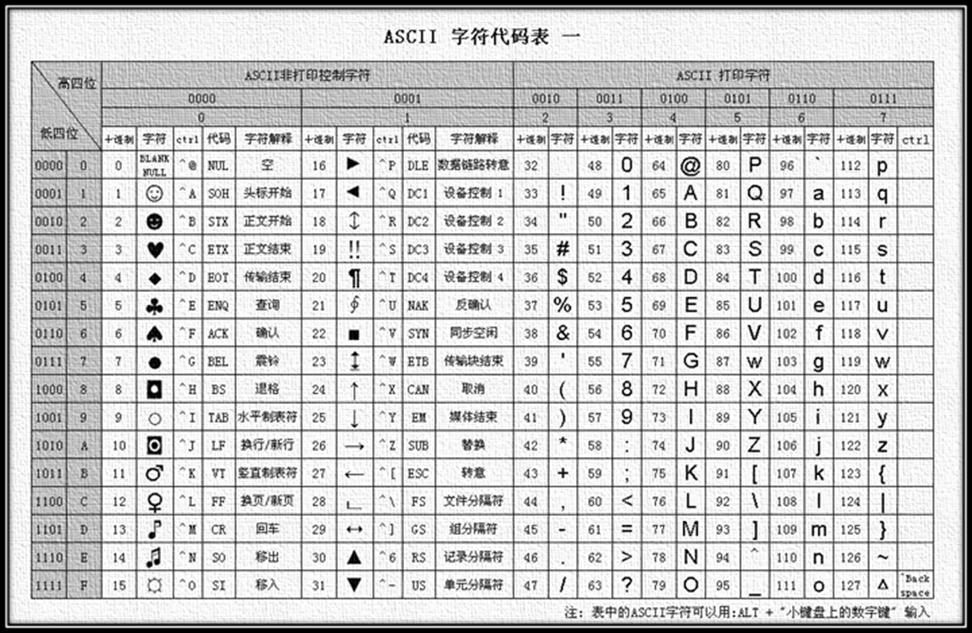
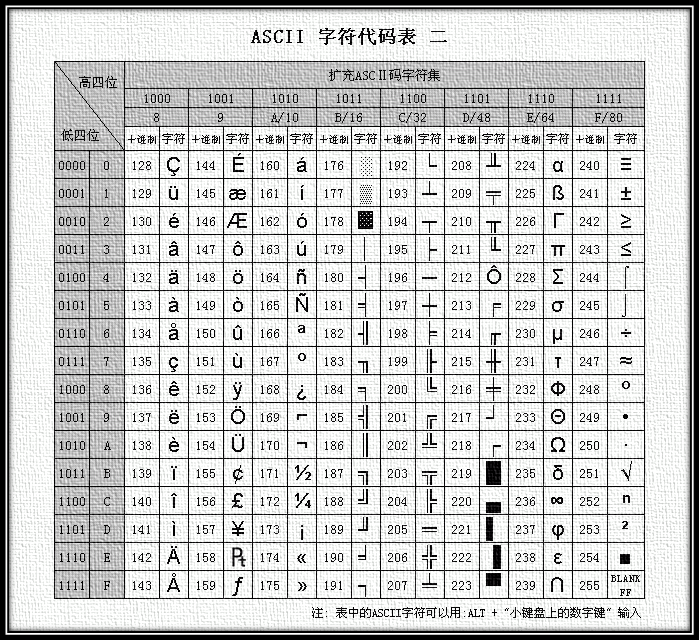
The biggest disadvantage of ASCII is that it can only display the 26 basic Latin letters, Arabic numbers and British punctuation, so it can only be used to display modern American English (and when dealing with foreign words in English such as naive, café, élite, etc., all accents have to be removed, even though this would violate spelling rules). EASCII solved the display problem for some Western European languages, but it still can’t do anything for many other languages. So nowadays Apple computers have abandoned ASCII and switched to Unicode.
GBXXXX character set & encoding
At the beginning of computer invention and for a long time afterwards, ASCII was only used in the United States and some developed countries in the West, and it could meet the needs of users very well. However, when computers became available in China, in order to display Chinese characters, a set of coding rules had to be designed for converting Chinese characters into numbers in a number system acceptable to computers.
The Chinese experts eliminated the odd symbols after 127 (i.e. EASCII) and specified that a character less than 127 has the same meaning as the original, but when two characters greater than 127 are concatenated, they represent a Chinese character, with the first byte (which he called the high byte) going from 0xA1 to 0xF7, and the next byte (the low byte) going from 0xA1 to 0xFE. This way we can combine about 7000+ simplified Chinese characters. In these codes, mathematical symbols, Roman Greek letters, and Japanese kana are also coded in, and even the numbers, punctuation, and letters that are already in ASCII are all re-coded in two-byte-long codes, which are often called “full-angle” characters, while those below 127 are called “half-angle” characters. This is often called “full-angle” characters, while those below 127 are called “half-angle” characters. The above encoding rule is GB2312.
GB2312 or GB2312-80 is the Chinese national standard simplified Chinese character set, also known as GB0, which was issued by the General Administration of Standards of China and implemented on May 1, 1981. The GB2312 encoding is commonly used in mainland China; Singapore and other places also adopt this encoding. Almost all Chinese systems and internationalized software in mainland China support GB2312. The emergence of GB2312 has basically met the needs of computer processing of Chinese characters, and the Chinese characters it includes have covered 99.75% of the usage frequency in mainland China. For rare characters appearing in personal names and ancient Chinese, GB2312 cannot handle them, which led to the later GBK and GB 18030 character sets for Chinese characters emerged. The following chart shows the beginning of the GB2312 encoding (due to its very large size, only the beginning is listed, please check GB2312 Simplified Chinese Encoding Table for details).

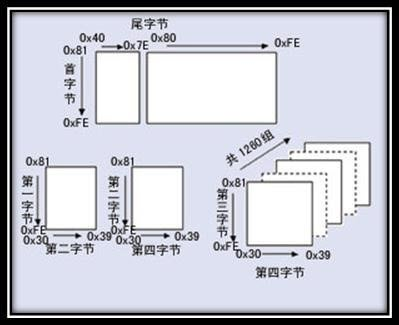
In GB 2312, the received characters are “partitioned” and each partition contains 94 characters/symbols. This representation is also called area code.
- Zones 01-09 are for special symbols.
- Zones 16-55 are first-level Chinese characters, sorted by pinyin.
- Zones 56-87 are second-level Chinese characters, sorted by radicals/strokes.
- Zones 10-15 and 88-94 are not coded.
For example, the character “啊” is the first character in GB2312, and its area code is 1601.
GBK is the Chinese Internal Code Extension Specification, and K is the vowel of the word “扩” in Hanyu Pinyin Kuo Zhan (Extension). Since GB 2312-80 only contains 6763 Chinese characters, there are many Chinese characters, such as those simplified after the introduction of GB 2312-80 (e.g. “lo”), some characters used in personal names, traditional characters used in Taiwan and Some of the characters used for personal names, traditional Chinese characters used in Taiwan and Hong Kong, and Japanese and Korean characters are not included. Therefore, Microsoft used the unused encoding space of GB2312-80 and included all characters from GB 13000.1-93 to create the GBK encoding. According to Microsoft, GBK is an extension of GB2312-80, which is an extension of the CP936 character code list (Code Page 936) (previously CP936 and GB 2312-80), which was first implemented in the Simplified Chinese version of Windows 95. Although GBK includes all the characters of GB 13000.1-93, the encoding method is not the same. GBK itself is not a national standard, but was once published as a “technical specification guidance document” by the Standardization Department of the State Bureau of Technical Supervision and the Department of Science, Technology and Quality Supervision of the Ministry of Electronics Industry. The original GB13000 has not been adopted by the industry, and the subsequent national standard GB18030 is technically compatible with GBK rather than GB13000.
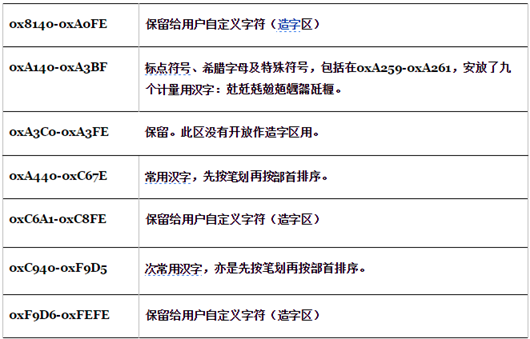
GB 18030 , full name: National Standard GB 18030-2005 “Information Technology Chinese Coded Character Set”, is the latest internal code character set of the People’s Republic of China now, and is a revised version of GB 18030-2000 “Information Technology The expansion of the basic set of Chinese characters coding character set for information exchange”. It is fully compatible with GB 2312-1980 and basically compatible with GBK, and supports all unified Chinese characters of GB 13000 and Unicode, with a total of 70,244 Chinese characters included. GB 18030 has the following main features.
- Same as UTF-8, it adopts multi-byte encoding, each character can be composed of 1, 2 or 4 bytes.
- Large encoding space, up to 1.61 million characters can be defined.
- Supports characters of Chinese domestic minorities without using the character creation area.
- Chinese characters include traditional Chinese characters and Japanese and Korean characters.
The overall structure of GB18030 code.
The initial version of this specification made the Ministry of Information Industry of the People’s Republic of China Electronics Industry Standardization Institute draft, issued by the State Administration of Quality and Technical Supervision on March 17, 2000. The current version was issued by the State Administration of Quality Supervision and Inspection and the China National Standardization Administration on November 8, 2005 and implemented on May 1, 2006. This specification is a mandatory specification supported by all software products in China.
BIG5 character set & BIG5 encoding
Big5 , also known as Big5 or Big5, is the most commonly used computer character set standard in the Traditional Chinese (orthographic Chinese) using community, and contains a total of 13,060 Chinese characters. Chinese codes are divided into two categories: internal codes and interchange codes, Big5 belongs to Big5 is a Chinese internal code, and the well-known Chinese interchange codes are CCCII and CNS11643. It is not a local national standard, but only an industry standard. In 2003, Big5 was included in the appendix of the CNS11643 Chinese standard interchange code, and gained a more formal status. This latest version is called Big5-2003.
The Big5 code is a double-byte character set that uses a double octet storage method, with two bytes to place a word. The first byte is called the “high byte” and the second byte is called the “low byte.” The “high byte” uses 0x81-0xFE, and the “low byte” uses 0x40-0x7E, and 0xA1-0xFE. In the Big5 partition.
Unicode
Like in Heaven, when computers are transmitted to various countries in the world, encoding schemes like GB232/GBK/GB18030/BIG5 are designed and implemented to suit local languages and characters. This way each gets a set, no problem to use locally, once it appears in the network, due to incompatibility, mutual access to the garbled code phenomenon.
To solve this problem, a great idea was created - Unicode, a coding system designed for expressing arbitrary characters in any language. It uses 4-byte numbers to represent each letter, symbol, or ideograph. Each number represents a unique symbol used in at least one language. (Not all digits are used, but the total is already more than 65535, so 2 bytes of digits are not enough.) Characters shared by several languages are usually encoded with the same number, unless there is a valid etymological reason not to do so. Ignoring this case, each character corresponds to a digit, and each digit corresponds to a character. That is, there is no duality. U+0041 always stands for ‘A’, even if the language does not have the character ‘A’.
In the field of computer science, Unicode (Unicode, Unicode, Unicode, Standard Unicode) is an industry standard that allows computers to represent dozens of writing systems around the world. Unicode is based on the Universal Character Set (E7%94%A8%E5%AD%97%E7%AC%A6%E9%9B%86) standard, and is published in book form. By the sixth edition, Unicode contains over 100,000 characters (in 2005, the 100,000th character of Unicode was adopted and accepted as a standard), a set of code charts for visual reference, a set of encoding methods and a set of standard character encodings, an enumeration of character characteristics such as superscripts and subscripts, and so on. The Unicode Consortium is a non-profit organization that leads the development of Unicode, with the goal of replacing existing character encoding schemes with Unicode, especially in multilingual environments where space is limited and incompatibility is a problem.
(It is understood that Unicode is the character set and UTF-32/ UTF-16/ UTF-8 are the three character encoding schemes.
UCS & UNICODE
Universal Character Set (UCS) is the standard character set defined by the ISO 10646 (or ISO/IEC 10646) standard developed by ISO. Historically, there have been two independent attempts to create a single character set, the International Organization for Standardization (ISO) and the Unicode Consortium, a group of multilingual software manufacturers. The former developed the ISO/IEC 10646 project and the latter developed the Unicode project. Thus different standards were initially developed.
Around 1991, the participants in both projects realized that the world did not need two incompatible character sets. So they began to merge the results of their work and to work collaboratively towards the creation of a single encoding table. Starting with Unicode 2.0, Unicode adopted the same font and character code as ISO 10646-1; ISO also promised that ISO 10646 would not assign values to UCS-4 encodings beyond U+10FFFF, to make the two consistent. Both projects still exist and publish their standards independently. However, both the Unicode Consortium and ISO/IEC JTC1/SC2 have agreed to keep the code lists of both standards compatible, and to work closely together to adapt any future extensions. At the time of publication, Unicode generally uses the most common font for the word code in question, but ISO 10646 generally uses Century font whenever possible action=edit&redlink=1).
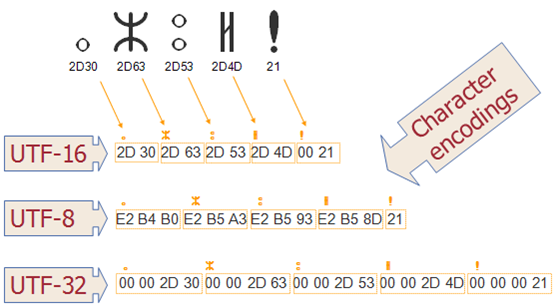
UTF-32
The above encoding scheme that uses 4-byte numbers for each letter, symbol, or ideograph (ideograph), with each number representing a unique symbol used in at least some language, is called UTF-32. UTF-32, also known as UCS-4, is a protocol for encoding Unicode characters, using 4 bytes for each character. It is very inefficient as far as space is concerned.
This method has its advantages, the most important one being the ability to locate the Nth character in a string in constant time, since the Nth character starts at the 4×Nth byte. Although it may seem convenient to use a fixed length of bytes for each code bit, it is not as widely used as other Unicode encodings.
UTF-16
Although there are a very large number of Unicode characters, most people don’t actually use more than the first 65535 characters. Therefore, there is another Unicode encoding method called UTF-16 (because 16 bits = 2 bytes). UTF-16 encodes characters in the 0-65535 range into 2 bytes, so if you really need to express those rarely used “astral plane “The most obvious advantage of UTF-16 encoding is that it is twice as space efficient as UTF-32, since each character requires only 2 bytes to be stored (excluding the 65535 range), instead of 4 bytes in UTF-32. . And, if we assume that a string does not contain any character in the asterisk layer, then we can still find the Nth character in constant time until it does not hold which is always a good inference. The encoding method is.
- If the character encoding U is less than 0x10000, i.e. within 0 to 65535 in decimal, then the two-byte representation is used directly.
- If the character encoding U is greater than 0x10000, since the UNICODE encoding range is up to 0x10FFFF, there are a total of 0xFFFFF encodings between 0x10000 and 0x10FFFF, which means that 20 bits are needed to mark these encodings. The first 10 bits are used as the high bit and the 16 bit value 0xD800 for logical or operation, and the last 10 bits are used as the low bit and 0xDC00 for logical or operation, so the 4 bytes constitute the encoding of U.
For UTF-32 and UTF-16 encoding methods there are some other disadvantages that are not obvious. Different computer systems will store bytes in a different order. This means that the character U+4E2D may be saved as 4E 2D or 2D 4E in UTF-16 encoding, depending on whether the system uses big-endian or little-endian. (For UTF-32 encoding, there are many more possible byte arrangements.) As long as the document does not leave your computer, it is still safe - different programs on the same computer use the same byte order. But when we need to transfer this document between systems, perhaps in the World Wide Web, we need a way to indicate how our bytes are currently stored. Otherwise, the computer receiving the document will not know whether the two bytes 4E 2D express U+4E2D or U+2D4E.
To solve this problem, the multi-byte Unicode encoding method defines a “Byte Order Mark”, which is a special non-printing character that you can include at the beginning of your document to indicate the byte order you are using. For UTF-16, the Byte Order Mark is U+FEFF. If you receive a UTF-16 encoded document starting with byte FF FE, you can be sure that its byte order is one way; if it starts with FE FF, you can be sure that the byte order is reversed.
UTF-8
UTF-8 (8-bit Unicode Transformation Format) is a variable-length character encoding for Unicode ( fixed-length code), and a [prefix code](http://zh.wikipedia. org/w/index.php?title=%E5%89%8D%E7%BC%80%E7%A0%81&action=edit&redlink=1). It can be used to represent any character in the Unicode standard, and the first byte of its encoding is still compatible with ASCII, which allows software that originally handled ASCII characters to continue to be used without or with only a few modifications. As a result, it is becoming the preferred encoding for e-mail, Web pages, and other applications that store or transmit text. The Internet Engineering Task Force (IETF) requires all Internet protocols to support UTF-8 encoding.
UTF-8 uses one to four bytes for each character encoding.
- 128 US-ASCII characters encoded in one byte (Unicode range from U+0000 to U+007F).
- Latin, Greek, Cyrillic, Armenian, Hebrew, Arabic, Syriac and Tanakh with additional symbols require two bytes (Unicode range from U+0080 to U+07FF).
- Characters in other Basic Multiliterate Planes (BMP) (this contains most commonly used characters) use a three-byte encoding.
- Characters in other rarely used Unicode auxiliary planes use a four-byte encoding.
This is very effective in handling frequently used ASCII characters. It is also no worse than UTF-16 in handling extended Latin character sets. For Chinese characters, it is better than UTF-32. Also, (you’ll have to trust me on this one, because I’m not going to show you the math of it.) By the nature of bit manipulation, there is no longer a byte order problem with UTF-8. A document encoded in utf-8 is the same stream of bits from computer to computer.
In general, it is not possible to determine the length needed to display a Unicode string by the number of code points, or where the cursor should be placed in the text buffer after displaying the string; combining characters, variable-width fonts, unprintable characters, and right-to-left text are all attributed to it. So although the relationship between the number of characters and the number of code points is more complex in UTF-8 strings than in UTF-32, in practice it is rare to encounter a situation where it is different.
Advantages
- UTF-8 is a superset of ASCII. Because a pure ASCII string is also a legal UTF-8 string, existing ASCII text does not need to be converted. Software designed for the legacy extended ASCII character set can often be used with UTF-8 with little or no modification.
- Sorting UTF-8 using standard byte-oriented sorting routines will produce the same results as sorting based on Unicode code points. (Although this is only of limited usefulness, since it is unlikely that there will be a still-acceptable ordering of text in any given language or culture.)
- UTF-8 and UTF-16 are both standard encodings for Extensible Markup Language documents. All other encodings must be specified either explicitly or by text declaration.
- Any byte-oriented string search algorithm can be used for UTF-8 data (as long as the input consists of only complete UTF-8 characters). However, care must be taken with regular expressions or other constructs that contain character notation.
- UTF-8 strings can be reliably identified by a simple algorithm. That is, the probability that a string will behave as a legal UTF-8 in any other encoding is low and decreases with the length of the string. For example, the character values C0,C1,F5 to FF never appear. For better reliability, regular expressions can be used to count illegal overlengths and alternative values (see the W3 FAQ: Multilingual Forms on validating UTF-8 strings for (regular expressions).
Disadvantages
- Because each character is encoded using a different number of bytes, finding the Nth character in the string is an O(N) complexity operation - i.e., the longer the string, the more time is needed to locate a specific character. Also, bit transformations are needed to encode characters into bytes and decode bytes into characters.
Encoding problems on Windows systems
When using Windows Notepad to keep files, you can see that there are several encoding formats: ANSI, Unicode, Unicode big endian, UTF-8. You can easily convert these encodings with Notepad.
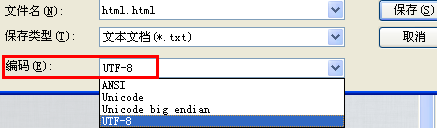
What the hell is ANSI?
ANSI is a non-profit organization responsible for the development of American national standards.
Different countries and regions have developed different standards, resulting in their own encoding standards such as GB2312, GBK, Big5, Shift_JIS, and so on. These various ways of extending the encoding of Chinese characters using 1 to 4 bytes to represent a character are called ANSI encoding. In Simplified Chinese Windows operating system, ANSI encoding represents GBK encoding; in Japanese Windows operating system, ANSI encoding represents Shift_JIS encoding. The “ANSI encoding” is called " native encoding”.
Another name for ANSI is MBCS, and MBCS (Multi-Byte Character Set) is a generic term for multi-byte encoding. So far everyone has used double-byte, so sometimes it is also called DBCS (Double-Byte Character Set). It must be clear that MBCS is not a specific encoding, but in Windows it refers to different encodings depending on the region you set, while in Linux you cannot use MBCS as an encoding. You can’t see the characters MBCS in Windows because Microsoft uses ANSI to scare people in order to be more foreign, and the Save As dialog box in Notepad encodes ANSI as MBCS.
What is the difference between Unicode and Unicode big endian?
On almost all machines, multibyte objects are stored as sequences of consecutive bytes. And there are two general rules for alignment within a storage address. A multi-bit integer will be arranged according to the lowest or highest byte of its storage address. If the lowest valid byte is in front of the highest valid byte, it is called small end order (; and vice versa, it is called large end order. In network applications, byte order is a factor that must be taken into account, because different machine types may use different standard byte orders, so they are all converted according to the network standard.
The word “endian” comes from Jonathan Swift’s novel Gulliver’s Travels. In the novel, the Little People argue over whether to peel the boiled egg from the Big-End or the Little-End, and the two sides of the argument are called the “Big-Enders” and the “Little-Enders” respectively. The following is a description of the history of the Little-End controversy in 1726: “I will tell you that the two powers, Lilliput and Blefuscu, have been fighting bitterly for the last 36 months. The war began for the following reason: We all agree that the primitive way to break an egg before eating it is to break the larger end of the egg, but the grandfather of the present emperor, who ate eggs as a child, happened to break one of his fingers once while beating an egg according to the ancient method. So his father, the emperor at the time, issued a royal decree ordering all his subjects to break the smaller end of the egg when they ate it, with heavy fines for violating the decree. The people were extremely disgusted by this order. History tells us that there were thus six rebellions, in which one emperor died and another lost his throne. Most of these rebellions were instigated by the king’s ministers in Blefuscu. After the rebellions subsided, the exiles always fled to that empire to seek refuge. It is estimated that on several occasions 11,000 people were willing to die rather than break the smaller end of the egg. Hundreds of large works have been published on this dispute, though the books of the Great Enders have been forbidden, and the law has forbidden anyone of that school to be an official.”
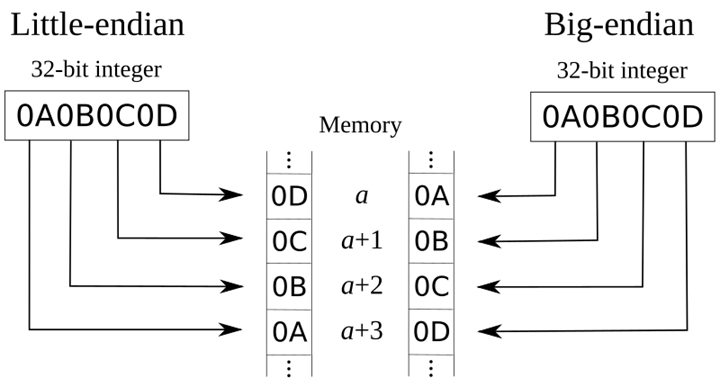
big-endian
- Data in 8bit units: Address growth direction → 0x0A 0x0B 0x0C 0x0D
- In the example, the highest bit byte is 0x0A stored at the lowest memory address. The next byte 0x0B exists at the address after it. It is similar to the reading order of hexadecimal bytes from left to right.
- Data in 16bit units: Address growth direction → 0x0A0B 0x0C0D
- The highest 16bit unit 0x0A0B is stored in the lower bit.
little-endian
- Data in 8bit units: Address growth direction → 0x0D 0x0C 0x0B 0x0A
- The lowest bit byte is 0x0D stored at the lowest memory address. Subsequent bytes are stored at the subsequent addresses in order.
- Data in 16bit units: Address growth direction → 0x0C0D 0x0A0B
- The lowest 16bit cell 0x0D0C is stored at the lower bit.
Take the Chinese character “严” as an example, the Unicode code is 4E25, which needs to be stored in two bytes, one byte is 4E and the other byte is 25; when storing, 4E is in front and 25 is behind, which is the Big endian way; 25 is in front and 4E is behind, which is the Little endian way. .
There is no technical reason to choose a byte order rule, so the argument degenerates into an argument about a socio-political issue, and the choice of which byte order is actually arbitrary, as long as a rule is chosen and consistently adhered to. Naturally, then, the question arises: How does a computer know which way a file is actually encoded?
The Unicode specification defines that each file is prefixed with a character that indicates the encoding order, and the name of this character is ZERO WIDTH NO-BREAK SPACE (FEFF). This is exactly two bytes, and FF is 1 larger than FE.
If the first two bytes of a text file are FE FF, it means the file is in big header mode; if the first two bytes are FF FE, it means the file is in small header mode.
- Unicode: The encoding is four bytes “FF FE 25 4E”, where “FF FE” indicates that it is stored in the small header mode, and the real encoding is 4E25.
- Unicode big endian: the encoding is four bytes “FE FF 4E 25″, where “FE FF” indicates that the file is stored in big endian.
UTF-8 And BOM
BOM - Byte Order Mark. In UCS encoding, there is a character called “Zero Width No-Break Space”, which is encoded as FEFF in Chinese, and FFFE is a non-existent character in UCS, so it should not appear in actual transmission. The UCS specification recommends that we transmit the character “Zero Width No-Break Space” before transmitting the byte stream. So that if the receiver receives FEFF, it indicates that the byte stream is Big-Endian; if it receives FFFE, it indicates that the byte stream is Little-Endian. Therefore, the character “Zero Width No-Break Space” is also called BOM.
BOM (byte order mark) is prepared for UTF-16 and UTF-32, UTF-8 does not need BOM to indicate byte order, but can use BOM to indicate encoding method. The UTF-8 encoding of the character “Zero Width No-Break Space” is EF BB BF, so if the receiver receives a byte stream starting with EF BB BF (hexadecimal), it knows that it is UTF-8 encoding. Windows uses the BOM to mark how text files are encoded. Microsoft uses the BOM in UTF-8 because it makes a clear distinction between UTF-8 and ASCII and other encodings, but such files can cause problems in operating systems other than Windows. The bugs it creates include, but are not limited to.
- 锘
- HTML blank lines
- unexplained spacing between divs
- garbled code
- Ssl errors
- Compilation errors
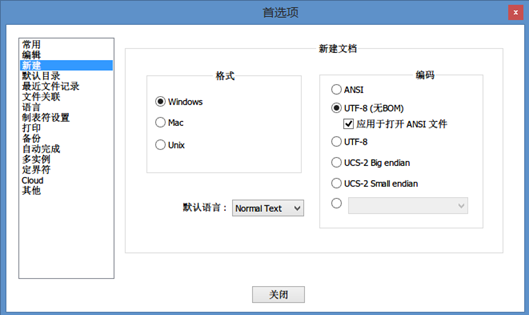
The solution in Windows is to not use Notepad in Windows and use the better Notepad++. Make sure the preferences are set as follows.
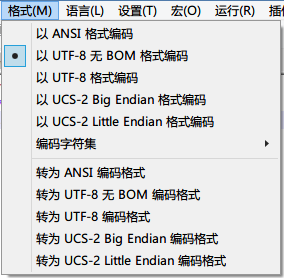
Or set the code in the menu bar
The solution in Linux, you can easily detect and remove BOM headers in Linux with vim
To detect the presence of BOM headers.
|
|
Removal of BOM headers.
Adding a BOM header is also simple.
Method for removing BOM from files using python.
Coding problems in Python and how to solve them
Python encoding and decoding
Recalling the reasons for garbled code, if there is no uniform encoding that programs can handle, then different versions of the same program need to be maintained. unicode came into existence to solve the problem between different languages, and different encodings can be converted with unicode.
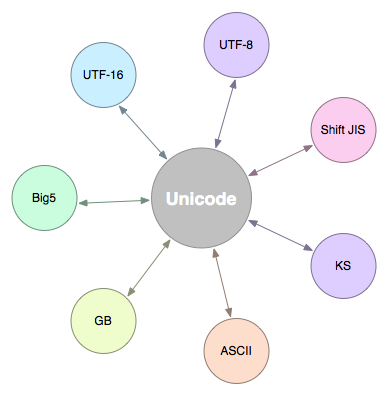
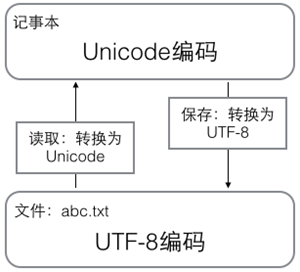
In the computer memory, Unicode encoding is used uniformly and converted to UTF-8 encoding when it needs to be saved to the hard disk or when it needs to be transferred. When editing with Notepad, UTF-8 characters read from a file are converted to Unicode characters in memory, and when editing is complete, Unicode is converted to UTF-8 when saving to a file:
When browsing the web, the server converts the dynamically generated Unicode content to UTF-8 before transferring it to the browser.
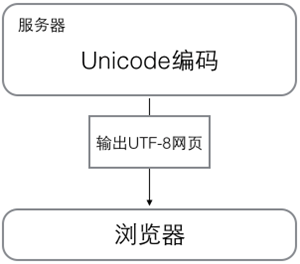
So you see a lot of web pages with something like <meta charset="UTF-8" /> on the source code, indicating that the page is encoded in UTF-8.
After we figure out the headache of character encoding, let’s look at Python’s support for Unicode. Because Python was born before the Unicode standard was released, the earliest Python only supported ASCII encoding, and the common string ‘ABC’ was ASCII encoded inside Python. can convert letters and corresponding numbers to each other.
Python’s default script files are ANSCII-encoded, so when a file contains characters that are not in the ANSCII encoding range, use the “encoding directive” to fix the definition of a module if the .py file contains Chinese characters (strictly speaking, non-anscii characters). If the .py file contains Chinese characters (strictly speaking, non-anscii characters), you need to specify the encoding declaration on the first or second line: # -- coding=utf-8 -- or #coding=utf-8
Python later added support for Unicode, and there are two kinds of strings in Python, one is str and the other is unicode, strings in Unicode are represented by u’…’, e.g.
Writing u’in’ is the same as u’\u4e2d’, \u followed by the Unicode code in hexadecimal. Therefore, u’A’ and u’\u0041’ are also the same.
English characters are converted to represent the value of UTF-8 and Unicode values are equal (but occupy different storage space), while Chinese characters are converted 1 Unicode character will become 3 UTF-8 characters, and the \xe4 you see is one of the bytes, because its value is 228, there is no corresponding letter to display, so the value of the byte is displayed in hexadecimal. len () function can return the length of a string.
We learned how to represent Unicode strings above, but the fact is that Unicode strings only exist inside the program, and there is no unified way to express them and communicate them to the outside world, so when we want to save a string in a document or pass it to someone over the network, we have to encode the Unicode string into a str string first, and on the other hand, when we want to open a document with a certain encoding, we have to decode it. The way Python encodes or decodes is very simple, through the encode and decode functions we can convert between unicode and str.
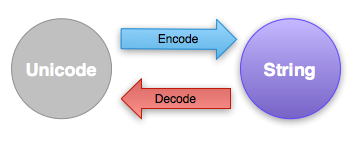
Since UTF-8 can encode any character set and has the advantage of ASCII compatibility, we usually use UTF-8 as the encoding.
What happens if you encode/decode with the wrong set of characters? The code will most likely report an error like
Python certainly supports other encoding methods, such as encoding Unicode to GB2312.
However, this approach is purely self-defeating. If there are no special business requirements, please keep in mind to use only two encoding methods, Unicode and UTF-8. In turn, convert the string ‘xxx’ represented by UTF-8 encoding to Unicode string u’xxx’ with decode(‘utf-8’) Method.
The easiest way to know whether the current string belongs to str or unicode is to use the type() function
Due to historical legacy, Python version 2.x, although supporting Unicode, requires both ‘xxx’ and u’xxx’ string representations in syntax. In Python version 3.x, ‘xxx’ and u’xxx’ are unified into Unicode encoding, i.e., writing with or without the prefix u is the same, while strings represented in byte form must be prefixed with b: b ‘xxx’.
Default encoding in Python
Python ource code file execution process
We all know that files on disk are stored in binary format, where text files are stored in some specific encoding of bytes. For example, when we use Pycharm to write Python programs, we specify the project encoding and file encoding as UTF-8, then the Python code will be written to disk after being converted to UTF-8 bytes (encoding process).
When executing the code in the Python code file, the Python interpreter reads the byte strings in the Python code file and then converts them to Unicode strings (the decode process) before performing subsequent operations.
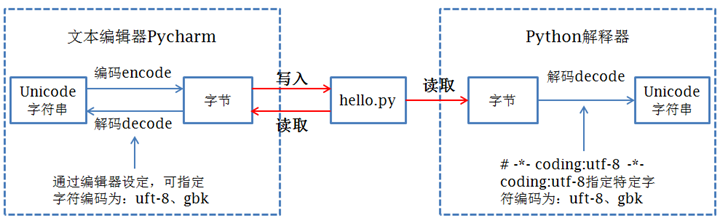
Default Encode
If we don’t specify a character encoding in the code file, which character encoding will the Python interpreter use to convert the bytes read from the code file to a Unicode string? Just as we have many default options for configuring certain software, we need to set the default character encoding inside the Python interpreter to solve this problem, which is called the “default encoding”.
Python2 and Python3 interpreters use different default encodings, and we can get the default encoding by using sys.getdefaultencoding().
For Python2, when the Python interpreter reads the byte code of Chinese characters, it will check whether the character encoding is specified in the header of the current code file first. If not specified, the default character encoding “ASCII” will be used to decode the Chinese characters, resulting in the following error.
In terms of Python3, the execution process is the same, except that the Python3 interpreter uses “UTF-8″ as the default encoding, but this does not mean that it is fully compatible with Chinese language issues. For example, when we develop on Windows, Python projects and code files use the default GBK encoding, that is, Python code files are converted into GBK format byte code and saved to disk, and when the Python3 interpreter executes the code file and tries to decode it with UTF-8, the decoding will also fail, and the following error occurs Error.
Python 2 vs Python 3 character encoding differences
Python 2
Support for strings in Python 2 is provided by the following three classes.
Both str and unicode are subclasses of basestring. Strictly speaking, str is actually a byte string, which is a sequence of bytes composed of unicode after encoding. When using the len() function on the UTF-8 encoded str ‘han’, the result is 3, because the UTF-8 encoded ‘han’ == ‘\xE6\xB1\x89 ‘. unicode is the real sense of string, obtained after decoding the byte string str using the correct character encoding and len(u’han’) == 1.
Python 3
Python 3 simplifies the support for strings at the implementation class level by removing the unicode class and adding a bytes class. On the face of it, you can think of str and unicode as one in Python 3.
In fact, Python3 has realized the previous mistake and started to explicitly distinguish between str and bytes. So str in Python3 is already a real string, while bytes are represented by a separate bytes class. In other words, Python3 defines str by default, implements built-in support for Unicode, and relieves programmers of the burden of string processing.
Compare
For the encoding of individual characters, Python provides the ord() function to obtain an integer representation of the character, and the chr() function to convert the encoding to the corresponding character:
If you know the integer encoding of the characters, you can also write str in hexadecimal like this.
The two ways of writing are exactly equivalent.
Since Python’s string type is str, represented in memory as Unicode, a character corresponds to a number of bytes. If you want to transfer it over the network, or save it to disk, you need to change str to bytes in bytes. Python represents data of type bytes by single or double quotes with a b prefix: x = b’ABC’.
Be careful to distinguish between ‘ABC’, which is str, and b’ABC’, which takes up only one byte per character of bytes, although the content is displayed the same as the former. The str expressed in Unicode can be encoded into the specified bytes by the encode() method, e.g.
Pure English str can be ASCII encoded as bytes, the content is the same, str containing Chinese can be UTF-8 encoded as bytes. str containing Chinese cannot be ASCII encoded, because the range of Chinese encoding exceeds the range of ASCII encoding, Python will report an error.
In bytes, bytes that cannot be displayed as ASCII characters are displayed with \x##. Conversely, if we read a stream of bytes from the network or disk, the data read is bytes. to change bytes to str, we need to use the decode() method.
To calculate how many characters str contains, the len() function can be used.
The len() function counts the number of characters in str. If replaced with bytes, the len() function counts the number of bytes.
As you can see, 1 Chinese character will usually occupy 3 bytes after UTF-8 encoding, while 1 English character will occupy only 1 byte. When manipulating strings, we often encounter the conversion of str and bytes to each other. To avoid garbled code problems, you should always use UTF-8 encoding for str and bytes conversion. When the Python interpreter reads the source code, in order to make it read in UTF-8 encoding, we usually write at the beginning of the file.
|
|
Conversion of character encoding
Unicode strings can be interconverted with byte strings of any character encoding, as shown in the figure.
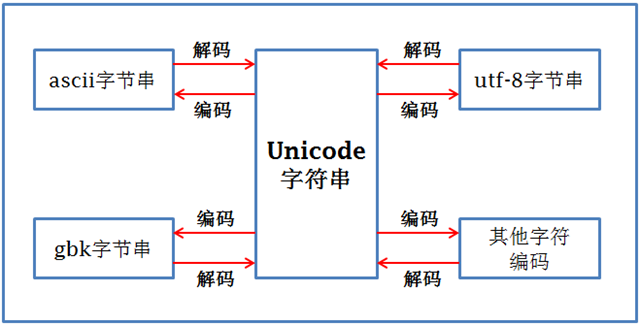
As you can see from the above diagram, different byte encodings can be converted to each other by Unicode.
The character encoding conversion process for strings in Python 2 is: byte string (Python2 str is byte string by default)->decode(‘original character encoding’)->Unicode string->encode(’new character encoding’)->byte string
Strings defined in Python 3 are unicode by default, so they can be directly encoded into the new character encoding without decoding first: string(str is Unicode string)->encode(’new character encoding’)->byte string
Encoding detection with Python
Strings are represented internally in Python as unicode encoding, so when doing encoding conversion, it is usually necessary to use unicode as an intermediate encoding, i.e. decode (decode) the string of other encoding into unicode first, and then encode (encode) from unicode into another encoding.
The role of decode is to convert the string of other encoding into unicode encoding, such as str1.decode(‘utf-8’), which means to convert the string str1 of utf-8 encoding into unicode encoding.
The role of encode is to convert unicode encoding to other encoding strings, such as str2.encode(‘gb2312’), which means the unicode encoding string str2 will be converted to gb2312 encoding. The English native term for garbled code is mojibake.
Simply put, garbled code occurs because: different or incompatible character sets are used for encoding and decoding. In real life, it is like an Englishman wrote bless (encoding process) on a piece of paper to show his blessing. And a Frenchman gets the paper, and since bless means hurt in French, he thinks he wants to express hurt (decoding process). This one is a real life messy code situation. As in computer science, a character encoded in UTF-8 is decoded in GBK. Since the character tables of the two character sets are not the same, the same character is in different positions in the two character tables, and eventually a garbled code will appear. Therefore, when transcoding, you must first figure out what encoding the string str is, then decode it into unicode, and then encode it into other encoding.
In the work, often encounter, read a file, or get a problem from the web page, the web page within the encoding is not declared or declared encoding is not accurate, when using decode to turn, always error, this time you use chardet can be very convenient to achieve the string / file encoding detection:.
The correct way to open files in Python
When Python’s built-in open() method opens a file, read() reads str, and after reading it, you need to decode() it with the correct encoding format. write() writes, and if the argument is unicode, you need to encode() it with the encoding you wish to write, or if it’s str in another encoding format, you need to first decode() it with the str in another encoding format, you need to first decode() with the encoding of that str, convert it to unicode and then encode() with the encoding you want to write. If you pass unicode directly as an argument to the write() method, Python will first encode it using the character encoding declared in the source file and then write it.
In addition, the module codecs provides an open() method to open a file with a specified encoding, and the file opened with this method will return unicode. If the parameter is str, it is first decoded into unicode according to the character encoding declared in the source file, and then the preceding operation is performed. Compared with the built-in open(), this method is less likely to have problems with encoding.
|
|
Coding problems caused by Emoji
The so-called Emoji is a character in Unicode located in the \u1F601-\u1F64F block. This obviously exceeds the current common UTF-8 character set range of \u0000-\uFFFF. This obviously exceeds the encoding range \u0000-\uFFFF of the current common UTF-8 character set. emoji emoticons are becoming more and more common with the popularity of IOS and the support of WeChat. Here are a few common Emoji:
Emoji Unicode Tables: http://apps.timwhitlock.info/emoji/tables/unicode
So what is the impact of Emoji character emoji on our usual development and operation? The most common problem is when you store him in the MySQL database. Generally speaking, the default character set of MySQL database is configured as UTF-8 (three bytes), while utf8mb4 is only supported after 5.5, and few DBAs take the initiative to change the system default character set to utf8mb4. Then the problem arises, when we put a character into the database that requires 4-byte UTF-8 encoding, it will report an error: ERROR 1366: Incorrect ERROR 1366: Incorrect string value: ‘\xF0\x9D\x8C\x86’ for column . If you read the above explanation carefully, then this error is not difficult to understand. We are trying to insert a string of Bytes into a column, and the first byte of the string is \xF0 which means it is a four-byte UTF-8 encoding. But when the MySQL table and column character set is configured as UTF-8 it is not possible to store such characters, so an error is reported.
So how do we solve this situation? There are two ways: upgrade MySQL to version 5.6 or higher and switch the table character set to utf8mb4. The second way is to do a filter before storing the content into the database, replacing the Emoji characters with a special text encoding, and then storing it into the database. After that, we can get it from the database or display it in the front-end, and then convert this special text encoding into Emoji. For the second method, let’s assume that the 4-byte Emoji is replaced with --1F601--, see How to filter (or replace) unicode characters that would take more than 3 bytes in UTF-8?