Most of the company’s applications are developed in JAVA, so it is very difficult to use Python models, but after searching online, we can convert the generated models into PMML files and call them directly in JAVA.
PMML Introduction
Predictive Model Markup Language (PMML) is an XML-based format standard for storing models proposed by Dr. Robert Lee Grossman. PMML provides a way for different data analysis software or programming languages to easily share predictive models. It supports common models, such as logistic regression and feedforward neural networks.
PMML is a platform- and environment-independent model representation language, and is the current de facto standard for representing machine learning models. From PMML 1.1, released in 2001, to the latest 4.4 in 2019, the PMML standard has been extended from the original 6 models to 17 models and provides Mining Models to combine multiple models. As an open and mature standard, PMML is developed and maintained by the Data Mining Group (DMG), a data mining organization, and has been widely used after more than a decade of development, with more than 30 vendors and open source projects (including SAS, IBM SPSS, KNIME, RapidMiner and other mainstream vendors) supporting and applying PMML in their data mining analysis products. support and apply PMML in their data mining analysis products.
Role of PMML
The go-live process of a machine learning mainly includes: analysis, feature engineering, model training, tuning, and go-live. Among them, the convenience of PMML is mainly reflected in the process of model go-live.
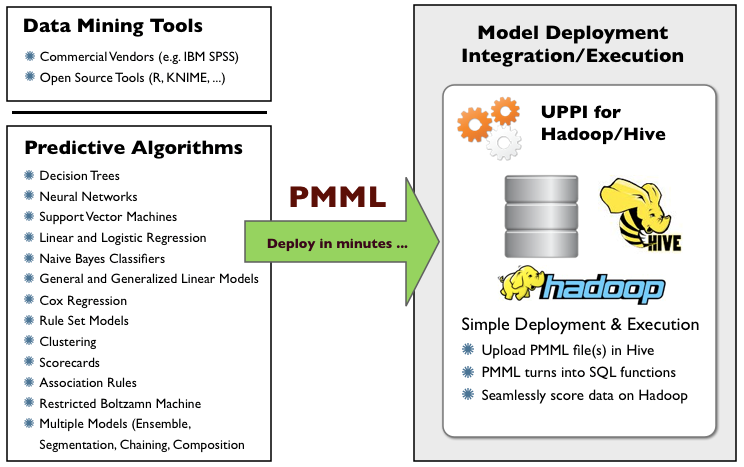
Model go-live is the process of effectively applying a trained model to a production environment. In general, there is a huge gap between the production environment and the environment used by data analysts.
For example, online DMPs are based on Hadoop, with Spark + MR as the computational framework, while offline people model mainly with R, sklearn libraries in Python, and partially with keras. translation process that is prone to errors and misrepresentations. In addition, engineering staff with a very deep understanding of the model structure is required. For example, migrating LR in R to Java requires engineering staff to write a JAVA class bare bones based on the parameters of the trained model.
The simplest LR, for example, is a data representation of a weight vector, and an activation function after multiplying the weight vector and the parameter vector. But a more complex model requires an engineer with a very deep understanding of the model structure to write the class strictly according to the computational logic of the model.
With PMML, it is easy to share models from application A to B to C, and to bring them online quickly after training is complete (simply by replacing the model files). The current practice is that offline analysts, after training a version of the model using R, etc., export it as PMML and simply replace that PMML file online.
PMML contains data pre-processing and data post-processing (i.e. processing of model prediction results) and the prediction model itself, see the following figure.

The structure of the PMML file follows the common steps used to build predictive models.
- Text header: contains basic information about the PMML document, such as the copyright information of the model, the description of the model, and information about the software used to generate the document (e.g., the name and version of the software). The header file will also contain the generation time of this PMML file.
- Data dictionary: contains all the field names that may be used by the model. It also defines the types of the fields, which can be continuous, categorical, ordinal. and the type of field value, such as String, Double.
- Data mining schema: Data mining schema, can be seen as a gatekeeper of the model. All data entering the model must go through the data mining schema. Each model contains and only contains one data mining schema for listing the data used by that model. Data mining schemas contain information that is different for a particular model, as opposed to the data dictionary where the definitions are stable and do not change as the model changes. The main purpose of a data mining schema is to list the data needed to use the model. The data mining schema also defines the usage of each field (activation, append, target) and the strategy for null values, illegal data.
- Data transformation: The data transformation operation can be used to pre-process the data before it enters the model. PMML defines the following simple data transformation operations: normalization, discretization, value mapping, custom functions, aggregation.
- Model: contains the definition and structural information of the model.
- Output: defines the model output. For a classification task, the output can include the predicted classes and the probabilities associated with all possible classes.
- Goal: defines the post-processing step applied to the model output. For a regression task, this step supports the transformation of the output into scores (predicted outcomes) that one can easily understand.
- Model Interpretation: defines the performance metrics obtained when passing test data to the model (as opposed to training data). These metrics include field correlations, confusion matrices, gain plots, and receiver operating characteristic (ROC) plots.
- Model validation: An example set containing the input data records and the expected model output is defined. This is a very important step because the model needs to pass the matching test when moving it between applications. This ensures that, when presented with the same inputs, the new system can generate the same outputs as the old system. If this is actually the case, a model will be considered validated and ready to be used in practice.
Benefits of PMML
- Platform-independence. PMML allows the model deployment environment to be detached from the development environment, enabling cross-platform deployment, which is the biggest advantage of PMML that distinguishes it from other model deployment methods. For example, a model built in Python can be deployed in a Java production environment after exporting PMML.
- Interoperability. This is the biggest advantage of the standard protocol, which implements that PMML-compatible prediction programs can read standard PMML models exported by other applications.
- Broad supportability. Support has been obtained from over 30 vendors and open source projects, and many heavyweight popular open source data mining models can be converted to PMML through multiple open source libraries already available.
- PMML models are XML-based text files that can be opened and viewed with any text editor, making them more secure and reliable than binary serialized files.
Disadvantages of PMML
- Not all data pre-processing and post-processing operations are supported. Although PMML has supported almost all standard data processing methods, it lacks effective support for some user-defined operations, which are difficult to put into PMML.
- Limited model type support. In particular, it lacks support for deep learning models. PMML will add support for deep models in the next version 0. Currently Nyoka can support deep models such as Keras, but the generated model is an extended PMML model.
- PMML is a loose specification standard, some vendors generate PMML that may not quite match the Schema defined by the standard, and the PMML specification allows vendors to add their own extensions, all of which create some barriers to using these models.
Use of PMML
Using LightGBM as an example.
Export the generated model to txt format
|
|
Convert the txt model to pmml format using the tool
|
|
called directly in JAVA code
Note, you need to introduce the following rack package before calling: https://github.com/jpmml/jpmml-evaluator, sample code.
|
|
PMML toolset
Model conversion library to generate PMML files
Python models.
- Nyoka, which supports Scikit-Learn, LightGBM, XGBoost, Statsmodels, and Keras.
- JPMML series, such as JPMML-SkLearn, [JPMML-XGBoost](https: //github.com/jpmml/jpmml-xgboost), JPMML-LightGBM, etc., which provide command line programs to export models to PMML.
R models.
Spark.
Model evaluation library, read PMML
Java.
- JPMML-Evaluator, a pure Java PMML prediction library, the open source protocol is AGPL V3.
- PMML4S, developed in Scala, easy to use in Scala and Java, simple and good interface, open source protocol is the commonly used loose protocol Apache 2.
Python:
- PyPMML, Python library calls PMML, PyPMML is a Python interface wrapped by PMML4S.
Spark.
PySpark:
REST API:
- AI-Serving, both REST API and gRPC API for PMML models, open source protocol Apache 2.
- Openscoring, providing REST API, open source protocol AGPL V3.