This paper presents a paper from the 2011 NSDI journal – Mesos: A Platform for Fine-Grained Resource Sharing in the Data Center, which implements Mesos to manage different computing frameworks, such as Hadoop and MPI, in a cluster. Although the Mesos cluster management system is a technology that was released more than 10 years ago and has been gradually replaced today by the more mainstream and general container orchestration system Kubernetes, it does solve some of the cluster management problems.
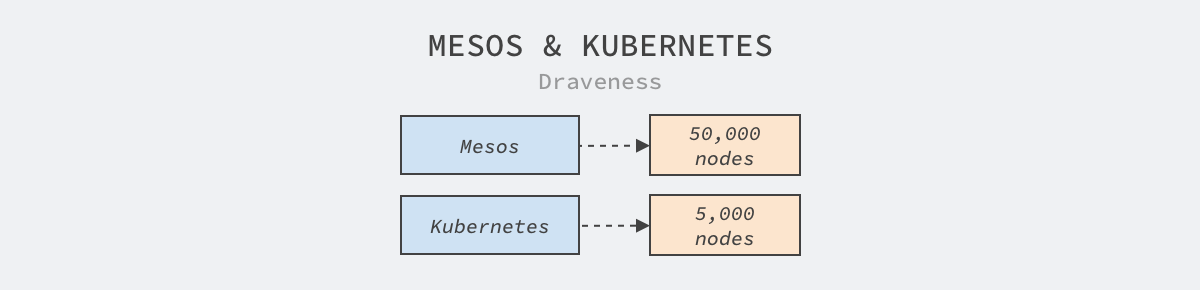
Apache Mesos and Kubernetes are both excellent open source frameworks and both support large-scale cluster management, but there is still an order of magnitude difference in the size of the clusters they both manage - a single Mesos cluster can manage 50,000 nodes, while a Kubernetes cluster can only manage 5,000 nodes, requiring many optimizations and limitations to reach the same order of magnitude.
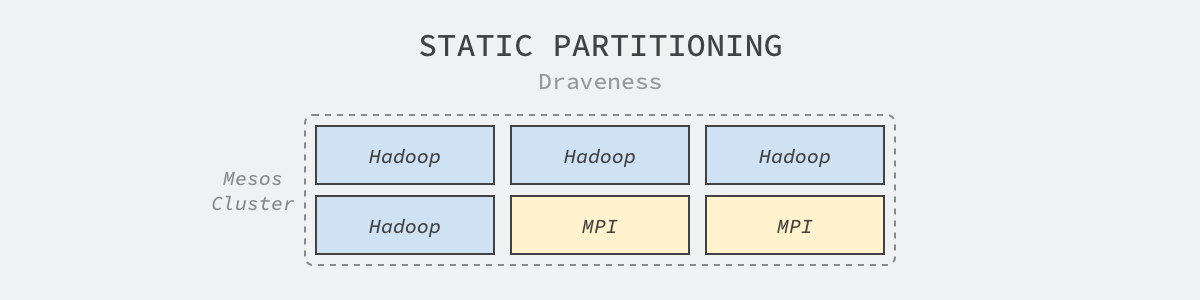
While Kubernetes is the dominant technology for cluster management today, Mesos was also a very advanced cluster management system when it first emerged, and it was intended to replace the then more common statically sharded clusters. While statically sharded clusters can run workloads belonging to different frameworks simultaneously (e.g., Hadoop, MPI), because of the heterogeneous nature of the frameworks, using statically sharded technologies pre-allocates the machines in the cluster to different frameworks, which in turn allocate and manage resources.
Mesos was not originally designed to directly manage and schedule developer-submitted workloads, but rather to provide a set of interfaces that expose the cluster’s resources and interface to frameworks such as Hadoop and MPI simultaneously through this lightweight set of interfaces.
Architecture
The Mesos cluster shown in the figure below runs both Hadoop and Mesos frameworks. If we ignore the modules related to Hadoop and MPI frameworks in the figure, we will find that the architecture becomes very simple and it consists of only Zookeeper cluster, Mesos master node and worker nodes.
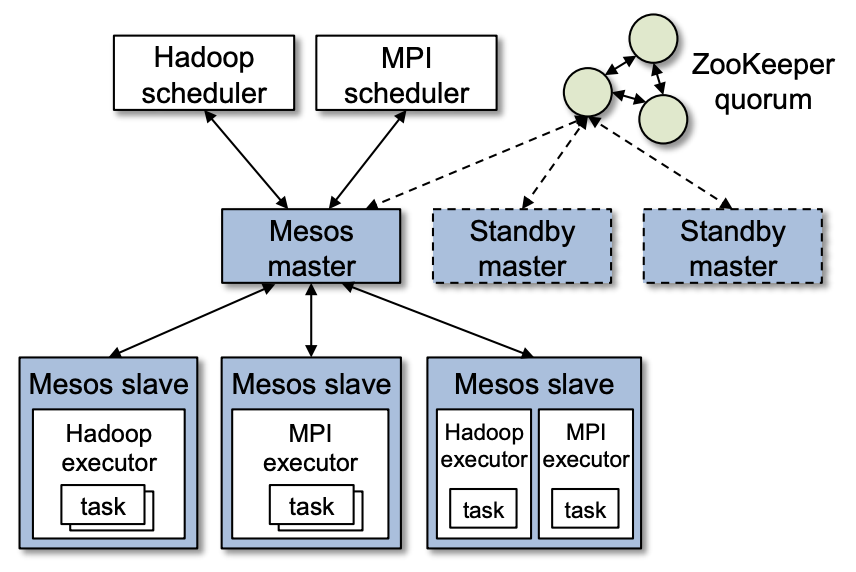
- Zookeeper clusters provide functions such as highly available data storage and elections.
- Mesos master nodes collect data reported by worker nodes and provide resources to the framework’s scheduler.
- Mesos worker nodes report data and initiate tasks locally through the framework’s executor.
The framework running in each Mesos cluster consists of two parts: the scheduler handles the resources provided by the master node and has the same role as the scheduler of Kubernetes. When the scheduler accepts the resources provided by the master node, it returns information about the tasks to be run; and the executor runs the tasks created by the framework on the worker nodes.
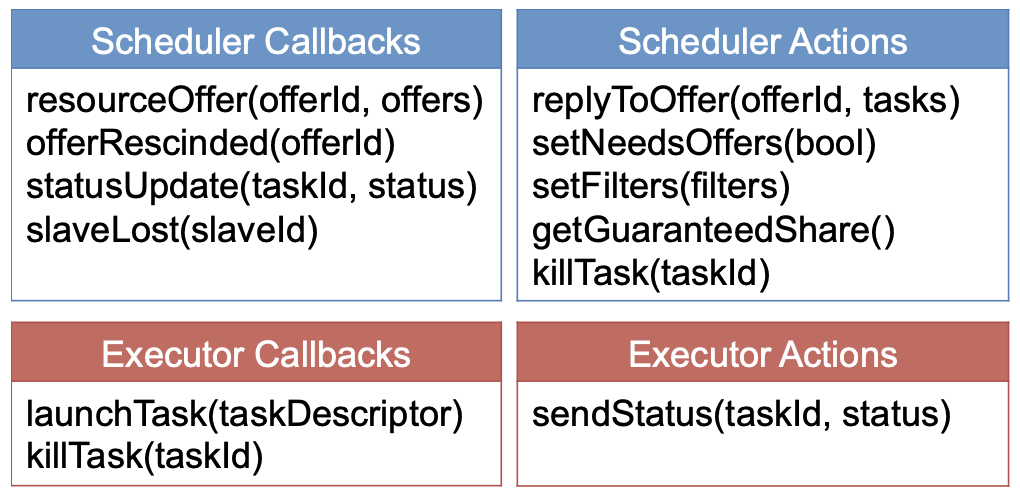
To ensure better scalability, Mesos defines a minimal set of interfaces that can accommodate resource sharing, giving control of task scheduling and execution to the framework through the interfaces shown below, while retaining only coarse-grained scheduling and resource management functions itself.
Because task scheduling in Mesos is a distributed process, it introduces the following three mechanisms to ensure the efficiency and reliability of the process.
- node filters: the framework uses filters to eliminate nodes in the cluster that do not satisfy its own scheduling conditions.
- resource active allocation: to improve the scheduling speed of the framework, resources provided to the framework in advance are counted towards the framework’s total allocated resources until the framework completes scheduling, which can incentivize the framework to implement a faster scheduler.
- resource withdrawal: if the framework does not process the resources provided by the master node for a period of time, Mesos withdraws the resources and makes them available to other frameworks.
In addition to providing good scalability and performance, Mesos, as a cluster scheduling management system, also faces the problem of isolating resources for different tasks. When Mesos was first released, container technology was not as popular as it is today, but it also utilized containers for operating systems to isolate the impact of different workloads and supported multiple isolation mechanisms with pluggable isolation modules.
Scheduling Model
We already covered the order of magnitude difference in cluster size that Mesos and Kubernetes can manage at the beginning of this article, so here’s a brief comparative analysis of the differences between the two in terms of schedulers, which helps us understand the decisions that the Kubernetes scheduler makes at design time, and how those decisions affect its scalability.
Note that improving system scalability is often a complex problem, and it can be even more complex in a system as large as Kubernetes, where the scheduler is not the only factor that affects scalability.
Mesos’ scheduler opts for a two-tier scheduling design, where the top-level scheduler only coarsely filters the nodes in the cluster based on the needs of the underlying framework scheduler, while the framework scheduler performs true task scheduling, binding tasks to the appropriate nodes.
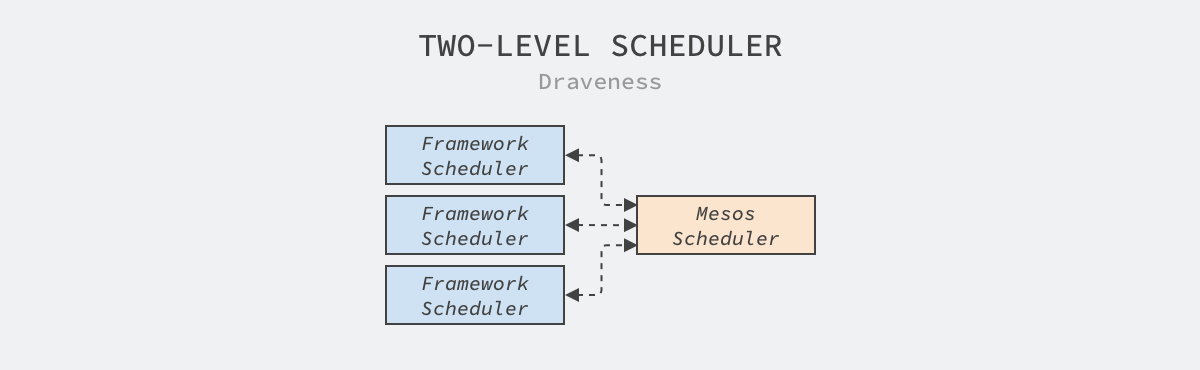
This two-tier scheduler design may seem complex, but it actually reduces the complexity and increases the scalability of the Mesos scheduler by
- Reduced complexity: the top-level scheduler does not need to handle the real scheduling process; it only hands over a set of nodes to the control of the bottom-level scheduler through the Resource Offer mechanism.
- Improved scalability: the two-tier scheduler design allows for easier access to new framework schedulers, compatibility with different complex scheduling policies, and the ability to serially select nodes for tasks within different framework schedulers, improving overall scheduling throughput.
While Mesos provides great scalability with its two-tier scheduler design, it does not provide globally optimal solutions for scheduling decisions. This is because all scheduling decisions are made in a portion of nodes in the whole cluster and all scheduling decisions are only locally optimal, which is a common problem in multi-schedulers.
To achieve better scalability in a scheduling system one must face slicing, which inevitably leads to a scheduler that does not provide a globally optimal solution and significantly increases the complexity of the system. We can observe this from the evolution of CPU schedulers in Linux, Go languages, etc. Most of the original schedulers were single-threaded, and in order to improve the performance of the scheduler, multiple schedulers were used and work-stealing mechanisms were introduced to handle the imbalance of queues of tasks to be scheduled in multiple schedulers.
The built-in scheduler in Kubernetes v1.21 is still single-threaded, and it needs to traverse and sort these 5,000 nodes using different plugins in order to make the optimal scheduling decision among the global 5,000 nodes, which is one of the major reasons that affects its scalability. The global optimal solution sounds like a very nice design, but in more complex scenarios like scheduling, the local optimal solution can often meet the requirements as well, and when there is no business need to guarantee that constraint, the performance can be improved by multiple schedulers.
Summary
When comparing resource utilization between Mesos and statically sharded clusters, we see that Mesos has significantly higher cluster resource utilization in both CPU and memory than clusters using static sharding, and this result is not too surprising because dynamic resource allocation strategies generally improve cluster resource utilization.

Understanding the problems Mesos solved when it emerged and how it was designed allows us to better understand the challenges we face today. Mesos was a very new technology when it first emerged and did offer a lot of flexibility compared to other products of the same time, but with the emergence of technologies like Yarn and Kubernetes, many of its scenarios have been replaced by new technologies, and this is an inevitable trend in technology development.