Implicit Introduction
Implicit is an open source collaborative filtering project that contains a variety of popular recommendation algorithms, with the main application scenario being recommendations for implicit feedback behaviors. The main algorithms included are.
- ALS (alternating least squares)
- BRP (Bayesian Personalized Ranking)
- Logistic Matrix Factorization
- Nearest neighbor model using Cosine, TF-IDF or BM25
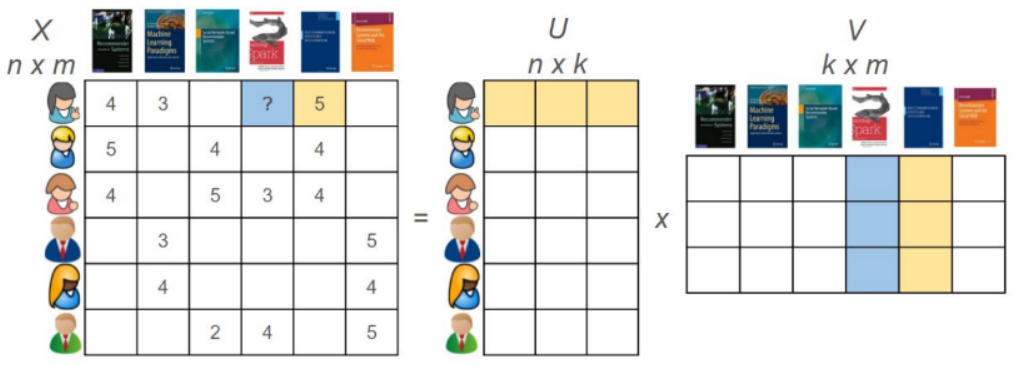
Implicit use
Data preparation
Implicit input needs to use the data format of user_id/item_id/rating, where for implicit rating scenarios, it can be set according to the specific situation, for example.
- Set different rating according to browsing time
- Different ratings according to the depth of browsing (whether or not you have seen the images, reviews, etc.)
- Set different ratings according to different behaviors (browsing, favorites, adds)
Model training
|
|
Notes.
- The ALS algorithm is used here, and there is no good solution for how to tune the specific model parameters, and the parameters given are given arbitrarily.
- Here the model results are stored in the .npz file, which is easy to use directly at a later stage, instead of being trained every time it is used.
- Need to recode the original user_id, item_id, otherwise it will report an error
Model use
|
|
Recommendation in real time
The real-time recommendation solution uses an offline model combined with real-time behavior to make recommendations, rather than deploying the entire model to run online in real-time. The main difference in the middle is that the user ID does not exist, so direct recommendations cannot be made using the userid. The specific implementation is as follows.
|
|
Reference.
- https://github.com/benfred/implicit
- https://implicit.readthedocs.io/en/latest/index.html
- https://github.com/redbubble/pyrec
- Predicting User Preferences in Python using Alternating Least Squares
- Building a Collaborative Filtering Recommender System with ClickStream Data
- ALS Implicit Collaborative Filtering