In computer science, fuzzy string matching is a technique for finding a string that matches a pattern approximately (rather than exactly). In other words, fuzzy string matching is a search that finds a match even if the user misspells a word or enters only part of a word to search. Therefore, it is also known as string approximate matching.
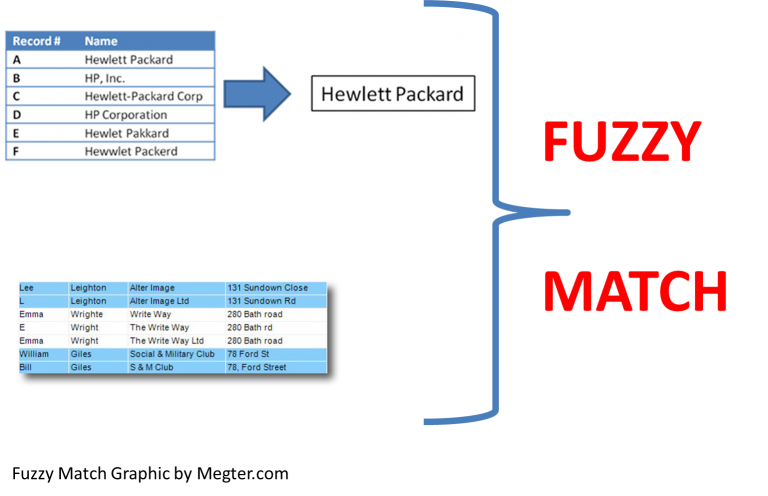
String fuzzy search can be used in various applications, such as
- Spell checkers and spelling error correctors. For example, if a user types “Missisaga” into Google, a hit list with the text “Showing results for mississauga” will be returned. This means that the search query will return results even if the user enters missing characters, has extra characters, or has other types of spelling errors.
- Duplicate record checking. For example, names are listed multiple times in the database because they are spelled differently (e.g. Abigail Martin and Abigail Martinez).
This article will explain string fuzzy matching and its use cases, and give examples using the Fuzzywuzzy library in Python.
Merge hotel room types using FuzzyWuzzy
Every hotel has its own way of naming its rooms, and so do online travel agencies (OTAs). For example, a room at the same hotel Expedia calls “Studio, 1 King Bed with Sofa Bed, Corner”, while Booking.com simply shows it as “Corner King Studio”. I can’t say anyone is wrong, but this can lead to confusion when we want to compare rates between OTAs, or when one OTA wants to make sure another OTA is following a rate parity agreement. In other words, in order to be able to compare prices, we have to make sure that what we are comparing is the same type of thing. One of the most headline-grabbing problems for price comparison sites and apps is trying to figure out if two items (like a hotel room) are the same thing.
Fuzzywuzzy is a Python library that uses an edit distance (Levenshtein Distance) to calculate the difference between sequences. To demonstrate, I created my own dataset, i.e., for the same hotel property, I took a room type from Expedia, say “Suite, 1 King Bed (Parlor)”, and I matched it with a room of the same type from Booking.com, i.e. “King Parlor Suite”. With a little experience, most people will know they are the same. Following this approach, I created a small dataset containing over 100 pairs of room types, which can be accessed at Github download.
We used this dataset to test Fuzzywuzzy’s approach. In other words, we use Fuzzywuzzy to match records between two data sources.
There are several ways to compare two strings in Fuzzywuzzy, let’s try them one by one.
ratio , comparing the similarity of the whole strings in order
Returning a result of 62, it tells us that “Deluxe Room, 1 King Bed” is about 62% similar to “Deluxe King Room”.
The similarity between “Traditional Double Room, 2 Double Beds” and “Double Room with Two Double Beds” is about 69%. “Room, 2 Double Beds (19th to 25th Floors)” and “Two Double Beds - Location Room (19th to 25th Floors) “Similarity is about 74%. Obviously the results were not good. The simple method proved to be too sensitive to small differences in word order, missing or redundant words, and other similar issues.
partial_ratio, comparing the similarity of partial strings
We are still using the same data pairs.
Returns 69, 83, 63 in that order. for my dataset, comparing partial strings doesn’t give better overall results. Let’s try the next one.
token_sort_ratio, ignoring word order
Returns 84, 78, 83 in that order. this is by far the best
token_set_ratio, de-duplicate subset matching
It is similar to token_sort_ratio, but more flexible.
Returns 100, 78, 97 in that order. it seems token_set_ratio fits my data best. Based on this finding, token_set_ratio is applied to the entire dataset.
When setting the similarity > 70, more than 90% of the room pairs exceed this match score. Not bad at all! The above only does a similarity comparison between 2 texts, how do I handle it if there are more than one? You can use the Process class provided in the library.
It is used to return the fuzzy matching string and similarity.
FuzzyWuzzy in Chinese scenarios
FuzzyWuzzy supports comparison of Chinese language.
A closer look at the code shows that there are still problems with.
- FuzzWuzzy doesn’t split words for Chinese
- It also does not filter for some deactivated words in Chinese
Improvements to the solution, Chinese processing before processing.
- Traditional and simplified conversion
- Chinese word splitting
- Removing deactivated words
Reference links.