Kubernetes is a very complex cluster orchestration system, yet even though it contains rich functionality and features, it cannot meet the needs of all scenarios because of the inherent high complexity of container scheduling and management. While Kubernetes can solve most of the common problems in most scenarios, in order to achieve a more flexible strategy, we need to use the scalability provided by Kubernetes for specific purposes.
Each project will focus on different features at different cycles, and we can simply divide the evolution of the project into three distinct phases.
- Minimum Availability: early on, projects tend to solve generic, common problems and give out-of-the-box solutions to attract users, when the code base is still relatively small and provides more limited functionality that can cover 90% of the scenarios in the domain.
- Functional perfection : As the project gets more users and supporters, the community will continue to implement relatively important features, and the community governance and automation tools will gradually become perfect, able to solve 95% of the scenarios covered.
- Scalability: As the project community becomes more complete, the code base becomes progressively larger, every change to the project affects downstream developers, and any new feature added requires discussion and approval by community members, at which point the community chooses to enhance the scalability of the project, allowing users to customize requirements for their own scenarios, capable of solving 99% of the scenarios covered.

From 90%, 95% to 99%, each step requires a lot of effort from the community members, but even providing good scalability cannot solve all the problems in the domain, and in some extreme cases it is still necessary to maintain your own branch or start a new one to meet the business needs.
However, either maintaining your own branch or starting a new one will incur high development and maintenance costs, which requires a choice based on actual requirements. But being able to leverage the configurability and scalability provided by the project can significantly reduce the cost of customization, and today we’re going to look at Kubernetes scalability.
Extending Interfaces
The API server is a core component in Kubernetes that carries the burden of reading and writing resources in the cluster. While the resources and interfaces provided by the community can meet most of the daily needs, there are still scenarios where we need to extend the capabilities of the API server, and this section briefly describes a few ways to extend the service.
Custom Resources
Custom Resource Definition (CRD) is supposed to be the most common way to extend Kubernetes 1, and it is the most common way to extend the The Kubernetes API is the YAML we submit to the cluster, and the components of the system launch applications, create network routing rules, and run workloads based on the submitted YAML.
Pods, Services, and Ingress are all interfaces that Kubernetes exposes to the outside world, and when we commit the YAMLs in the cluster, the controller in Kubernetes will create containers that meet the conditions based on the configuration.
|
|
However, CRD is only the tip of the iceberg for implementing custom resources, as it only defines the fields in the resources. We also need to follow the Kubernetes controller model and implement the Operator that consumes CRD to achieve more complex and advanced features by combining the resources provided by Kubernetes.
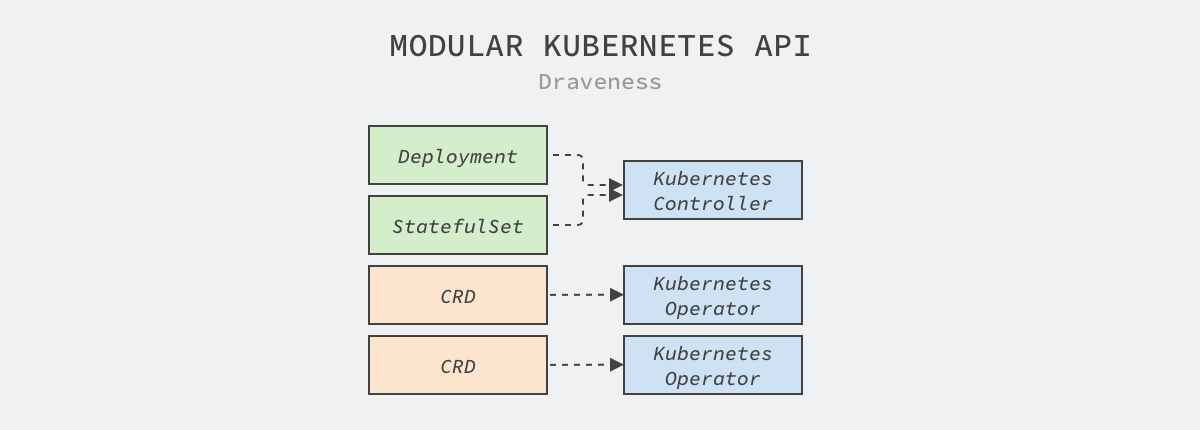
As shown above, components such as controllers in Kubernetes consume resources such as Deployment and StatefulSet, while user-defined CRDs are consumed by their own implemented controllers. This design greatly reduces the coupling between the various modules of the system, allowing different modules to work together seamlessly.
When we want a Kubernetes cluster to provide more complex functionality, choosing CRDs and controllers is the first approach to consider. This approach has very low coupling with existing functionality and is also highly flexible, but elegant interfaces should be designed following community API best practices when defining interfaces
Aggregation Layer
The Kubernetes API aggregation layer is a feature implemented in v1.7 that aims to split the monolithic API server into multiple aggregated services, with each developer able to implement the aggregated API services to expose the interfaces they need, a process that does not require recompiling any of the Kubernetes code
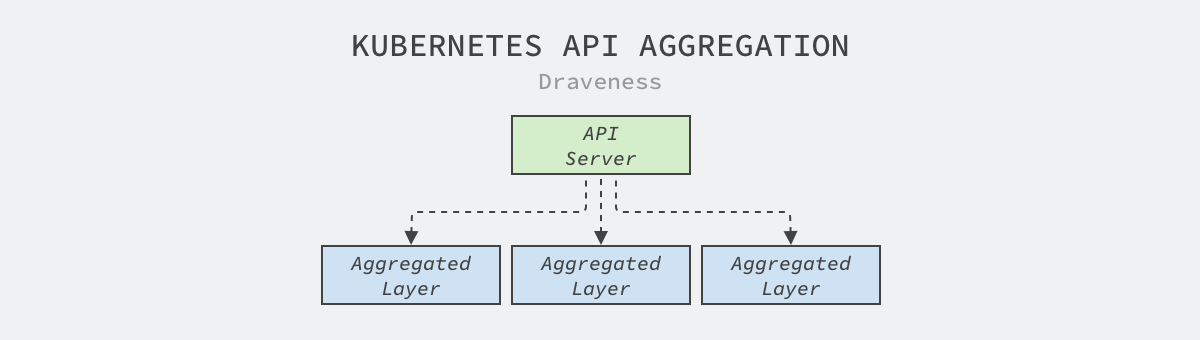
When we need to add a new API aggregation service to the cluster, we need to submit an APIService resource that describes the group to which the interface belongs, the version number, and the service that handles the interface, as shown in the following APIService corresponding to the metrics-server service in the Kubernetes community.
If we commit the above resources to a Kubernetes cluster, when users access the /apis/metrics.k8s.io/v1beta1 path of the API server, they will be forwarded to the metrics-server.kube-system.svc service in the cluster.
Compared to CRD, which has a wide range of applications, the API aggregation mechanism is less common in projects where its main purpose is still to extend the API server, and most clusters will not have similar needs, so I won’t go into it here.
Access Control
Kubernetes’ access control mechanism modifies and validates the resources that will be persisted by the API server, and all write requests received by the API server are persisted to etcd in the following stages
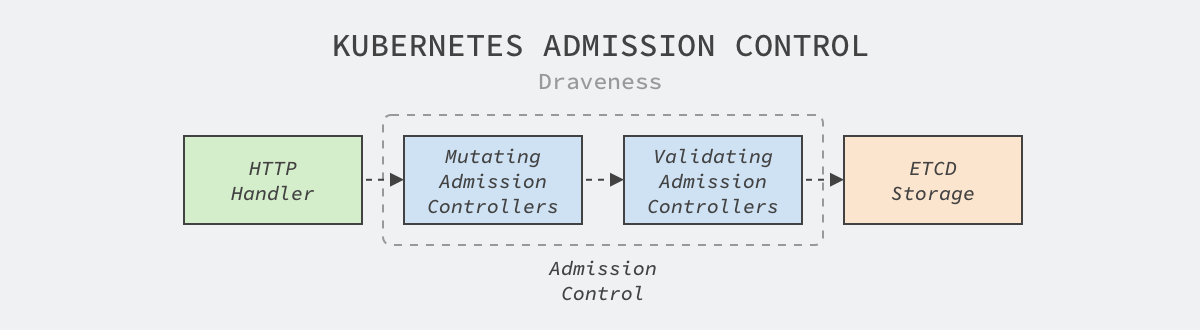
The Kubernetes code repository contains more than 20 access control plugins, let’s take the TaintNodesByCondition plugin as an example and briefly introduce their implementation principles
|
|
All access control plugins can implement the Admit method above to modify resources that are about to be committed to storage, the Mutating modification phase mentioned above, which adds a NotReady taint to all incoming nodes to ensure that no tasks are scheduled to the node during the update; in addition to the Admit method, plugins can also implement the Validate method to verify the legitimacy of incoming resources.
Implementing a custom access controller in Kubernetes is relatively complex. We need to build an API service that implements the access control interface and register the API service with the MutatingWebhookConfiguration and ValidatingWebhookConfiguration resources to the cluster. Istio, one of the more popular service grids in the Kubernetes community, uses this feature to implement some functionality
Container Interface
Kubernetes’ main logic as a container orchestration system is still scheduling and managing containers running in a cluster, and while it doesn’t need to implement a new container runtime from scratch, it has to deal with modules like networking and storage because they are necessary for containers to run. Kubernetes chose the approach of designing the network, storage and runtime interfaces to isolate the implementation details, focusing on container orchestration itself, and letting the third-party community implement these complex and highly specialized modules.
Network plugins
The Container Network Interface (CNI) contains a set of interfaces and frameworks for developing plugins to configure NICs in Linux containers.
The CNI focuses only on the container’s network connectivity and reclaims all allocated network resources when the container is deleted

Although CNI plugins are closely related to Kubernetes, different container management systems can use CNI plugins to create and manage networks, e.g., mesos, Cloud Foundry, etc.
All CNI plugins should implement binary executables containing ADD, DEL and CHECK operations, and the container management system will execute the binaries to create the network.
In Kubernetes, whichever network plugin is used needs to follow its network model. In addition to the need for each Pod to have a separate IP address, Kubernetes also makes the following requirements for the network model.
- Pods on any node to access all Pods on all nodes without using NAT.
- Services such as Kubelets and daemons on a node have access to other Pods on the node.
|
|
Developing CNI plugins is very remote for most engineers. Under normal circumstances, we just need to choose among some common open source frameworks based on requirements, such as Flannel, Calico, and Cilium, etc. When the size of the cluster becomes very large, it is also natural for network engineers to work with Kubernetes developers to develop the appropriate plugins.
Storage Plugins
Container Storage Interface (CSI) is a new feature introduced by Kubernetes in v1.9, which was stabilized in v1.13. The common container orchestration systems Kubernetes, Cloud Foundry, Mesos and Nomad all choose to use this interface Extending the storage capacity of containers in a cluster.

CSI is the standard for exposing block and file storage to containerized workloads in container orchestration systems, and third-party storage providers can provide new storage in Kubernetes clusters by implementing the CSI plugin.
The Kubernetes development team gives best practices for developing and deploying CSI plug-ins in the CSI documentation, with the primary effort being to create containerized applications that implement the Identity, Node, and optional Controller interfaces, and to provide them via the official sanity package to test the legitimacy of the CSI plug-in. The interfaces to be implemented are defined in the CSI specification.
|
|
The CSI specification document is very complex, in addition to defining in detail the request and response parameters for the different interfaces. It also defines the gRPC error codes that different interfaces should return in case of corresponding errors, and it is still cumbersome for developers to implement a plugin that follows the CSI interface exactly.
In earlier versions, Kubernetes had access to interfaces from different cloud vendors, including Google PD, AWS, Azure, and OpenStack, but as the CSI interface matures, the community will remove cloud vendor-specific implementations upstream in the future, reducing upstream maintenance costs and speeding up iteration and support for each vendor’s own storage.
Runtime Interfaces
The Container Runtime Interface (CRI) is a set of gRPC interfaces for managing container runtimes and images. It is a new interface introduced by Kubernetes in v1.5, through which Kubelets can use different container runtimes.
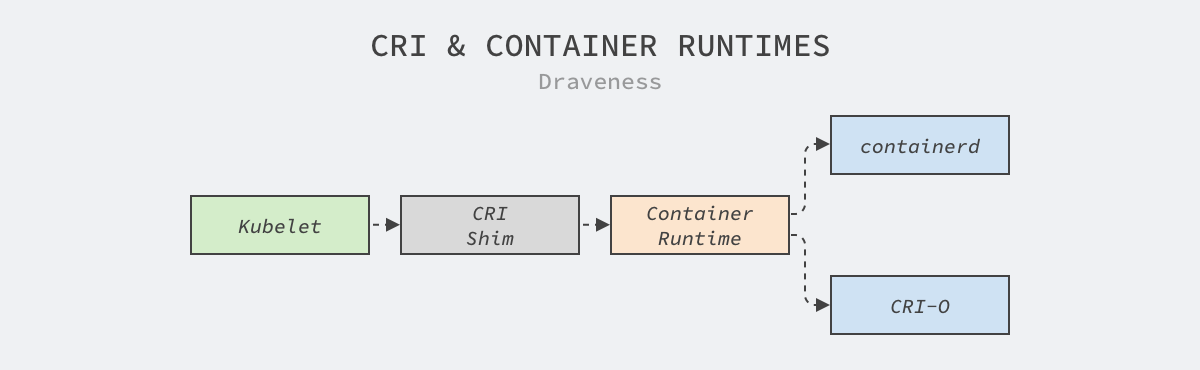
The CRI mainly defines a set of gRPC methods, and we can find two services, RuntimeService and ImageService, in the specification, whose names explain their respective roles very well.
|
|
The container runtime interfaces are relatively simple. The above interfaces not only expose Pod sandbox management, container management, and command execution and port forwarding, but also contain multiple interfaces for managing mirrors, and the container runtime can provide services for Kubelet by implementing the above 20 or 30 methods.
Device plug-ins
CPU, memory, and disk are common resources on the host, however, with the development of big data, machine learning, and hardware, some scenarios may require heterogeneous computing resources, e.g., GPUs, FPGAs, and other devices. The emergence of heterogeneous resources requires not only the support of the node agent Kubelet, but also the cooperation of the scheduler. In order to be well compatible with the different computing devices that emerge later, the Kubernetes community has introduced the Device Plugin upstream to support the scheduling and allocation of multiple types of resources.
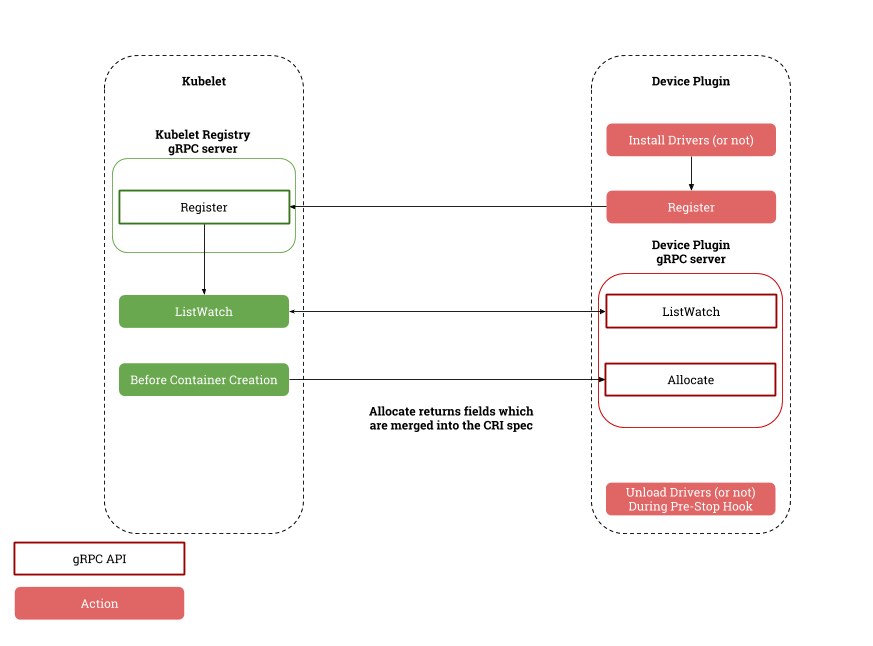
Device plugins are services that run independently of Kubelet, registering their own information and implementing the DevicePlugin service for subscribing and assigning custom devices through the Registration service exposed by Kubelet.
|
|
When the device plugin is first started, it calls Kubelet’s registration interface to pass in its version number, Unix socket and resource name, e.g. nvidia.com/gpu; Kubelet communicates with the device plugin through the Unix socket, it continuously gets the latest status of resources in the device through the ListAndWatch interface, and allocates resources through the Allocate interface when the It will continuously get the latest status of the resources in the device through the ListAndWatch interface and allocate the resources through the Allocate interface when the Pod requests resources. The implementation logic of the device plug-in is relatively simple, and interested readers can study the implementation principles of the Nvidia GPU plug-in.
Scheduling Framework
The scheduler is one of the core components of Kubernetes. Its main role is to make optimal scheduling decisions for workloads in a set of nodes in a Kubernetes cluster, and the scheduling requirements in different scenarios are often complex, however, the scheduler does not support easy extensibility in the early days of the Kubernetes project, and only supports the scheduler extension (Extender), which is a difficult method to use.
The scheduling framework introduced in Kubernetes from v1.15 is the mainstream scheduler extension technology today, by abstracting the key extension points inside the Kubernetes scheduler and changing the scheduling decisions made by the scheduler at the extension points through plugins.
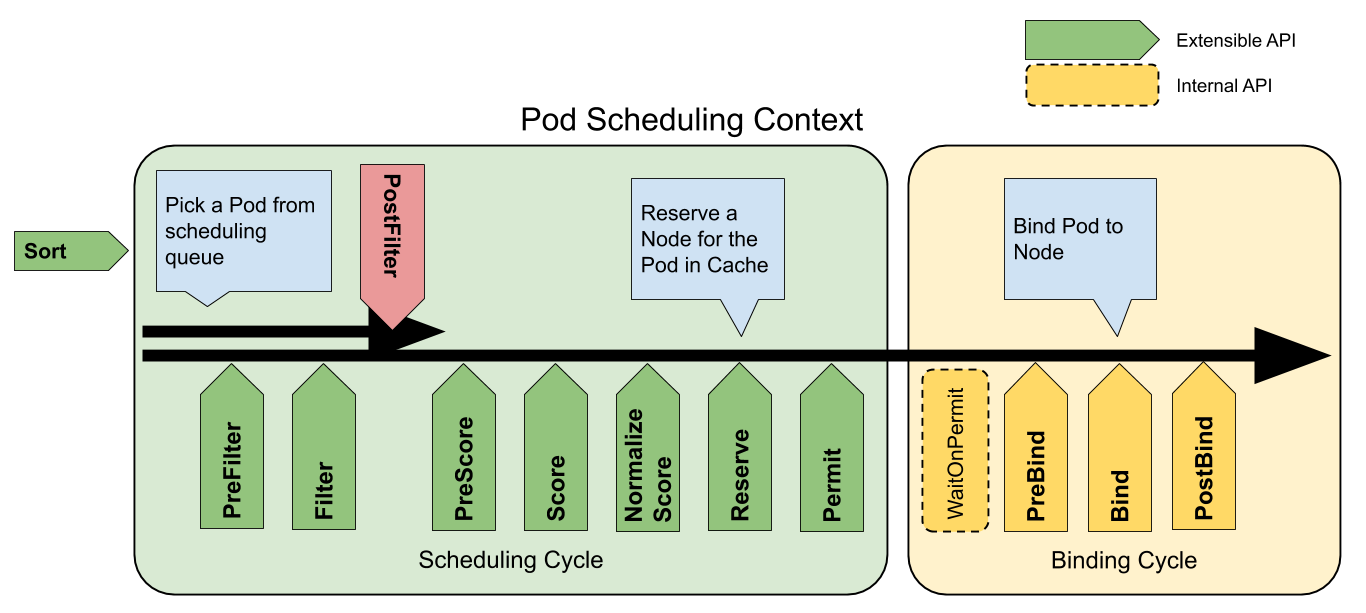
The current scheduling framework supports a total of 11 different extension points, each of which corresponds to an interface defined in the Kubernetes scheduler, and only the methods in the common interfaces FilterPlugin and ScorePlugin are shown here
|
|
The emergence of scheduling frameworks has made it easier to implement complex scheduling policies and scheduling algorithms, and the community has replaced older predicates and priorities with scheduling frameworks and implemented more powerful plugins such as collaborative scheduling and capacity-based scheduling. While today’s scheduling frameworks have become very flexible, serial schedulers may not meet the scheduling needs of large clusters, and Kubernetes currently struggles to implement multiple schedulers, and it is not known if more flexible interfaces will be provided in the future.
Summary
It’s been nearly 7 years since Kubernetes was released in 2014, and every code contributor and member of the community has responsibility from a minimally available orchestration system to the behemoth it is today. From this article, we can see that as the Kubernetes project evolves in the right direction, the community is increasingly concerned about the scalability of the system, reducing the burden on community members by designing interfaces, removing third-party code, and allowing Kubernetes to focus more on container orchestration and scheduling.