Shopee ClickHouse is a highly available distributed analytical database based on the open source database ClickHouse for secondary development and architectural evolution. This article will focus on Shopee ClickHouse’s hot and cold storage architecture and the practices that support the company’s business.
Shopee ClickHouse’s hot and cold storage architecture uses JuiceFS clients to mount remote object storage to the local machine path, and uses remote object storage as if it were multi-volume storage by writing ClickHouse storage policies. Because we use the same ClickHouse DB cluster to support the business of multiple teams, the hot and cold division of data between different teams and even different businesses of the same team may have different benchmarks, so when doing hot and cold separation policy needs to be done at the table level of ClickHouse.
In order to achieve hot and cold separation at the table level, we modify the storage policy of tables according to the storage policy edited in advance for the stock of business tables that need to do hot and cold separation. For new business tables that require hot/cold separation, we specify a storage policy that supports data on remote storage when building the tables, and then determine whether the data should be on the local or remote side by refining the TTL expressions.
After the hot and cold storage architecture went live, we encountered some problems and challenges, such as juicefs object request error, Redis memory growth exceptions, suspicious broken parts, and so on. This article will address some of these issues, contextualize the scenarios, and provide solutions through source code analysis.
In general, the overall design idea of Shopee ClickHouse hot and cold storage architecture is: local SSD storage for hot data queries and remote storage for less frequently queried data, thus saving storage costs and supporting more data storage needs.
Shopee ClickHouse Cluster General Architecture
ClickHouse is an open source OLAP (On-Line Analytic Query) type database that implements a vectorized execution engine with excellent AP query performance. shopee ClickHouse is an analytic database that continues to do second iteration development and product architecture evolution based on ClickHouse.
The following diagram shows the architecture of the Shopee ClickHouse DB cluster.
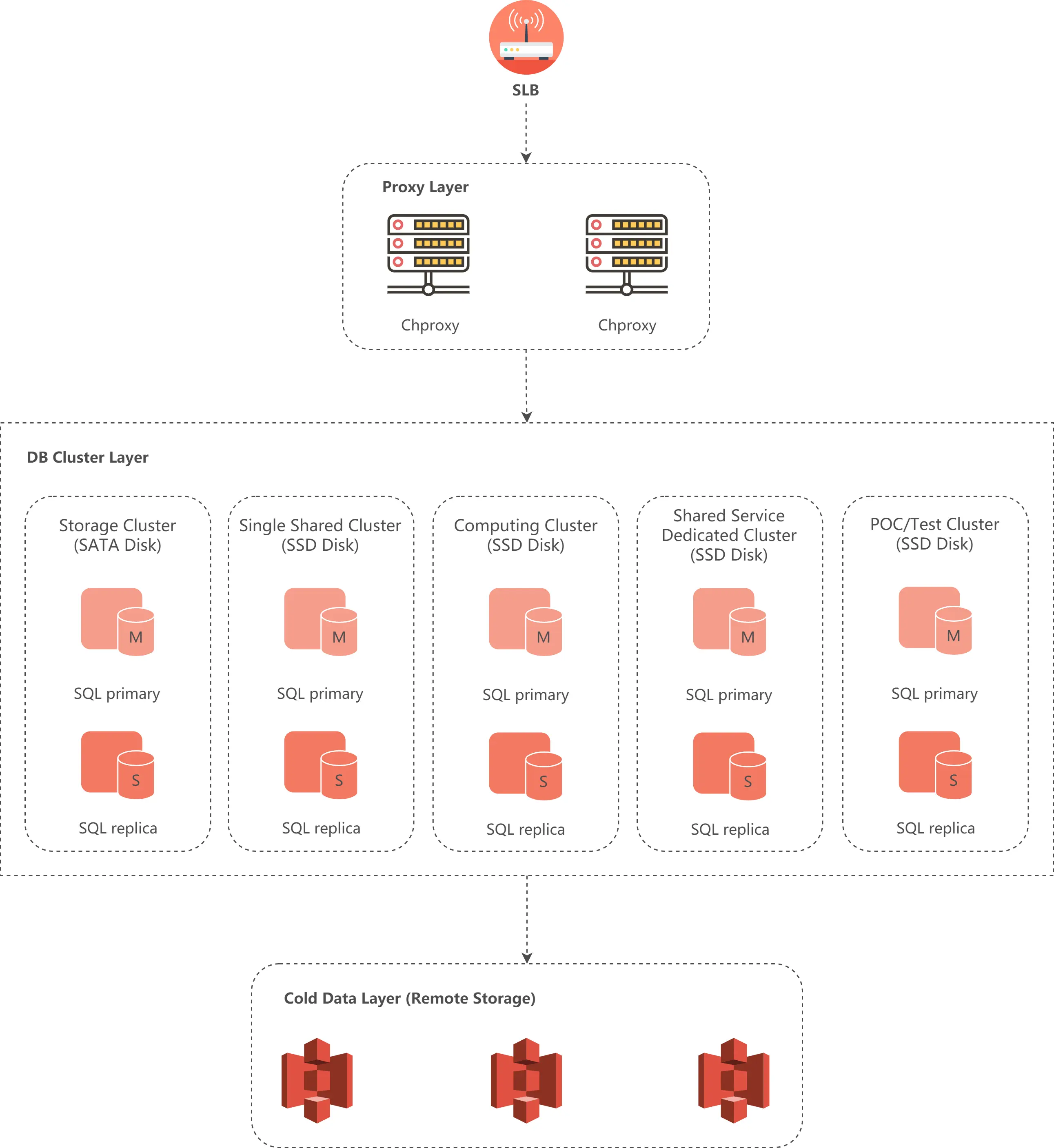
From top to bottom is the user request intervention SLB, Proxy layer, ClickHouse DB cluster layer, and at the bottom is the remote object storage, here we use S3 provided by the Shopee STO team.
Among them, SLB provides user request routing; Proxy layer provides query routing, requests will be routed to the corresponding cluster based on the cluster name in the user connection string, also provides the ability to partially write balance and query routing; ClickHouse DB cluster layer is composed of Shopee ClickHouse database distributed clusters , currently there are compute distributed clusters with SSD disks as the hot data storage medium, and compute single node clusters, and storage distributed clusters with SATA Disk as the storage medium; the bottom remote storage is used as the cold data storage medium .
Hot and cold storage architecture solutions
Users want to store more and longer data and query faster. But usually the more data is stored, the higher the return latency for the same query conditions.
In terms of resource utilization, we wanted the data stored on Shopee ClickHouse to be more accessible and available to provide broader support to the business. So, initially we required that the data stored in the Shopee ClickHouse database by the business side be the user’s business hot data.
But this also brought some problems, for example: users sometimes need to query a relatively long time data for analysis, so you have to import that part of the data that is not in ClickHouse and then do the analysis, and then delete this part of the data after the analysis. Another example: some of the business through the log service to do aggregate analysis and retrieval analysis, but also need a relatively long time log service data to help supervise and analyze the daily business.
Based on such requirements, we want to maximize the utilization of resources on the one hand, and support more data storage volume on the other hand, without affecting the query speed of users’ hot data, so using hot and cold data separation storage architecture is a good choice.
Typically, the design of a hot and cold separation scheme requires consideration of the following issues.
- How to store cold data?
- How to use cold storage media in an efficient, stable and simple way?
- How can hot data be sunk to cold storage media?
- How to evolve the architecture without affecting the existing user business?
The choice of cold data storage media is generally analyzed by comparing the following points.
- Cost
- Stability
- Full functionality (data can still be correctly queried during the sinking process and data in the database can be correctly written)
- Performance
- Scalability
Cold storage media selection and JuiceFS
The media that can be used for cold storage are S3, Ozone, HDFS, SATA Disk, where SATA Disk is limited by the machine hardware and not easily scalable, so it can be eliminated first. HDFS, Ozone and S3 are all better cold storage media.
Meanwhile, to use cold storage media efficiently and simply, we focus on JuiceFS, an open source POSIX file system built on Redis and cloud object storage, which allows us to access remote object storage more easily and efficiently.
JuiceFS uses existing object stores in the public cloud, such as S3, GCS, OSS, and so on. JuiceFS chooses Redis as the metadata storage engine because Redis storage is in memory, which can meet the low latency and high IOPS of metadata reading and writing, support optimistic transactions, and meet the file system atomicity for metadata operations.
JuiceFS provides an efficient and convenient way to access remote storage by simply using the format and mount commands to mount the remote storage to the local path through the JuiceFS client. Our ClickHouse database can then be accessed from the remote storage as if it were a local path.
After choosing JuiceFS, we turn our attention back to the selection of cold data storage media. We designed a benchmark as follows, using ClickHouse TPCH Star Schema Benchmark 1000s (benchmark details can be found in the We designed a benchmark that uses ClickHouse TPCH Star Schema Benchmark 1000s (see the ClickHouse community documentation for details) as test data to test the Insert performance of S3 and Ozone respectively, and the select statement of Star Schema Benchmark to compare the query performance.
The queried data is in the following three storage states.
- Partly in Ozone/S3 and partly on the local SSD disk.
- All on Ozone/S3.
- All on SSD.
The following are the results of our test sampling.
(1)Insert performance sampling results
Insert Lineorder table data to Ozone:

Insert Lineorder table data to S3:

As you can see, S3’s Insert performance is a little stronger.
(2)Query performance sampling results
According to ClickHouse Star Schema Benchmark, after importing the Customer, Lineorder, Part, Supplier tables, you need to create a flattened wide table based on the data from the four tables.
|
|
When this SQL statement is executed again, the following Error occurs when the data is all on the Ozone.
|
|
A portion of the Select data is in the Ozone, and a data sink from the SSD disk to the Ozone occurs during this process.
Result: Hang is stuck and cannot be queried.
When we did this test, we used the community version of Ozone 1.1.0-SNAPSHOT, and the results of this test only show that Ozone 1.1.0-SNAPSHOT is not very suitable for our usage scenario.
Since Ozone 1.1.0-SNAPSHOT has functional shortcomings in our usage scenario, the subsequent Star Schema Benchmark performance test report focuses on SSD and S3 performance comparisons (detailed Query SQL statements are available from the ClickHouse community documentation).
| Query No. | Query Latency Data on JuiceFS | Query Latency Data on ⅓ JuiceFs + ⅔ SSD | Query Latency Data on SSD |
|---|---|---|---|
| Q1.1 | 8.884 s | 8.966 s | 1.417 s |
| Q1.2 | 0.921 s | 0.998 s | 0.313 s |
| Q1.3 | 0.551 s | 0.611 s | 0.125 s |
| Q2.1 | 68.148 s | 36.273 s | 5.450 s |
| Q2.2 | 54.360 s | 20.846 s | 4.557 s |
| Q2.3 | 55.329 s | 22.152 s | 4.297 s |
| Q3.1 | 60.796 s | 27.585 s | 7.999 s |
| Q3.2 | 67.559 s | 29.123 s | 5.928 s |
| Q3.3 | 45.917 s | 20.682 s | 5.606 s |
| Q3.4 | 0.675 s | 0.202 s | 0.188 s |
| Q4.1 | 100.644 s | 41.498 s | 7.019 s |
| Q4.2 | 32.294 s | 2.952 s | 2.464 s |
| Q4.3 | 33.667 s | 2.813 s | 2.357 s |
In the end, we chose S3 as the cold storage medium after comparing all aspects.
Therefore, Cold and hot storage separation solution is implemented by JuiceFS+S3, and the process is briefly described below.
Implementation of hot and cold data storage separation
First, we mount the S3 bucket to the local storage path /mnt/jfs by using the JuiceFS client and then edit the ClickHouse storage policy configuration . /config.d/storage.xml file. Be careful when writing the storage policy configuration file not to affect historical user storage (i.e. keep the previous storage policy). Here, default is our historical storage policy and hcs_ck is the hot/cold storage policy.
For details, you can refer to the following figure.

For businesses that need to separate hot and cold storage, you just need to write the storage policy as hcs_ck in the table Statement and then control the cold data sink policy through the expression of TTL.
The following is an example to illustrate the usage and data separation process. Table hcs_table_name is a business log data table that needs to separate hot and cold storage, and the following is the table build statement.
|
|
The TTL expression shows that the table hcs_table_name indicates that the last 7 days of data are stored on the local SSD disk, the 8th to 14th days of data are stored on the remote S3, and data older than 14 days are deleted.
The general flow is shown in the following diagram.

The data parts of the table hcs_table_name (ClickHouse’s data storage uses the data part as the basic processing unit) are scheduled by a background task, which is executed by the thread BgMoveProcPool from the back_ground_move_pool (note that it is not the same as back_ground_pool).
|
|
The background task scheduler determines whether the data parts need to be moved (whether the data needs to be moved down to the remote storage) and whether it is possible to move.
The core logic of this task is to first select the data parts that need to be moved, and then move those data parts to the destination store.
In the interface: MergeTreePartsMover::selectPartsForMove and then select the data parts that need to be moved based on the ttl_move information in the data parts and store the move_entry of the data parts (with the IMergeTreeDataPart pointer and the required (including the IMergeTreeDataPart pointer and the size of the storage space to be reserved) into the vector. Afterwards, the interface is called.
|
|
The move process is simply clone the data parts on the SSD disk to the detach directory of the hcs_table_name table on the remote storage S3, and then move the data parts out of the detach directory, and finally the data parts on the SSD disk are cleared in the IMergeTreeDataPart destructor.
So the table is always available during the whole move process, because it is a clone operation, and the data parts moved at the same time are either active on the SSD disk or active on the remote storage.
For the move information of the table data parts, you can also query the following three fields of the system table system.parts.
Practice Sharing
After the Shopee ClickHouse cold and hot data separation storage architecture went live, we summarized some of the issues we encountered in practice.
Redis Memory Growth Exception
While the amount of data storage on S3 has not increased much, Redis memory continues to grow at a high rate.
JuiceFS uses Redis to store the metadata of the data files on S3, so normally, the more data files on S3, the more Redis storage is used. Usually this anomaly is due to the fact that the target table has many small files that do not merge and sink directly, which can easily fill up Redis.
This also introduces another problem: once Redis memory is full, JuiceFS can no longer successfully write data to S3, and if the JuiceFS client is unmounted, it will not be able to mount it again, and when it is mounted again, it will throw Error.
|
|
To avoid this problem, you should first monitor the ClickHouse merge status. clickhouse-exporter collects a merge metric clickhouse_merge that captures the number of merges that are currently being triggered (by querying the system.metrics table metric=‘merge ‘), and for each merge trigger, multiple data parts of a table will be merged. In our experience, if the average number of merges every three hours is less than 0.5, then it is likely that there is a merge problem on this machine.
There are many possible reasons for merge exceptions (e.g. HTTPHandler thread, ZooKeeperRecv thread continuously occupying a lot of CPU resources, etc.), which is not the focus of this article and will not be expanded here. So you can set an alert rule, if the number of merge is less than 0.5 times in three hours, alert the ClickHouse development and operation team to avoid the generation of a large number of small files.
What should I do if there are already a lot of small files sinking into S3?
The first way to stop the data from sinking is to find the user’s business table that is sinking a lot of small files in two ways.
The first way: check ClickHouse Error Log, find the table that throws too many parts, and then further determine if the table that throws the error has hot and cold storage.
The second way: by querying the system.parts table, find the ones with obviously too many active parts and disk_name equal to the alias of the cold storage. After locating the table that generates a lot of small files, use the ClickHouse system command SQL.
|
|
Stops the data from continuing to sink and prevents Redis memory from filling up.
If the table is small, say less than 1TB after compression (the 1TB here is an empirical value, we have used insert into ... select * from ..., if it is larger than 1TB, the import time will be very long and there is a certain possibility that it will fail in the middle of the import), you can choose to create temp table > insert into this temp table > select * from org table after confirming that the merge function is back to normal. from org table, then drop org table > rename temp table to org table.
If the table is relatively large, after confirming that the merge function is back to normal, try to use the system command SQL.
|
|
to wake up the merge thread. If merge is slow, you can query the system.parts table to find the data parts already on S3, and then manually execute the Query:
|
|
Move the small files that fall on S3 back to the SSD. Since SSDs have much higher IOPS than S3 (even with JuiceFS access acceleration), this speeds up the merge process on the one hand, and frees up Redis memory as files are moved out of S3 on the other.
JuiceFS Read/Write S3 Failure
Data sink failure, access to S3 through JuiceFS, can not read and write operations to S3, this time the user query if overwritten to the data on S3, then the query will throw the S3 mount on the local path of the data file can not be accessed error. If you encounter this problem, you can check the JuiceFS logs.
The JuiceFS logs are stored on syslog in Linux CentOS, so you can use the method
cat/var/log/messages|grep 'juicefs'to query the logs, and refer to the JuiceFS community documentation for the log directories for different operating systems.
The problem we encountered was send request to S3 host name certificate expired. The access problem was solved by contacting the S3 development and maintenance team.
So how to monitor this kind of JuiceFS read/write S3 failure? You can monitor it with the metrics juicefs_object_request_errors provided by JuiceFS, and alert the team members if there is an error, and check the logs to locate the problem in time.
clickhouse-server failed to start
When modifying the TTL of a replicated table (table engine with Replicated prefix) that requires hot and cold data storage separation for historical tables, the TTL expressions in the local metadata of the .sql file on clickhouse-server do not match the TTL expressions stored on ZooKeeper. This is an issue we encountered during testing, and if we restart clickhouse-server without fixing this issue, clickhouse-server will fail to start because the table structures are not aligned.
This is because the TTL of replicated tables is modified first in ZooKeeper, and then the TTL of tables on machines under the same node is modified, so if the TTL of the local machine is not modified successfully after the TTL is modified, and clickhouse-server is restarted, the above problem will occur.
suspicious_broken_parts
Restarting clickhouse-server failed, throwing Error.
|
|
This is because ClickHouse reloads the MergeTree table engine data when restarting the service, the main code interface is
|
|
In this interface, it will get the data parts of each table and determine if there is a #DELETE_ON_DESTROY_MARKER_PATH file under the data part folder, which is delete-on-destroy.txt. If it does, add the part to broken_parts_to_detach and add 1 to the suspicious_broken_parts count.
Then, in the scenario of hot and cold data storage separation, when data parts are sunk by TTL, the following code calls are made in the core interface move operation function.
|
|
In the last function swap the path pointing to active parts, that is, as said above, data parts are available during the move process, either in SSD as active or in S3 as active.
|
|
In this interface, #DELETE_ON_DESTROY_MARKER_PATH files are created inside the old active parts (i.e. replacing parts) to modify the state to DeleteOnDestory, which is used to delete the data parts of the state later on when IMergeTreeDataPart is parsed.
This is the reason why suspicious_broken_parts appears in our usage scenario, which affects ClickHouse service startup when this value exceeds the default threshold of 10.
There are two solutions: The first is to delete the metadata .sql file, stored data, metadata on ZooKeeper for the table that threw the error on this machine, restart the machine and rebuild the table, the data will be synchronized from the backup machine. The second one is to create force_restore_data flag under ClickHouse /flags path with the running user of clickhouse-server process and then just reboot.
As you can see from the above question, after using JuiceFS+S3 to implement a separate storage architecture for hot and cold data, new components (JuiceFS+Redis+S3) were introduced, and the database usage scenarios became more flexible, and accordingly, all aspects of monitoring information should be done. A few of the more important monitoring indicators are shared here.
- JuiceFS:
juicefs_object_request_errors: JuiceFS health status monitoring of S3 reads and writes. - Redis:
Memory Usage: Monitoring the memory usage of Redis. - ClickHouse:
clickhouse_merge: Monitor the merge status of machines in the cluster to see if it is working properly.
Hot and Cold Storage Architecture Benefits in a Nutshell
With the separation of hot and cold data storage, we have better supported our users’ data business, improved the overall cluster data storage capacity, relieved the local storage pressure on individual machines, and provided more flexible management of business data.
Before the hot and cold data separation architecture went online, the average disk utilization rate of our cluster machines was close to 85%. After going online, this figure dropped to 75% by modifying the business user table TTL. And the overall cluster supported two new data services on top of the original business volume. If we had not gone live with hot and cold isolation, our cluster would have been unable to take on new projects due to insufficient disk usage before the expansion. Currently we are sinking more than 90TB of data (after compression) to the remote S3.
In the future Shopee ClickHouse will continue to develop more useful features and evolve the product architecture. Currently JuiceFS is very stable in our production environment and we will further use JuiceFS to access HDFS and thus realize the Shopee ClickHouse storage compute separation architecture.
The version information for each product component mentioned in this article is as follows:
- Shopee ClickHouse: currently based on the community version ClickHouse 20.8.12.2-LTS version
- JuiceFS: v0.14.2
- Redis: v6.2.2, sentinel model, AOF on (policy is Every Secs), RDB on (policy is One Backup a Day)
- S3: provided by Shopee STO team
- Ozone: 1.1.0-SNAPSHOT