The definition of flow limiting varies in different scenarios, and can be the number of requests per second, the number of transactions per second, or the network traffic. By rate limit, we mean a limit on the number of concurrent requests arriving at the system, so that the system can handle some of the users’ requests properly to ensure the stability of the system.
The English word for rate limit is “rate limit”, and the definition in Wikipedia is relatively simple. We write programs that can be called externally, web applications accessed by browser or other means of HTTP, the frequency of access to the interface may be very fast, if we do not limit the frequency of access to the interface may lead to the server can not withstand the high pressure of hanging, which may also generate data loss. The flow-limiting algorithm helps us to control how often each interface or program function is called, which is a bit like a fuse to prevent the system from crashing due to exceeding the access frequency or concurrency.
We may see a response header like this when we call some third-party interfaces.
The act of limiting the flow refers to the operation to be triggered when the number of requests to the interface reaches the condition of limiting the flow, generally the following acts can be performed.
- Deny service: deny the extra requests (directed to the error page or informing that resources are not available)
- Service downgrade: Shut down or downgrade the backend service. This allows the service to have enough resources to handle more requests (return tuck-in data or default data)
- Privileged requests: there are not enough resources, I can only distribute the limited resources to important users
- Delayed processing: there is usually a queue to buffer a large number of requests, this queue, if full, then the user can only be rejected, if the task in this queue timeout, but also to return the system busy error
- Resilient Scaling: Automate the scaling of the corresponding services with automated operations and maintenance
Common current limiting algorithms
There are many options for implementing flow restriction.
- Legitimacy verification flow restriction: such as verification code, IP blacklist, etc., these means can effectively prevent malicious attacks and crawler collection
- Container flow limiting: such as Tomcat, Nginx and other flow limiting means, where Tomcat can set the maximum number of threads (maxThreads), when the concurrency exceeds the maximum number of threads will be queued waiting for execution; Nginx provides two flow limiting means: one is to control the rate, the second is to control the number of concurrent connections
- Server-side flow limiting: for example, we implement flow limiting algorithms on the server side
Counting current limit
The simplest algorithm to limit the flow is to count and limit the flow, for example, the system can handle 100 requests at the same time, save a counter, when a request is processed, the counter is added 1, after a request is processed, the counter is subtracted 1. Every time a request comes, look at the value of the counter, if it exceeds the threshold either reject.
Application Scenario: Total number of calls to some API interface accounts
- Pros: simple and brutal
- Disadvantages: Suppose we allow the threshold value is 10,000, the counter value is 0, when 10,000 requests in the first 1 second in a rush, this burst of traffic can not be topped. A slow increase in processing is not the same as a sudden influx for the program.
Fixed window restriction
It is mainly an additional concept of time window compared to counting limit. The counter is reset after every time window.
The rules are as follows.
- the number of requests is less than the threshold, access is allowed and the counter is +1
- If the number of requests is greater than the threshold, access is denied.
- After this time window has passed, the counter is cleared
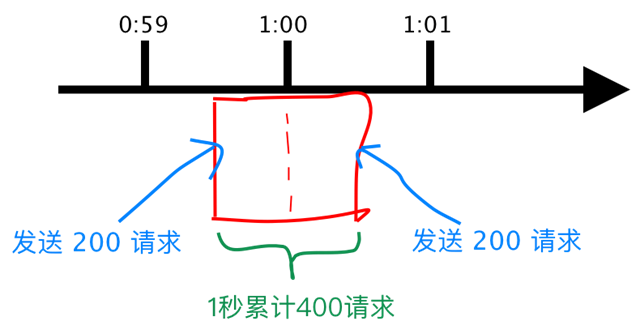
It seems to be perfect, but in fact there is a flaw.
Suppose a user sends 200 requests in the last few milliseconds of the 59th second, and when the Counter clears at the end of the 59th second, he sends another 200 requests in the next second. Then in 1 second this user sends 2 times as many requests, as follows.
QPS 限流算法
The QPS flow limiting algorithm limits the flow by limiting the number of requests allowed to pass per unit time.
Advantages.
- Simple calculation, whether to limit the flow is only related to the number of requests, and the number of requests spared is predictable (the number of requests spared by the token bucket algorithm also depends on whether the traffic is uniform), which is more in line with user intuition and expectations.
- It is possible to cope with unexpected traffic by lengthening the restriction period. For example, if the flow limit is 10 requests per second, and you want to let go of 20 requests at once, you can change the flow limit configuration to 30 requests per 3 seconds. There is some risk associated with lengthening the flow limit period, and the user can decide how much risk to take.
Disadvantages.
- Does not handle unit time boundaries well. For example, if the maximum number of requests is triggered in both the last millisecond of the previous second and the first millisecond of the next second, you see twice the QPS occurring in two milliseconds.
- Uneven release of requests. With bursty traffic, requests are always let go in the first part of the flow limit cycle. For example, with a limit of 100 requests in 10 seconds, the requests that are let go during high traffic are always in the first second of the flow limit cycle.
To solve this problem, sliding window flow limiting was introduced.
Sliding window to limit the flow
Sliding window is a technique for controlling the flow of traffic, a term that appears in the TCP protocol. A sliding window divides a fixed time slice and moves it as time passes, with a fixed number of movable cells that are counted and thresholded.
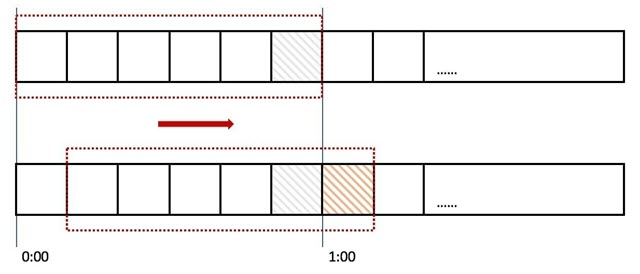
In the figure above we use the red dotted line to represent a time window (one minute), each time window has 6 cells, each cell is 10 seconds. Every 10 seconds the time window moves one frame to the right, see the direction of the red arrow. We set an independent counter Counter for each grid, if a request is accessed at 0:45 then we will be the fifth grid counter +1 (that is, 0:40 ~ 0:50), in the judgment of the flow limit when you need to add up the count of all the grid and set the frequency to compare.
How does the sliding window solve the problem we encountered above?

When the user sends 200 requests at 0:59 seconds, the counter of the sixth grid will be recorded +200, when the next second the time window moves to the right, the counter has already recorded the 200 requests sent by the user, so if it sends again, it will trigger the flow restriction, then reject the new requests.
In fact, the counter is a sliding window, but there is only one grid, so you want to limit the flow to do more accurate just divide more grids, in order to be more accurate we do not know how many grids should be set, the number of grids affects the accuracy of the sliding window algorithm, there is still the concept of time slice, can not fundamentally solve the critical point problem.
Leaky Bucket Algorithm
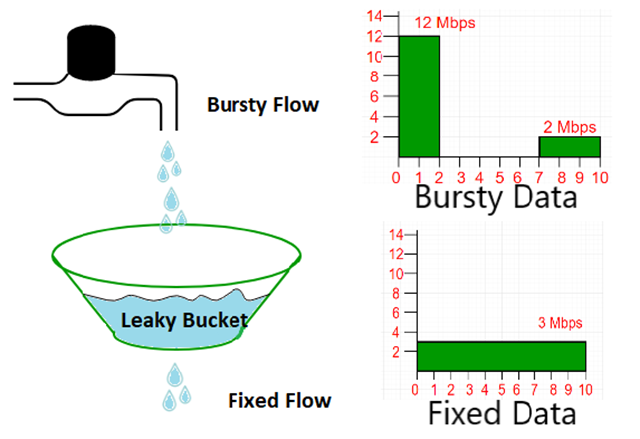
The leaky bucket algorithm is that water enters the leaky bucket first, the bucket then discharges water at a certain rate, and when the inflow of water is greater than the outflow, the excess water directly overflows. By replacing water with requests, the leaky bucket is equivalent to a server queue, but when the number of requests is greater than the flow-limiting threshold, the extra requests are denied service. The leaky bucket algorithm uses a queue to control the access speed of traffic at a fixed rate, so that the traffic can be “leveled”.
Leaky bucket algorithm implementation steps.
- Place each request into a fixed size queue for storage
- The queue flows out requests at a fixed rate, and stops flowing if the queue is empty
- If the queue is full, the extra requests are rejected directly
However, the bucket algorithm has some drawbacks, because water flows out from the bottom of the bucket at a fixed rate, and when there are transient burst requests within the server’s tolerance range, these requests will be put into the bucket first and then processed at an even rate, which will cause some requests to be delayed. So he can’t handle burst requests that are within the flow-limiting threshold. But if we get serious, I don’t think this drawback is valid. After all, the leaky bucket is supposed to smooth the traffic, if it supports bursts, then the output traffic is not smooth instead. If we are looking for a flow-limiting algorithm that can support bursty traffic, then the token bucket algorithm can meet the demand.
Token Bucket Algorithm
A token bucket is quite similar to a leaky bucket, except that tokens are stored in a token pass. It works like this, a token factory issues tokens to the token bucket periodically according to set values. When the token bucket is full, the extra tokens are discarded. Whenever a request arrives, the thread corresponding to that request fetches the token from the token bucket. Initially, since the token bucket holds many tokens, multiple requests are allowed to fetch tokens at the same time. When there are no tokens in the bucket, requests that cannot fetch a token can be discarded or retried. Let’s take a look at the following token bucket schematic.
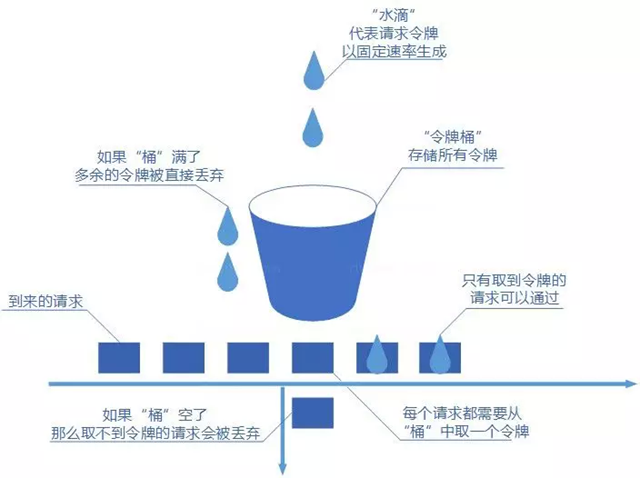
The token bucket is actually similar to the leaky bucket, except that the leaky bucket flows out at a fixed rate, while the token bucket stuffs tokens into the bucket at a fixed rate, and then the request can only pass through if it gets a token, and then be processed by the server afterwards. Of course, there is a limit to the size of the token bucket, so if the bucket is full, the tokens generated at a fixed rate will be discarded.
- Put tokens into the bucket at a fixed rate
- If the number of tokens exceeds the bucket limit, the token is discarded.
- Requests come to the bucket first, and if they are successful, they are processed, and if not, they are rejected.
The token bucket algorithm is the opposite of the leaky bucket algorithm, we have a fixed bucket with tokens in it. The bucket is empty at the beginning, and the system adds tokens to the bucket at a fixed time (rate) until the bucket is full, and the excess requests are discarded. When a request comes in, a token is removed from the bucket, and if the bucket is empty, the request is rejected or blocked.
The most obvious difference between the leaky bucket algorithm and the token bucket algorithm is that the token bucket algorithm allows a certain level of bursting of traffic. Because of the default token bucket algorithm, taking away tokens is not time consuming, i.e., assuming that when there are 100 tokens in the bucket, then 100 requests can be allowed through instantly.
- The token bucket algorithm, placed on the server side, is used to protect the server (itself) and is mainly used to limit the frequency of callers in order to keep itself from being overwhelmed. So if you have the processing capacity yourself, if the traffic bursts (actual consumption capacity is stronger than the configured traffic limit = bucket size), then the actual processing rate can exceed the configured limit (bucket size).
- And the leaky bucket algorithm, placed on the calling party, which is used to protect others, that is, to protect the system he is calling. The main scenario is that when the invoking third-party system itself has no protection mechanism, or has a traffic limit, our invocation rate cannot exceed his limit, and since we cannot change the third-party system, we only have control on the main caller side. At this time, even if the traffic bursts, it must be discarded. Because the consumption capacity is decided by the third party.
The token bucket algorithm is adopted by the industry because it is simple to implement and allows certain traffic bursts, which is user-friendly. Of course, we need to analyze each case, only the most suitable algorithm, there is no optimal algorithm.
Current limiting components
Generally speaking, we do not need to implement our own flow limiting algorithm to achieve the purpose of flow limiting, whether it is access layer flow limiting or fine-grained interface flow limiting in fact, there are ready-made tools to use, the implementation of which also uses the flow limiting algorithm we described above.
- Google Guava provides a flow limiting tool class RateLimiter, which is based on a token bucket implementation and extends the algorithm to support preheating.
- The Ali open source flow limiting framework Sentinel uses a leaky bucket algorithm for its even-queue flow limiting strategy.
- The flow-limiting module limit_req_zone in Nginx, which uses the leaky bucket algorithm.
- The limit.req library in OpenResty.
- Hystrix in Netflix open source
- Resilience4j
Sentinel, Hystrix, resilience4j comparison.
| Sentinel | Hystrix | resilience4j | |
|---|---|---|---|
| Isolation Strategy | Signal volume isolation (concurrent thread count limit) | Thread pool isolation / semaphore isolation | Signal volume isolation |
| Meltdown downgrade strategy | Based on response time, exception rate, number of exceptions, etc. | Abnormal ratio mode, time-out fuse | based on abnormal ratio, response time |
| Real-time statistics implementation | Sliding window (LeapArray) | Sliding windows (based on RxJava) | Ring Bit Buffer |
| Dynamic rule configuration | Supports multiple configuration sources | Support for multiple data sources | Limited Support |
| Scalability | Rich SPI expansion interface | Form of plug-in | Form of the interface |
| Annotation-based support | Support | Support | Support |
| Restricted flow | QPS-based, support for call relationship-based flow limiting | Limited Support | Rate Limiter |
| Cluster traffic control | Support | Not supported | Not supported |
| Flow Shaping | Support preheat mode, uniform queuing mode and other complex scenarios | Not supported | Simple Rate Limiter mode |
| System adaptive protection | Support | Not supported | Not supported |
| Console | Provides out-of-the-box console to configure rules, view second-level monitoring, machine discovery, etc. | Simple monitoring view | No console provided, can be docked to other monitoring systems |
| Multilingual support | Java / C++ | Java | Java |
| Open Source Community Status | Active | Stop maintenance | more active |