Basic implementation of linux networking
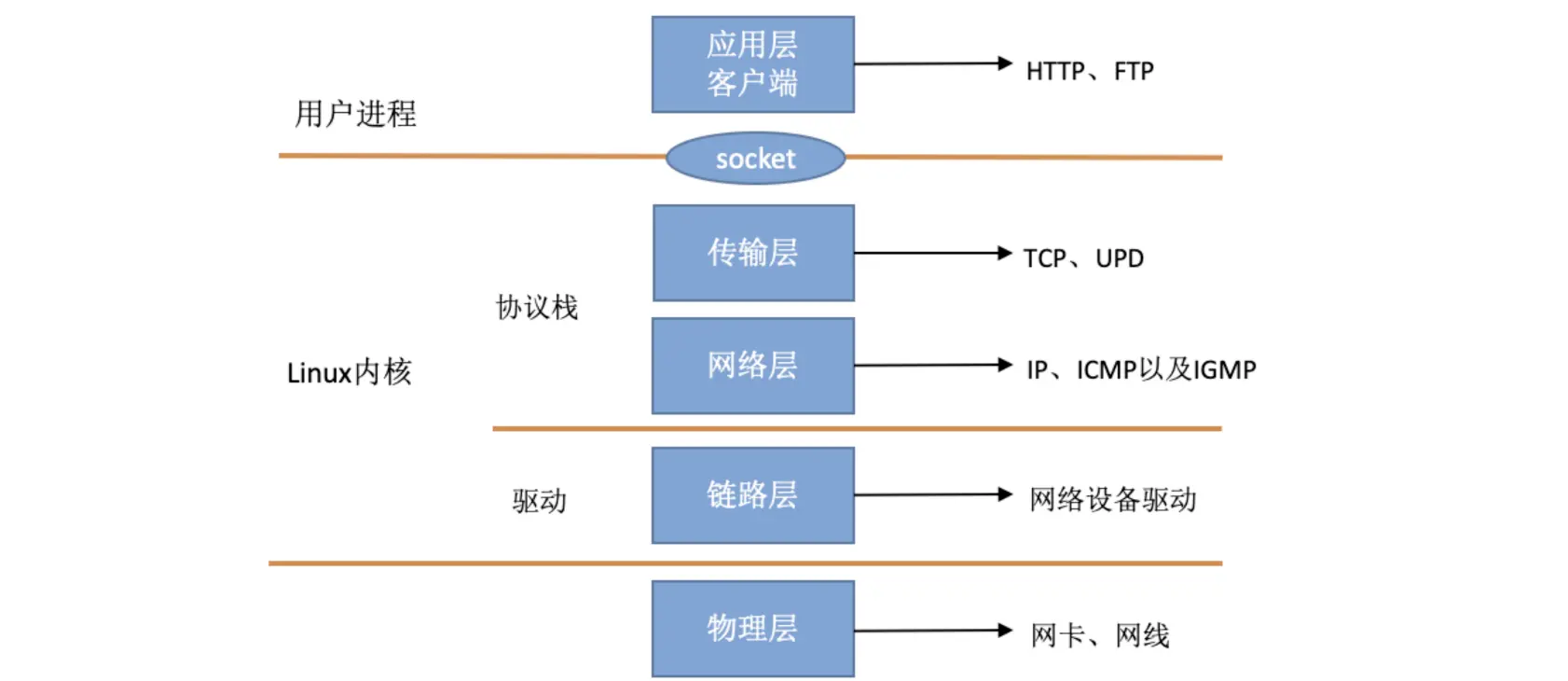
In the TCP/IP network hierarchy model, the entire protocol stack is divided into physical layer, link layer, network layer, transport layer, and application layer. The physical layer corresponds to the grid card and the grid line, and the application layer corresponds to various applications such as Nginx, FTP, etc. Linux implements the link layer, the grid layer, and the transport layer.
In the Linux kernel implementation, the link layer protocol is implemented by the grid card driver, and the kernel protocol stack implements the network and transport layers. The kernel provides socket access to the higher application layers for user processes. The layered model of the TCP/IP network as we see it using the Linux perspective should look like the following.
How to network events
When data arrives on the device, a voltage change is triggered on the relevant pin of the CPU to notify the CPU to process the data.
You can also call this a hard interrupt
But as we know, the CPU runs very fast, but the network reads the data very slowly, which will occupy the CPU for a long time, making the CPU unable to handle other events, such as mouse movement.
So how to solve this problem in linux?
The linux kernel splits the interrupt processing into 2 parts, one is the hard interrupt mentioned above, and the other is the soft interrupt.
The first part receives the cpu voltage change, generates a hard interrupt, then does only the simplest processing, and then asynchronously hands over to the hardware to receive the information into the buffer. At this time, the cpu can already receive other interrupt information over.
The second part is the soft interrupt part, how does the soft interrupt do it? In fact, it is to change the binary bits of memory, similar to the status field that we usually write business to, such as in network Io, when the buffer has finished receiving data, it will change the current status to complete. For example, when epoll reads a certain io time to finish reading data, it does not directly enter the ready state, but waits for the next loop to traverse to determine the status before stuffing this fd into the ready list (of course, this time is very short, but compared to the cpu, this time is very long).
The second half of the implementation used in kernel versions from 2.4 onwards is soft interrupts, which are handled solely by the ksoftirqd kernel thread. Unlike hard interrupts, which apply a voltage change to the physical CPU pins, soft interrupts notify the soft interrupt handler by giving a binary value to a variable in memory.
This is why epoll (formally introduced) was only known to be used in 2.6; the kernel did not support this approach until 2.4.
The overall data flow diagram is as follows.
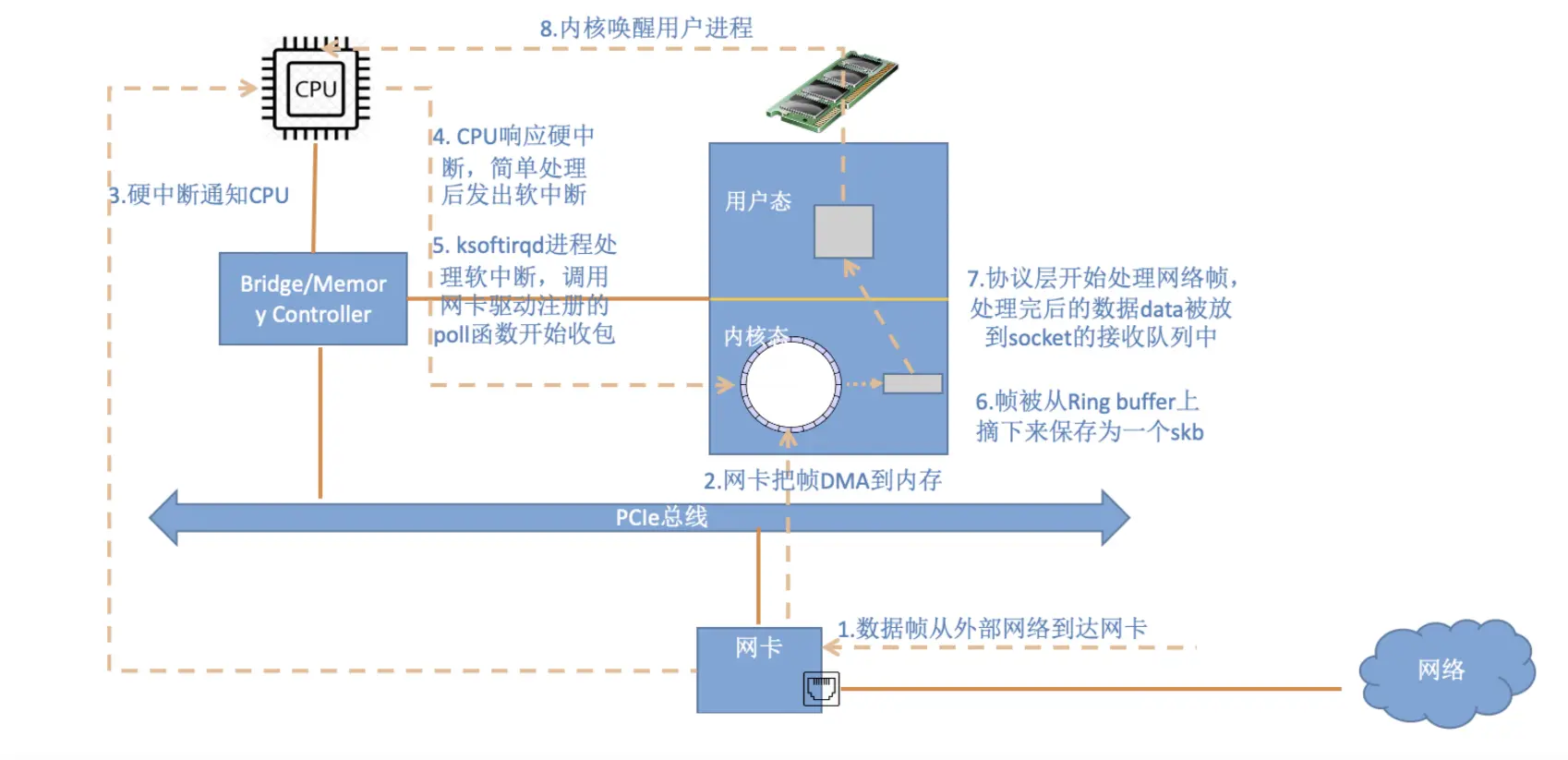
A data from arrives at the NIC and goes through the following steps before a data reception is completed.
- The packet enters the physical NIC from an outside network. If the destination address is not that NIC and the NIC does not have promiscuous mode enabled, the packet is discarded by the NIC.
- The NIC writes the packet by DMA to the specified memory address, which is allocated and initialized by the NIC driver. Note: Older NICs may not support DMA, though newer NICs generally do.
- The NIC notifies the CPU via a hardware interrupt (IRQ) that data is coming
- The CPU calls the registered interrupt function according to the interrupt table, and this interrupt function will call the corresponding function in the driver (NIC Driver)
- The driver disables the interrupt of the NIC first, indicating that the driver already knows that there is data in the memory, and tells the NIC to write the memory directly next time it receives a packet, and not to notify the CPU again, which can improve efficiency and avoid the CPU being interrupted constantly.
- Start soft interrupt. After this step, the hardware interrupt handler function ends and returns. Since the hard interrupt handler cannot be interrupted during its execution, if it takes too long to execute, it will make the CPU unable to respond to other hardware interrupts, so the kernel introduces soft interrupts so that the time-consuming part of the hard interrupt handler function can be moved to the soft interrupt handler function to be handled slowly.
- When it receives a soft interrupt, it will call the corresponding soft interrupt processing function. For the soft interrupt thrown by the network card driver module in step 6 above, ksoftirqd will call the net_rx_action function of the network module
- net_rx_action calls the poll function in the NIC driver to process the packets one by one
- In the pool function, the driver reads the packets written to memory one by one, the format of the packets in memory is only known to the driver
- The driver converts the packets in memory to the skb format recognized by the kernel network module and then calls the napi_gro_receive function
- napi_gro_receive will process the GRO related content, that is, it will merge the packets that can be merged, so that only one protocol stack call is needed. Then determine if RPS is enabled, if so, enqueue_to_backlog will be called
- In the enqueue_to_backlog function, the packet will be put into the input_pkt_queue of the CPU’s softnet_data structure, and then return, if the input_pkt_queue is full, the packet will be discarded, the size of the queue can be determined by net.core. The size of the queue can be configured via net.core. netdev_max_backlog
- The CPU will then process the network data in its own input_pkt_queue in its own soft interrupt context (call __netif_receive_skb_core)
- If RPS is not enabled, napi_gro_receive will call __netif_receive_skb_core directly
- See if there is a socket of type AF_PACKET (which is often called raw socket), if so, copy a copy of the data to it. tcpdump captures the packets here.
- Call the corresponding function of the protocol stack and give the packet to the stack for processing.
- After all the packets in memory have been processed (i.e. the poll function is finished), enable the hard interrupt of the NIC, so that the next time the NIC receives data again it will notify the CPU
epoll
poll function
The poll function here is a callback function that is registered and handled in a soft interrupt. For example, the epoll program will register an “ep_poll_callback”
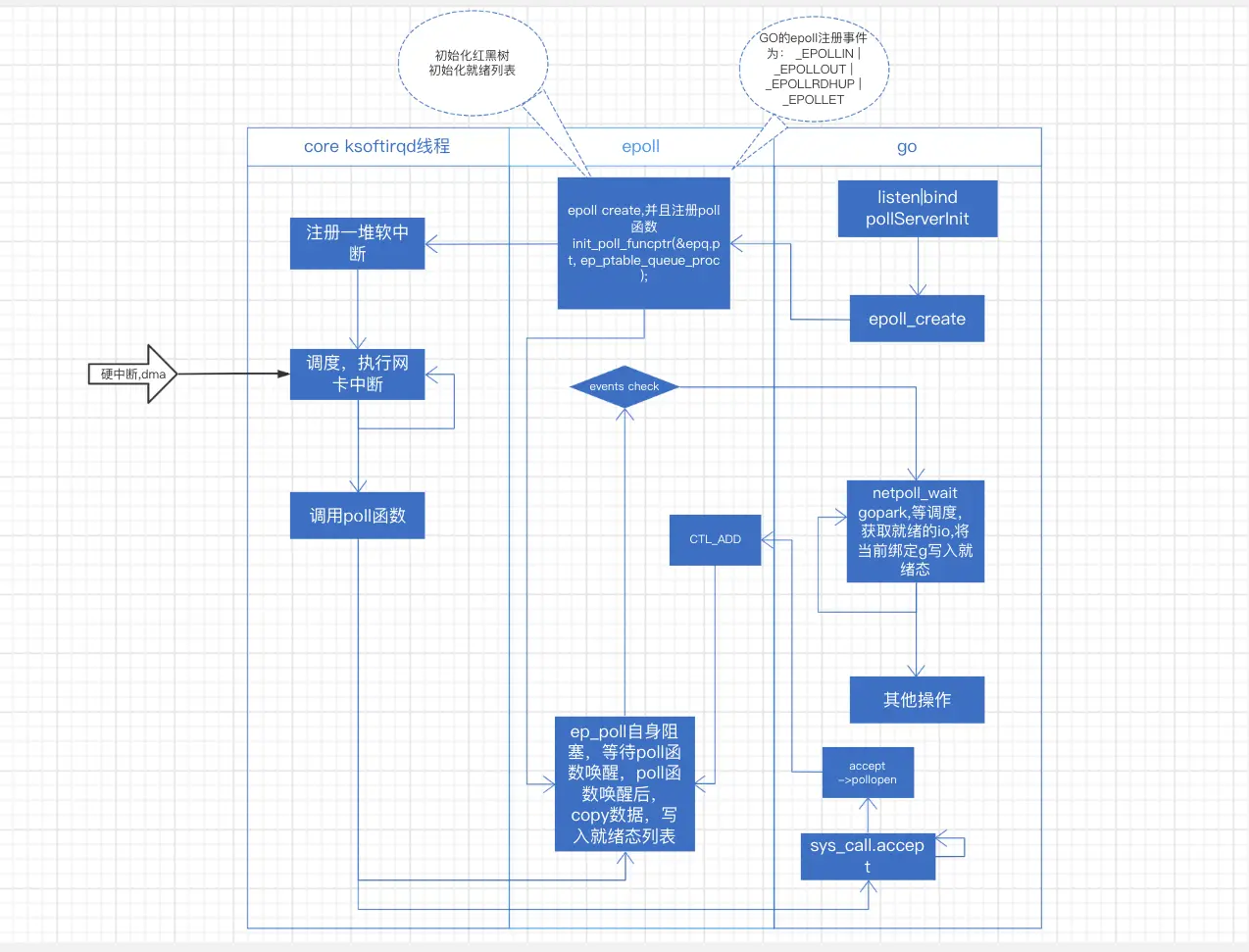
Take go epoll as an example.
|
|
go: netpollblock(gopark),let out cpu->scheduled back, netpoll(0) writes concurrently to ready state -> other operations ……
epoll thread: epoll_create(ep_ptable_queue_proc, register soft interrupt to ksoftirqd, register method ep_poll_callback to)->epoll_add->epoll_wait(ep_poll let out cpu)
core: NIC receives data -> dma+hard interrupt -> soft interrupt -> system dispatch to ksoftirqd, handle ep_poll_callback (note here that new connections come into the program, not by callback,but by accept) -> get the previously registered fd handle -> copy NIC data to the handle -> Operate on the fd according to the event type (ready list)
Part of the code
go: accept
|
|
epoll source code
|
|
Basic data structure
epoll uses kmem_cache_create (slab allocator) to allocate memory to hold struct epitem and struct eppoll_entry. When an fd is added to the system, an epitem structure is created, which is the basic data structure for the kernel to manage epoll.
|
|
And the main data structure corresponding to each epoll fd (epfd) is
|
|
struct eventpoll is created at epoll_create.
|
|
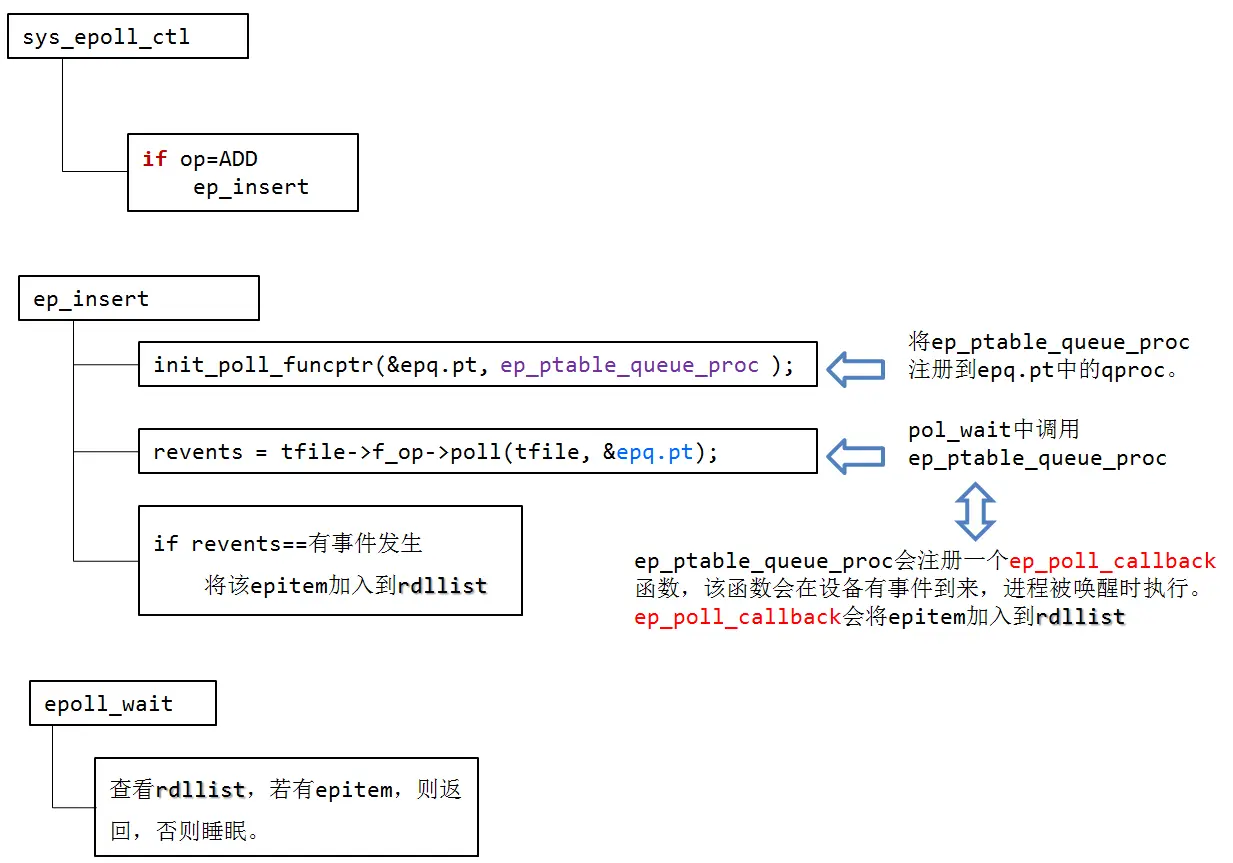
where ep_alloc(struct eventpoll **pep) allocates memory for pep and initializes it. Where the above registered operation eventpoll_fops is defined as follows: static const struct file_operations eventpoll_fops = { .release= ep_eventpoll_release, .poll = ep_eventpoll_ poll, }; In this way, a red-black tree is maintained in the kernel with the following approximate structure: clip_image002 Then comes the epoll_ctl function (omitting code such as error checking).
|
|
ep_insert is implemented as follows.
|
|
These two functions register ep_ptable_queue_proc to qproc in epq.pt. typedef struct poll_table_struct { poll_queue_proc qproc; unsigned long key; }poll_table; Execute f_op- >poll(tfile, &epq.pt), the XXX_poll(tfile, &epq.pt) function executes poll_wait(), and poll_wait() calls the epq.pt.qproc function, i.e., ep_ptable_queue_proc. ep_ptable_queue_ proc function is as follows.
|
|
ep_ptable_queue_proc
where struct eppoll_entry is defined as follows.
|
|
In the ep_ptable_queue_proc function, another very important data structure, eppoll_entry, is introduced. eppoll_entry mainly completes the association between the epitem and the callback (ep_poll_callback) function when the epitem event occurs. First, the whead of eppoll_entry is pointed to the device wait queue of fd (same as wait_address in select), then the base variable of eppoll_entry is initialized to point to epitem, and finally the epoll_entry is mounted to the device wait queue of fd by add_wait_queue. queue. After this action, the epoll_entry has been mounted to the device wait queue of fd.
Since the ep_ptable_queue_proc function sets the ep_poll_callback callback function for the wait queue. So when the device hardware data arrives, the wakeup function ep_poll_callback will be called when the hardware interrupt handling function will wake up the process waiting on that wait queue
|
|
So the main function of ep_poll_callback function is to add the epitem instance corresponding to the file to the ready queue when the wait event of the monitored file is ready, and when the user calls epoll_wait(), the kernel will report the event in the ready queue to the user.
The epoll_wait implementation is as follows.
|
|
epoll_wait calls ep_poll. ep_poll is implemented as follows.
|
|
Trivia
Hybrid mode
Promiscuous mode (English: promiscuous mode) is a term used in computer networks. It refers to the ability of a machine’s network card to receive all data streams passing through it, regardless of their destination address.
Promiscuous mode is commonly used in network analysis
DMA
DMA, full name Direct Memory Access, means direct memory access.
DMA transfers copy data from one address space to another, providing high-speed data transfers between peripherals and memory or between memory and memory. When the CPU initializes this transfer action, the transfer action itself is implemented and completed by the DMA controller. the DMA transfer method does not require the CPU to directly control the transfer, and there is no interrupt processing method like retaining the field and restoring the field process, through the hardware to open a direct data transfer channel for RAM and IO devices, making the CPU much more efficient.
Main features of DMA:
- Each channel is directly connected to a dedicated hardware DMA request, and each channel equally supports software triggers, which are configured via software.
- Priority between multiple requests on the same DMA module can be programmed by software (there are four levels: very high, high, medium and low), and priority settings are determined by hardware when they are equal (request 0 has priority over request 1, and so on).
- Transfer width (byte, half-word, full-word) of the independent data source and destination data areas, simulating the packetization and unpacketization process. Source and destination addresses must be aligned by data transfer width.
- Supports circular buffer management.
- Each channel has 3 event flags (DMA half-transfer, DMA transfer complete, and DMA transfer error), which logically or become a single interrupt request.
- Transfers between memory and memory, peripheral and memory, and memory and peripheral.
- Flash, SRAM, SRAM of peripherals, APB1, APB2 and AHB peripherals can be used as sources and targets for accesses.
- Programmable number of data transfers: up to 65535 (0xFFFF).
Non-blocking socket programming to handle EAGAIN errors
In linux, when receiving data from a non-blocking socket, there is often a Resource temporarily unavailable, and the errno code is 11(EAGAIN), what does this mean? This indicates that you have called a blocking operation in non-blocking mode, and this error is returned when the operation is not completed. For non-blocking sockets, EAGAIN is not an error. On VxWorks and Windows, EAGAIN is called EWOULDBLOCK.