Can a normal element become a replacement element
By replacement elements, we usually mean elements such as images, videos, etc., corresponding to HTML tags <img> and <video>, while elements such as <div>, <p>, <span>, etc., which are normally used for layout, are non-replacement elements.
In fact, from 2019 onwards, the above rule has become inaccurate, or a rule that only holds under constraints.
In other words, elements such as <div>, <span>, etc. can be transformed into replacement elements under certain conditions, and the condition for this transformation is the url() function syntax of the content attribute.
content and replacement elements
The term “replacement element” means that the content is replaceable, and the content attribute can directly replace the content in HTML, so any scenario where the content attribute can take effect can be called a replacement element.
If it takes effect in the ::before / ::after pseudo-element, then this pseudo-element is called an “anonymous replacement element” at this point.
In CSS, something without an explicit HTML tag is called “anonymous”, for example, the following piece of HTML.
|
|
Where I am is an anonymous inline box, and Xinxu is an inline box because it has an explicit <span> tag on the outside.
The same is true for pseudo elements, where ::before / ::after create content without an explicit tag outside, and are therefore called “anonymous replacement elements”.
Since the content attribute has an “anonymous replacement element”, does the content attribute have a “replacement element”? And what is the difference between the two?
First of all, the answer to the first question is “Yes!”
New canonical feature of #### content
This new canonical feature is that the content attribute can replace content even without the help of a pseudo-element!
The history is as follows.
- no browser supported the use of the
contentattribute in non-pseudo elements. - in about 17 or 18, Chrome was the first browser to support direct
contentattributes for normal elements. - In 19 the content specification was clarified, and Firefox and Safari browsers followed suit with support.
As a result, the current state of affairs is that all modern browsers support the content attribute for content replacement, but only for url() resource replacement, not for character content replacement.
As an example, here is the HTML for a logo.
|
|
In the past, we used to set the font size to 0 or the text to be transparent, and then the logo was displayed as the background image, but now we can just use the content attribute to solve this problem once and for all.
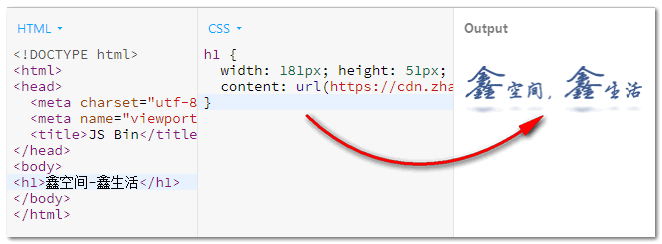
In this case, both device recognition and search engines get the exact text content, while the normal user still sees the logo image, which is both visual and functional.
The <h1> is a replacement element, essentially the same as the <img> element.
and the difference between anonymous replacement elements
Since the anonymous replacement element lacks an explicit label, the external dimensions of the image cannot be resized, e.g.
The width:100px and height:100px; in the CSS above cannot change the size of the logo.png image because it is “anonymous”, it is like an egg without a shell, you cannot change the size of the shell to affect the shape and size of the egg white and yolk inside. and yolk by changing the size of the shell.
However, unlike the replacement element, which has an explicit tag element, the external size can be set as a replacement element, e.g.
At this point the size of the logo.png image is 100px * 100px.
content New Features Explained
All modern browsers support the use of the content url() function syntax in any HTML element, and once used, the element becomes a replacement element.
The reasons for this are.
- in terms of behavior, the original content is replaced with an image, which is a typical replacement element.
- in terms of style, it is no different from the
<img>element.
is not different from the <img> element
For example, the <img> element stretches the size of the image by setting the width and height, and in the example above the <h1> element also has the type behavior.
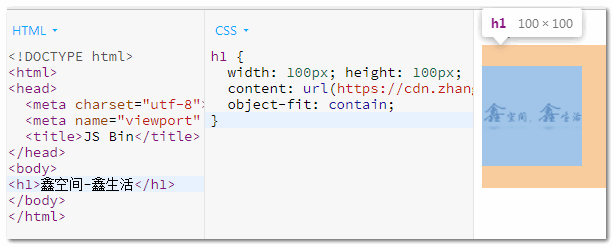
Another example is that the <img> element controls how the image fits into the display by setting the object-fit attribute, and the <h1> element has the same behavior, e.g.
This is the effect shown below, where the logo image is displayed in a 100px * 100px area while maintaining scale.
The reverse is also true
The converse also holds, meaning that if an element was originally a replacement element, then if we set content:'' to reset it, the element will be reverted to a non-replacement element.
At this point, we can use the ::before / ::after pseudo-element to achieve some functionality.
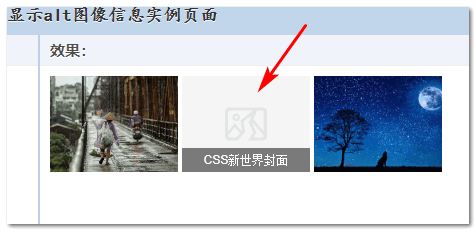
For example, the technical implementation mentioned in the most popular 2020 article “Best practices for CSS style handling after image load failure” takes advantage of this feature.
|
|
|
|
In this case, the error image not only shows the split image, but also shows the alt information, letting the user know what the image represents.
Application in practical development
Using the content attribute to display images is not commonly used in everyday development; for normal image display you use the <img> element, and for decorative image display you use the background-image attribute.
When is the content attribute only needed?
It is when you want the original HTML content structure at the source level, but the visual representation is still an image.
For example, if you want to display a logo as mentioned at the beginning, or if you want to clear (or hide) a large section of content without changing the structure of the HTML, you can use.
It doesn’t take up any space, but still responds to click behavior and can be recognized by devices such as screen readers.
Well, that’s all there is to this article, which takes you through the new behavior of the content attribute.
If the content of this article is helpful to your learning, please feel free to forward it and share it.