Since I joined the company in May last year, I have been responsible for the packaging and deployment of PaaS toB products, which is somewhat similar to the Kubernetes community’s SIG Release Team. The main work during the trial period is to optimize our existing packaging and release process. Many optimizations were made to the product packaging and release pipeline during this period, most notably the optimization of mirror synchronization, which improved the speed of mirror synchronization by a factor of 5 to 15. This greatly shortened the release time of the whole product and was well received by our colleagues. So today I thought I would share this optimization and the rationale behind it.
Our product is packaged with a list of mirrors, and based on this list, the mirrors are synchronized in the CI/CD pipeline mirror repository to a release archive mirror repository and a packaged mirror repository. The registry storage directory of the packaged image repository is eventually packaged in an ungzip-compressed tarball. This tarball is eventually extracted to the deployed image repository storage directory during deployment of the client environment for cluster deployment and component deployment. As to why this is possible during deployment, please refer to my previous article docker registry migration to harbor for the rationale.
During the packaging process, the images are synchronized twice, each time to a different image repository based on a list of images.list, using docker pull -> docker tag -> docker push. The flow of the image synchronization is shown in the following diagram.

The first time we pull the image from the CI/CD streamline image repository (cicd.registry.local) and push it to the release archive image repository (archive.registry.local), the purpose of which is to archive and backup the image we have already released, this step is called save sync.
The second time, we sync the image from the archive.registry.local repository to the package.registry.local repository. Unlike the first mirror synchronization, this time the mirror repository is cleaned up, first the storage directory of the package mirror repository is cleaned up, and then the container registry container allows the registry to re-fetch the metadata information of the mirror into memory. The purpose is to clean up old data and prevent historical mirrors from being brought into the installer for this release.
Once the image synchronization is complete, the entire repository of packaged images (/var/lib/registry) is packaged into a tarball and placed in the product installer.
Question
When I first joined the company, our product release took the longest to synchronize with the mirror phase, remembering that the longest time took 2h30min. the main reason for this time is as follows.
docker Performance Issues
When doing image synchronization, we use the docker pull -> docker tag -> docker push method. During the process of docker pull and docker push, the docker daemon will decompress the image layer, which is very time consuming and wasteful of CPU resources.
And because the disk performance of our intranet machine is so bad, sometimes it’s not even as fast as USB 2.0 (57MB/s)! So imagine how slow it is. This results in a long time to synchronize one or two hundred images each time, the longest time being two and a half hours.
Unable to reuse old data
The second mirror sync will clean up the packaged mirror repository, making it impossible to reuse the historical mirrors. In fact, each time a release is made, the number of mirrors changed and added is very small, averaging about 1/10 of the original, and the number of mirrors synchronized incrementally is only a little. Because we need to ensure that the mirror repository for this release can only contain the required mirrors, and cannot contain mirrors that are not related to this release, we need to clean up the mirror repository every time, which is unavoidable. I have not been able to find a way to reuse these historical mirrors.
Optimization
According to the two problems mentioned above, after repeated research and testing, they were finally solved perfectly and the mirror synchronization was optimized from the original maximum of two and a half hours to an average of five minutes.
skopeo Alternative to docker
The first solution to the performance problem of docker pull -> docker tag -> docker push was to use skopeo instead. Use skopeo copy to copy images directly from one registry to another. This avoids the performance loss caused by the docker daemon decompressing the image’s layer. After using skopeo, mirror synchronization is much faster than before, about 5 times faster on average.
overlay2 Reuse old data
After solving the performance problem of docker, the remaining problem is the inability to reuse old data. It was a pain in the ass to keep the historical images. I don’t know why I thought of the overlay2 feature: copy on write. For example, if you run docker and start a container, you can modify and delete files inside the container without affecting the image itself. This is because docker uses overlay2 co-mounting to mount each layer of the image as a merged layer. What you see inside the container is the merged layer, and modifications and deletions of files on the merged layer inside the container are done through the upper layer of overlay2, and do not affect the image itself, which is located on the lower layer. An image stolen from the official docker documentation Use the OverlayFS storage driver.
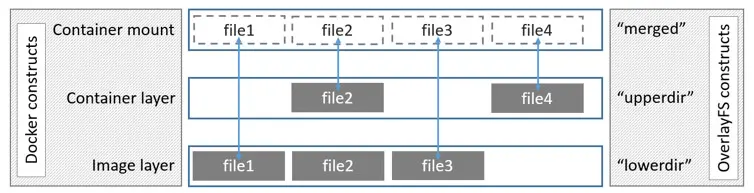
As for the role of these Dir’s in the above diagram, here is an explanation lifted from StackOverflow. For a detailed explanation of the overlayfs file system, see this document overlayfs.txt on the official Linux kernel web site.
LowerDir: these are the read-only layers of an overlay filesystem. For docker, these are the image layers assembled in order.
UpperDir: this is the read-write layer of an overlay filesystem. For docker, that is the equivalent of the container specific layer that contains changes made by that container.
WorkDir: this is a required directory for overlay, it needs an empty directory for internal use.
MergedDir: this is the result of the overlay filesystem. Docker effectively chroot’s into this directory when running the container.
Anyway, overlay2 is good! By the nature of overlay2, we can use the historical data as the lowerdir in overlay2. The upperdir is the incremental data for this mirror sync, and the merged is the actual data that will be needed in the end.
overlay2
Although the option of using overlay2 was mentioned above, there is still no mature solution so far. The problems that need to be solved are as follows.
- How to clean up old data
- How to reuse the historical mirrors?
- How to distinguish the historical mirror from the current one?
- How to guarantee that the result of this mirror synchronization contains only the mirror needed this time?
registry storage structure
Since we want to use the historical mirror repository data as the lowerdir for overlay2, how do we solve the previously mentioned problem of cleaning up old data and using historical mirrors? Then we need to review the registry storage directory structure again.
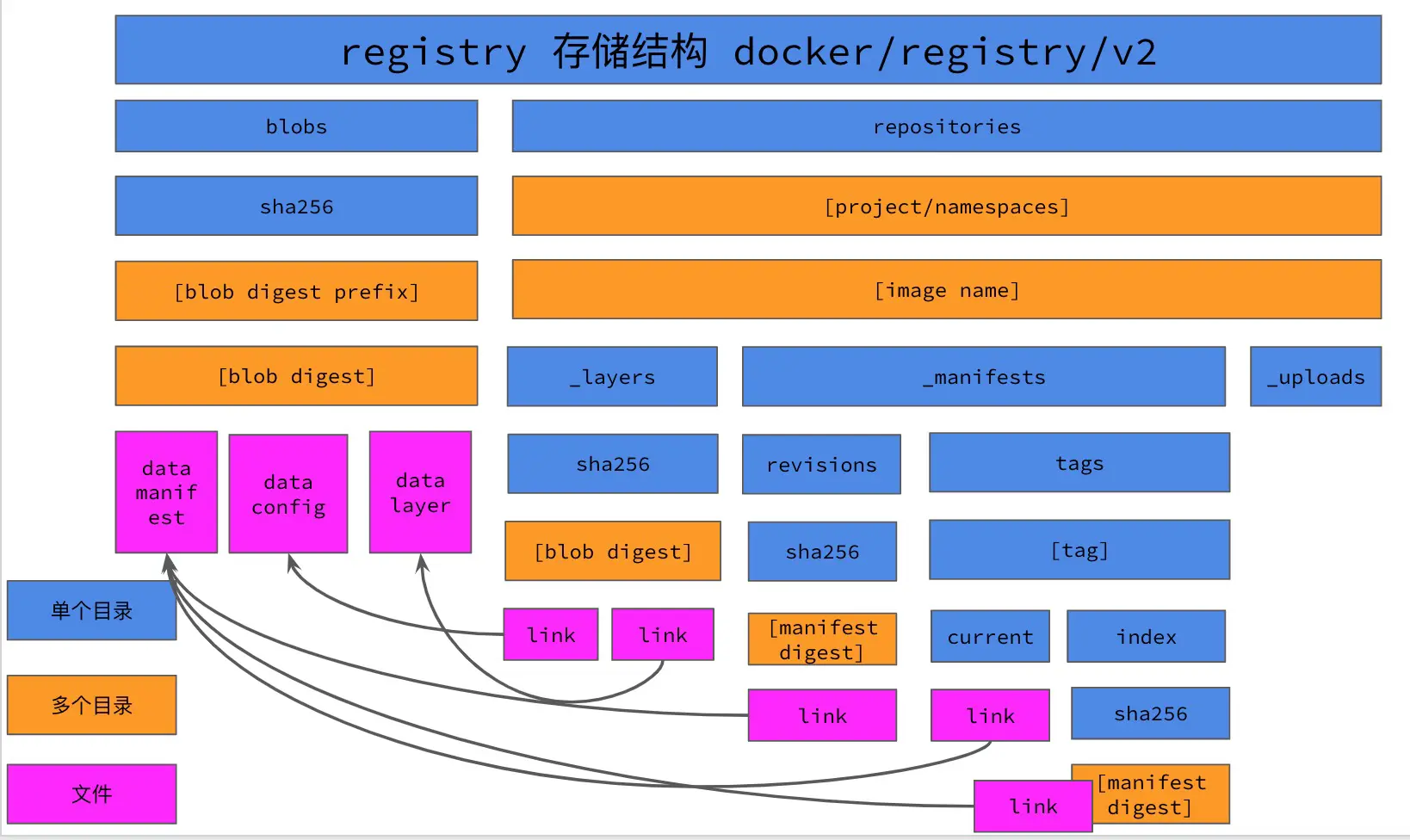
According to the storage structure of registry, we can know that the blob files of the image are stored in the blobs directory. blob files have three kinds: manifests of the image; image config files of the image; and layer files of the image. The manifests and images config files are text files in json format, and the image layer files are compressed tarball files (usually gzip). If you want to reuse historical images, you should reuse the layer layer files of the image to a large extent, because these files are the largest among the images, and the layer layer files of the image are decompressed during docker pull and docker push.
For the same mirror repository, the files under blobs are pointed to the corresponding data file by the link file under repositories. This means that multiple mirrors can use the same layer, for example, if the base image of multiple mirrors is debian:cluster, then for the whole registry mirror repository, only one debian:cluster image should be stored.
Similarly, when using a historical mirror, can we just use its layer? This may be difficult to understand 😂. Let’s use the following example to illustrate.
When we copy these images from k8s.gcr.io to a local image repository using skopeo copy, after copying the first image, the log message Copying blob 83b4483280e5 skipped: already exists is displayed when copying the subsequent images. This is because these mirrors are using the same base image, which contains only one layer, the 83b4483280e5 blob file. Although there is no base image for these mirrors in the local mirror repository, there is a layer for the base image, and skopeo will not copy the same blob again.
|
|
From the above experiment, we can learn that skopeo will not copy the same blob as long as the same blob exists in the registry, so how to let skopeo and the registry know that these layers exist?
This is where we need to review the following registry storage structure again. Under repositories, there is a directory _layers in each image’s folder, and the contents of this directory is the link file to the image layer and image config. That is to say, as long as there is a link file pointing to a blob under _layers of an image, and the data file under blobs pointed by the link file does exist, then when pushing the image, the registry will return to the client that the blob already exists, and skopeo will skip processing the existing blob. In this way, we can reuse historical data.
In the history image repository files: blobs directory is all you need; repositories directory only need each image _layers directory can; _manifests directory is the image tag we do not need them; _uploads directory is the push image when the temporary directory also do not need. Then we end up needing the files in the history mirror repository as follows.

So far we have solved the problem of how to clean up old data and how to reuse historical mirrors. The next step is to use overlay2 to build the filesystem needed for the mirror repository.
mirror image in the mirror image?
When it comes to overlay2, the first solution that comes to mind is container mirroring: using the nesting method, the historical mirror repository storage directory is copied to a registry image, and then this image is used to start the registry container of the packaged mirror repository. The Dockerfile of this image repository is as follows.
- Then use this Dockerfile to build an image named registry:v0.1.0-base and use this image to docker run a container.
|
|
- Then synchronize the mirror
|
|
- After synchronizing the mirrors, you need to delete the mirrors that do not have a
_manifestsdirectory under repositories. If the mirror is in the repositories directory, the _manifests directory will be generated again. This can solve the problem of how to distinguish the historical mirrors from the current mirrors, which in turn can ensure that the result of this mirror sync only contains the mirrors needed this time.
- Finally, you need to use registry GC to remove the files that are not referenced in the blobs directory.
|
|
- Then use docker cp to copy the image out of the container and pack it into a tarball
I did a simple test using this approach, because when using skopeo copy image will prompt a lot of blobs already exist, so the actual copy of the image is only a small part, the performance is indeed much faster than before. However, there are many disadvantages of this solution: one is that the registry image needs to be maintained and built manually; the second is that using docker cp to copy the registry storage directory in the container to the container host is a bit poor in performance; the third is that different products need different base images, which is troublesome to maintain. So we also need to use overlay2 technology in a simpler way.
Container mount overlay2 merged directory
If you think about it, you can put historical mirror data into a registry image and use it to start a registry container. Synchronizing the image and performing registry gc are actually read/write/delete operations on the merged layer of overlay2. So why don’t we just create the directories needed by overlay2 on the host and then mount them as a merged directory using overlay2 federated mounts. When we start the registry container, we can bind the merged directory to the registry container with the docker run -v parameter. Let’s do a simple verification and test.
- First create the directory needed for overlay2
- Place historical mirror repository data in the lower directory
|
|
- Delete the _manifests directory of all mirrors, so that the registry thinks there are no mirrors in there, only blobs data.
|
|
- Simulate the start of a container, using overlay2 co-mounted as a merged layer
|
|
- docker run starts a registry and mounts the merged directory to the /var/lib/registry/docker directory inside the container
- Synchronize mirrors, synchronize the mirrors needed for this release to the registry
|
|
- After synchronizing the image, do a registry gc to delete the useless blob data
|
|
- The final package merged directory is the final result of this
I followed the above steps locally and verified that it works! The second time I synced the image, I was prompted that many blob already existed and the image synced about 5 times faster than before. Then write the above steps as a script and you can use it again and again.
registry gc question?
I’ve encountered the problem of registry GCs not cleaning up: after a GC, some image layer and config files have been deleted from the blobs storage directory, but the link files pointing to it are still stored in the repositories directory 🙄. There is a PR on GitHub Remove the layer’s link by garbage-collect #2288 is dedicated to cleaning up these useless layer link files. The earliest one is from three years ago, but it hasn’t been merged yet 😂.
The solution is to use the solution mentioned in my docker registry GC schema analysis article: homebrew registry GC script 🙃 .
|
|
Process
Well, so far the final optimization plan has been set, its process on the following.
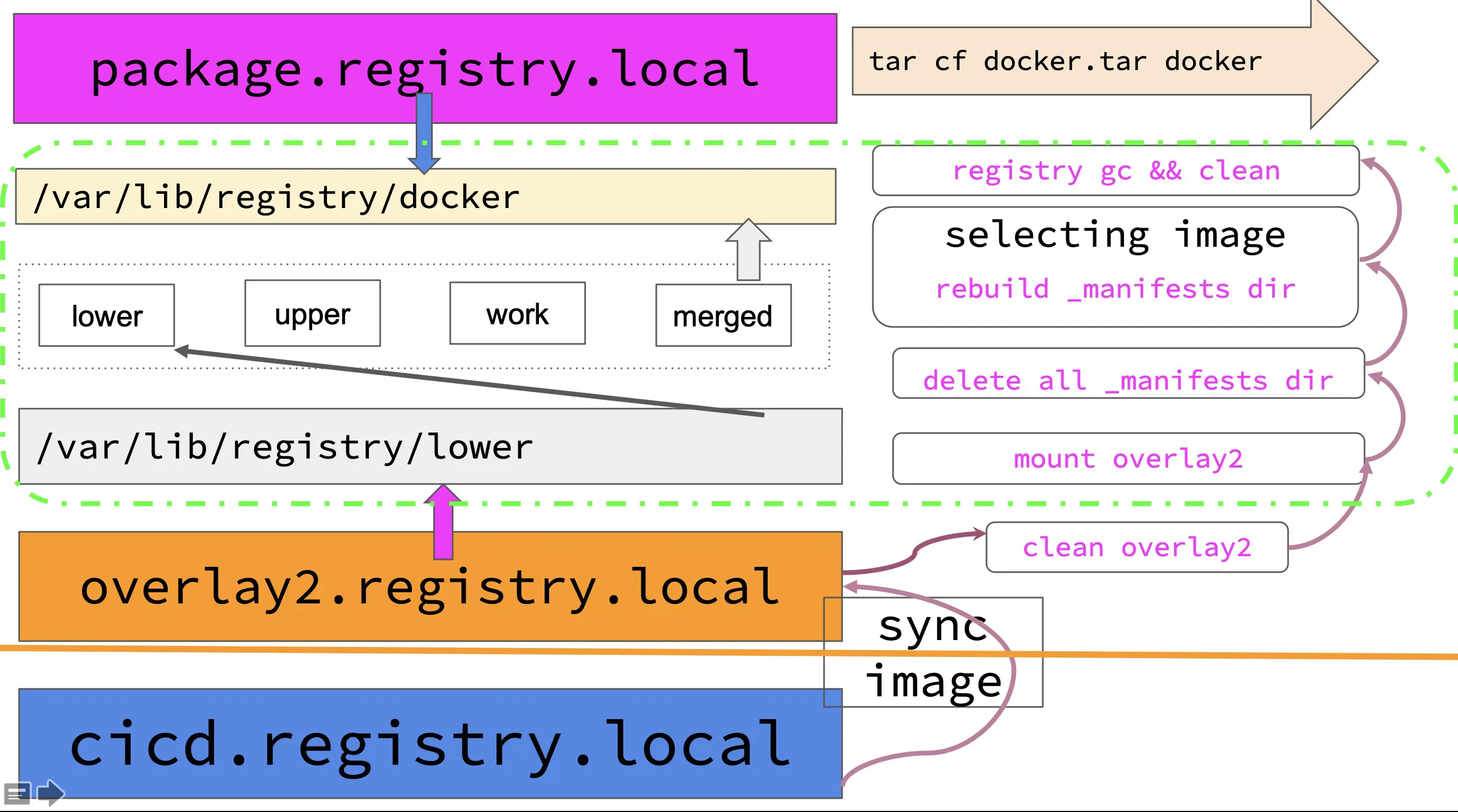
- The first time you synchronize the image, you will not synchronize the image to the archive backup image repository (archive.registry.local), but to the overlay2 image repository, which will be used as the lower layer for the second image synchronization.
|
|
- After the first mirror sync is done, clean up the merged, upper, and work layers of overlay2 and keep only the lower layer. This is because the lower layer contains the result of the first mirror sync.
- The next step is to mount overlay2 using mount, and then go to the merged level and delete all the _manifests directories
- Next, a second mirror sync is performed, this time to recreate the _manifests directory
|
|
- After the second sync, use the homemade registry GC script to remove unnecessary blob files and link files.
- Finally, pack the image repository directory and you have the image you need.
Ending
Although the process is much more complex than before, the result of the optimization is very obvious - it is 5 to 15 times faster than before and has been working steadily in our production environment for most of the year.
After reading this article, you may feel confused as to what is being said. What mirror synchronization, mirror blob, layer, overlay2, co-mount, copy-on-write, etc., confused by the complex background and concepts 😂. This article is really not very good understanding, because the background may be more special and complex, few people will encounter such scenarios. In order to understand the content and the principles behind this article well, I will write a separate blog in a while to understand the technical principles mentioned in this article through best practices. Stay tuned 😝!