Wikipedia has a sister project called “Wikidata” (Wikidata). You can click on it from the left sidebar of Wikipedia.
“Wikidata takes all of Wikipedia’s data and organizes it into a machine-processable database for easy access. For example, which is the most populous region in Shanxi Province?
This kind of question is very time-consuming to query in Wikipedia, and you have to manually extract information from each entry. However, Wikidata can execute just one command and return the answer (see later for details). Because it provides structured data, it can be queried by machine.
However, Wikidata is not a relational database, but an RDF database; the query language is not SQL, but SPARQL. I learned a little bit of RDF and SPARQL in a rough way, and this article is a learning note to demonstrate how to use Wikidata to query information.

Meaning of RDF
As we all know, relational databases are the most widely used databases today, abstracting data into a tabular relationship of rows and columns.
However, the real world is less like a table and more like a network. Various things are connected together in a web through intricate relationships.
A network is called a graph in mathematics, and each thing is a node of a graph, and the relationship between the nodes is the edge that connects them together. If a database stores data as a graph, it is called a graph database.
RDF is a way of describing graph databases, or a protocol for using them. It describes the direct relationship between things in a “triple” fashion.
A “triple” is the core concept of RDF, which refers to two things and the relationship between them, syntactically rendered as “subject + predicate + object”.
|
|
The above sentence is an RDF triplet.” sky" (subject) and “blue” (object) are two things that are connected by a color relation (predicate).
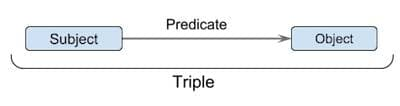
RDF requires that predicates (i.e., relationships between things) must be clearly defined. Think of it this way, if the predicate is given, you can use the subject to query the object, or the object to query the subject. For example, if the color relationship is given, then the following query can be made to the database.
RDF requires that each set of predicates must have an explicit URL that distinguishes between the different predicates, and RDF officially defines a set of common predicates with the following URLs.
https://www.w3.org/1999/02/22-rdf-syntax-ns
When you use a URL, just refer to it so that others know which set of predicates is being used.
RDF allows you to specify a prefix that represents the URL address, such as the URL of the official predicate above, which is usually represented by the prefix rdf.
|
|
Each URL can contain multiple predicates, distinguished by the “prefix : predicate” form. For example, the official definition of a “type” predicate, which specifies the type of the subject, can be represented by rdf:type.
|
|
The above sentence, written as an RDF triplet, is of the following form.
Since rdf:type is a common predicate, RDF allows it to be abbreviated to a, so that “Xiao Ming is a student” can in turn be expressed as Xiao Ming a student.
Note that each RDF triplet ends with an English period to distinguish multiple triples.
Example of RDF syntax
Here is an example to demonstrate how RDF defines the relationship between things.
|
|
The above passage is a natural language text. We start by drawing a network relationship diagram.
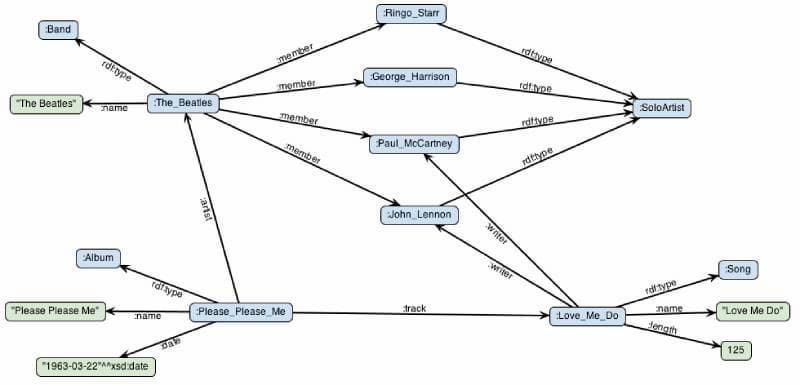
然后,它被转换为一个RDF三元组。首先,给出谓词的URL,以及相应的前缀。
In the above example, there are two URLs, indicating that two sets of predicates are used. One set is the official predicate, represented using the prefix rdf; the other set is self-defined, with an empty prefix, indicating that this is the default prefix.
The phrase “The Beatles are a band with John Lennon, Paul McCartney, Ringo Starr, and George Harrison.” corresponds to the following triplet.
In the above example, rdf:type, :name, and :member are all predicates. Since these triples have the same subject, RDF allows them to be merged.
In the above code, the triples with the same subject are written in a merged way, each triple is separated by a semicolon, and the last triple is terminated by a period.
The rest of the RDF triples are as follows.
SPARQL Query Language
SPARQL is a query language for RDF databases, much like the syntax of SQL. The core idea is to extract the eligible subject or object from a triple according to the given predicate verb.
The syntax of a SPARQL query is as follows.
In the above code, <variables> is the subject or object to be extracted, and <graph pattern> is the triple pattern to be queried.
For example, query all albums in the database.
In the above code, ?album is a variable with any name you want, but the first character must be a question mark ? . The query condition is that the variable ?album is the subject, and according to the predicate rdf:type, the object :Album can be obtained. This object also has a prefix indicating that this is defined by the current database.
The variable can be replaced by an asterisk * if all the records that match the condition are returned, and the keyword WHERE can be omitted inside the SELECT query, as well as the period at the end of the last triple, so the above query can also be written as the following.
|
|
In addition to the album name, if you want to return the artist of the album, you can add a variable ?artist.
In the above code, the variable ?artist must be the object of ?album (subject) and :artist (predicate).
Example of Wikidata query: Most populated areas in Shanxi Province
The following is a further study of SPARQL syntax by looking up “which is the most populous region in Shanxi Province” through Wikidata.
First, go to the Wikidata website (https://www.wikidata.org/), and search for “Shanxi” in the search field at the top of the page. Alternatively, Wikipedia’s “Shanxi Province” page has a link to Wikidata in the left column.
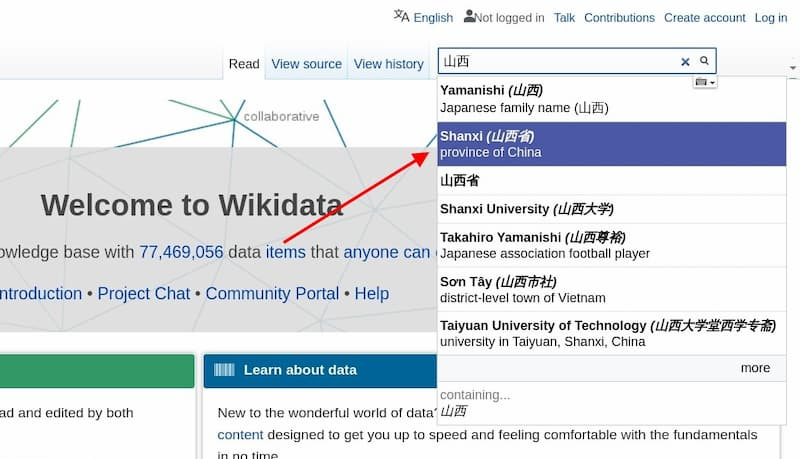
Then, go to the page of Shanxi Province.
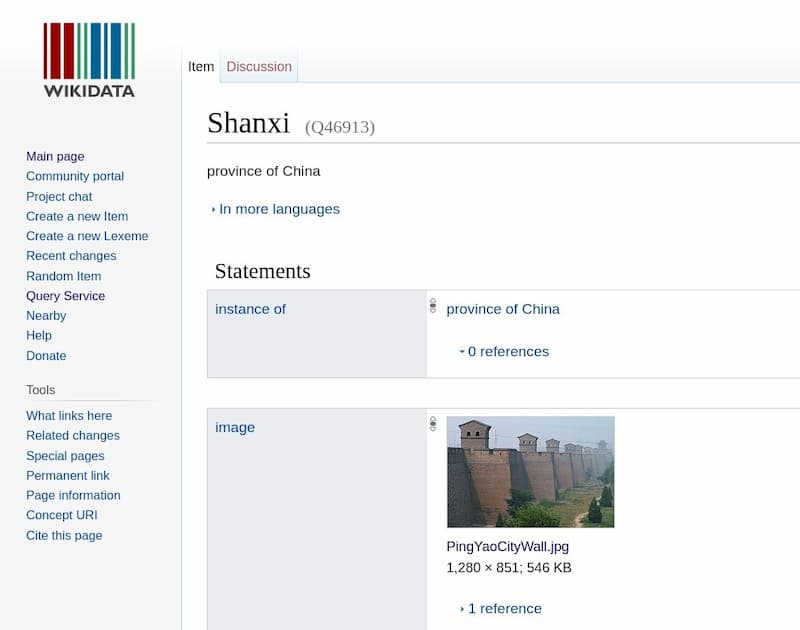
At this point, look for the URL of this page.
|
|
The Q46913 at the end of the URL above is the number (i.e. the subject) of the entry for Shanxi Province in the wiki data, which will be used later.
Next, scroll down the page and find the section “contains administrative territorial entity”, which lists the regions under Shanxi Province.
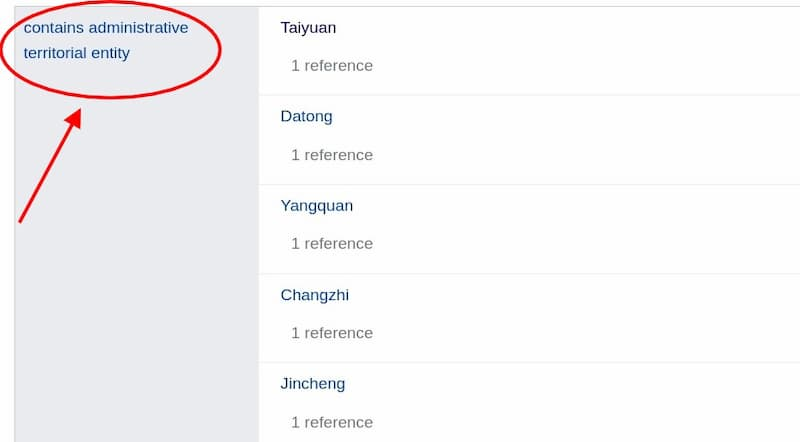
Click on the title “contains administrative territorial entity” to go to its page, and look for the URL as well.
|
|
The last part of the URL above, P150, is the number of the predicate verb “administrative entity included”.
Now, you can start the query. Go to Wikidata’s online query page query.wikidata.org
In the query box, enter the following SPARQL statement.
The above code requires the return of the variable ?area, which must satisfy the subject Shanxi Province (wd:Q46913) and the predicate administrative entity contained (wdt:P150). The prefix wd indicates that this is a wiki data entry, while the prefix wdt indicates that this is a predicate relationship defined by the wiki data.
Click the triangular Run button in the left sidebar to get the results of the query at the bottom of the page.
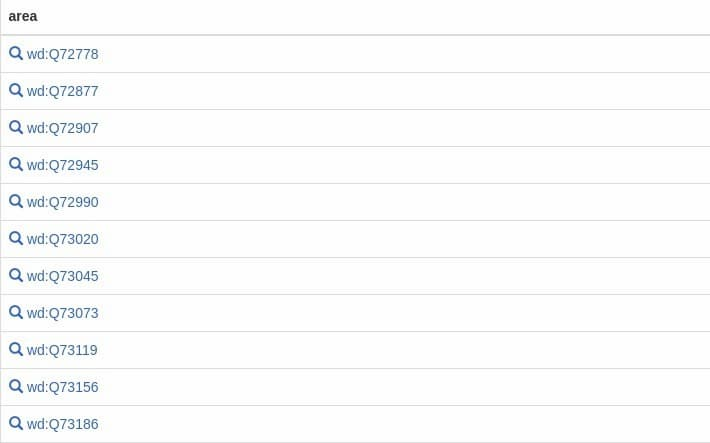
As you can see from the above image, the returned entries are numbered. Modify the query statement to add a column of text labels.
In the above code, add a returned variable ?areaLabel which is the text label of the previous variable ?area (satisfying the predicate rdfs:label), and add a filter statement FILTER which requires only Chinese labels to be returned.
Run this query and you will see the Chinese names for each area.
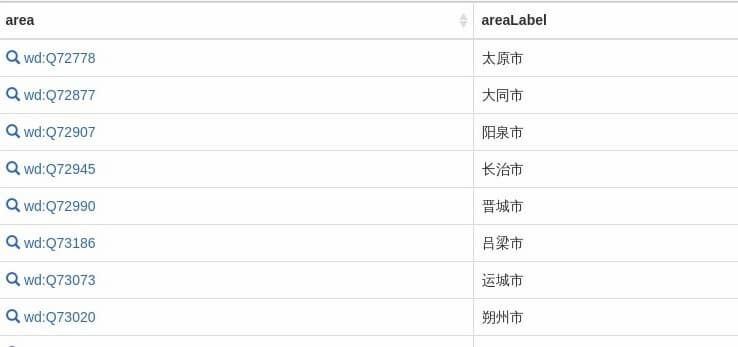
Next, add a population variable ?popTotal that returns the total number of people in each region.
Run this code and you will see the population total.

Then, add a sort clause order by to sort by the population in reverse order.
The results of the run are as follows.
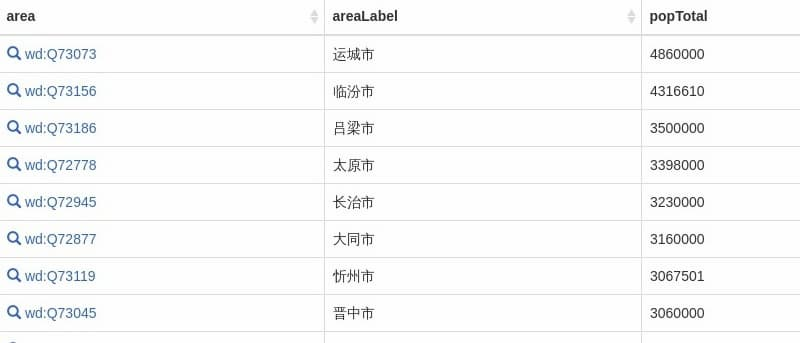
Finally, add a limit 1 clause to return only the first piece of data.

This gives us the most populated area in Shanxi Province.
Example of a wiki data query: Programmer Directory
Here is another example to find out all programmers of Wikipedia revenue.
In the above code, Q5482740 is the programmer and P106 is the occupation.
Run this query and you will see the list of programmers.
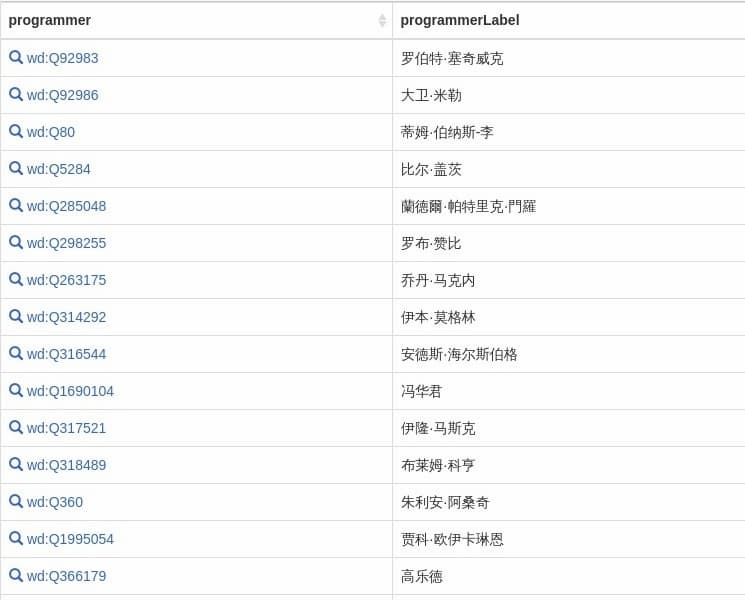
Note that only programmers with Chinese names are returned here. If there is no Chinese name of the programmer inside the database, it will not be returned here.
Then, query the main achievements of each programmer.
|
|
The results of the run are as follows.
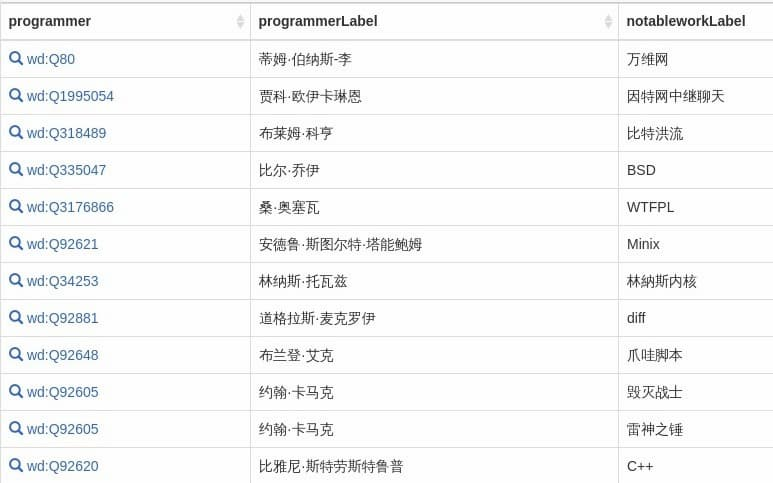
Some programmers have multiple achievements, for example, John Carmack has two achievements, “Doom” and “Thor’s Hammer”. You can use the GROUP BY clause to combine them together.
|
|
In the above code, the GROUP_CONCAT function is used to merge multiple ?notableworkLabel variables into a new column works.
The result is as follows.

In the picture above, “Doom” and “Thor’s Hammer” have been combined into one cell.
Next, add an avatar photo for each person.
|
|
In the above code, the return value adds a photo variable ?image. Since not everyone has a photo, the photo requirement is placed in the OPTIONAL condition, indicating that this item is optional.
After getting the query result, switch the table view of the result to the image grid.
At this point, the photo is ready to be displayed.

Finally, we want to know where they are from, and the wiki data provides their place of birth.
|
|
上面的代码在返回值中加入了坐标变量cood,首先查询了程序员的出生地,然后查询了出生地的地理坐标。
运行查询后,坐标出现在默认的表视图中。
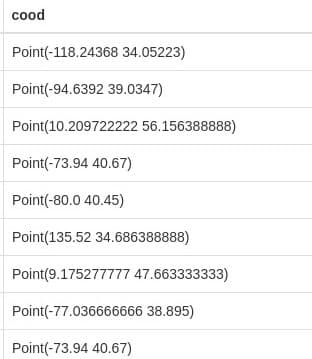
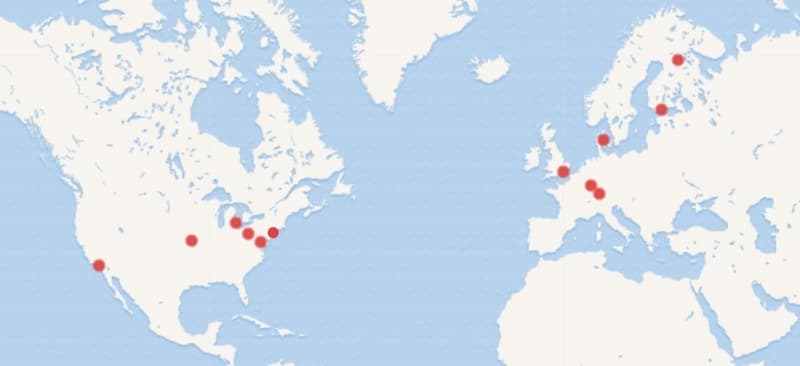
Switch the view to map.
This is where you can see where these programmers are located on the world map.
This tutorial ends here, there are many more ways to query wiki data, you can continue learning by clicking the Examples button in the header of Query Page to see the official examples provided.
Reference Links
- RDF, Wikipedia
- RDF Graph Data Model, Stardog
- Learn SPARQL, Stardog
- SPARQL Nuts & Bolts, Cambridge Semantics
- How to Extract Knowledge from Wikipedia, Data Science Style, Michael Li
Reference https://www.ruanyifeng.com/blog/2020/02/sparql.html