colly is a powerful crawler framework written in Go language . It provides a simple API, has strong performance, can automatically handle cookies & sessions, and provides a flexible extension mechanism.
First, we introduce the basic concept of colly. Then we introduce the usage and features of colly with a few examples: pulling GitHub Treading, pulling Baidu novel hotlist, downloading images from Unsplash .
Quick Use
Create the directory and initialize.
Install the colly library.
|
|
Use.
|
|
The use of colly is relatively simple.
First, call colly.NewCollector() to create a crawler object of type *colly.Collector. Since each page has many links to other pages. If left unrestricted, the run may never stop. So the above restricts to crawl only pages with domain www.baidu.com by passing an option colly.AllowedDomains("www.baidu.com").
Then we call the c.OnHTML method to register the HTML callback and execute the callback function for each a element that has the href attribute. Here we continue to access the URL pointed to by href, i.e. parse the crawled page and then continue to access links to other pages in the page.
Call the c.OnRequest() method to register the request callback, which is executed each time the request is sent, and simply prints the URL of the request.
Call the c.OnResponse() method to register the response callback, which is executed each time a response is received, and simply prints the URL and response size.
Call c.OnError() method to register the error callback, which is executed when an error occurs in the execution of the request, and here simply prints the URL and the error message.
Finally we call c.Visit() to start accessing the first page.
run:
|
|
After colly crawls the page, it parses the page using goquery. Then it looks for the registered HTML callback corresponding to the element-selector, and wraps goquery.Selection into a colly.HTMLElement execution callback.
The colly.HTMLElement is actually a simple wrapper around goquery.Selection.
and provides easy-to-use methods for.
Attr(k string): returns the attribute of the current element, in the above example we usede.Attr("href")to get thehrefattribute.ChildAttr(goquerySelector, attrName string): returns theattrNameattribute of the first child element selected bygoquerySelector.ChildAttrs(goquerySelector, attrName string): returns theattrNameattribute of all child elements selected bygoquerySelector, returned as a[]string.ChildText(goquerySelector string): Splices the text content of the child elements selected bygoquerySelectorand returns it.ChildTexts(goquerySelector string): returns a slice of the text content of the child element selected bygoquerySelector, returned as a[]string.ForEach(goquerySelector string, callback func(int, *HTMLElement)): Executes a callbackcallbackfor each child element selected bygoquerySelector.Unmarshal(v interface{}): Unmarshal an HTMLElement object into a structure instance by specifying a tag in goquerySelector format to the structure field.
These methods will be used frequently. Here we will introduce the features and usage of colly with some examples.
GitHub Treading
|
|
We use ChildText to get the author, repository name, language, number of stars and fork, today’s additions, etc., and ChildAttr to get the link to the repository, which is a relative path that is converted to an absolute path by calling the e.Request.AbsoluteURL() method.
Run.
Baidu Novel Hotlist
The web page structure is as follows.
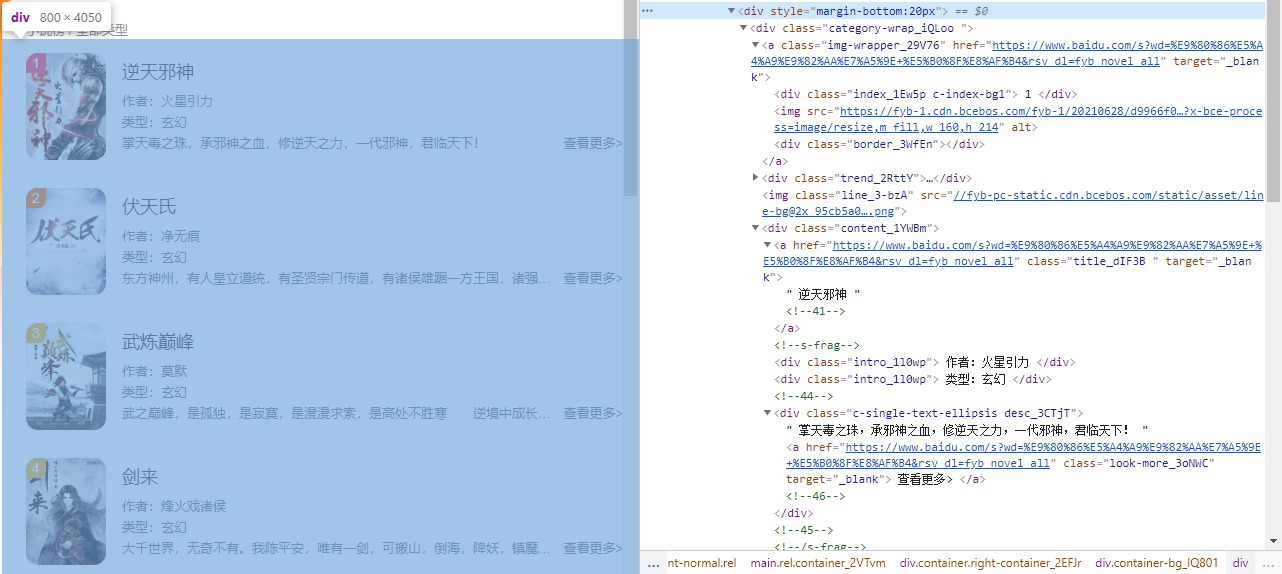
The structure of each section is as follows.
- each hotlist is each in a
div.category-wrap_iQLoo. div.index_1Ew5punder theaelement is the ranking.- content in
div.content_1YWBm. - content in
a.title_dIF3Bis the title. - two
div.intro_1l0wpin content, the first being the author and the second being the type. div.desc_3CTjTin the content is the description.
From this we define the structure.
|
|
tag is the CSS selector syntax, which is added so that the HTMLElement.Unmarshal() method can be called directly to populate the Hot object.
Then create the Collector object.
|
|
Registration Callback.
|
|
OnHTML performs Unmarshal on each entry to generate Hot objects.
OnRequest/OnResponse simply outputs debugging information.
Then, call c.Visit() to access the URL.
Finally add some debugging prints.
Run output.
Unsplash
I basically get my background images for my articles from unsplash, a site that offers a large, rich, and free collection of images. One problem with this site is that it is slow to access. Since we are learning to crawl, we just use the program to download the images automatically.
The unsplash home page is shown in the following image.
The web page structure is as follows.
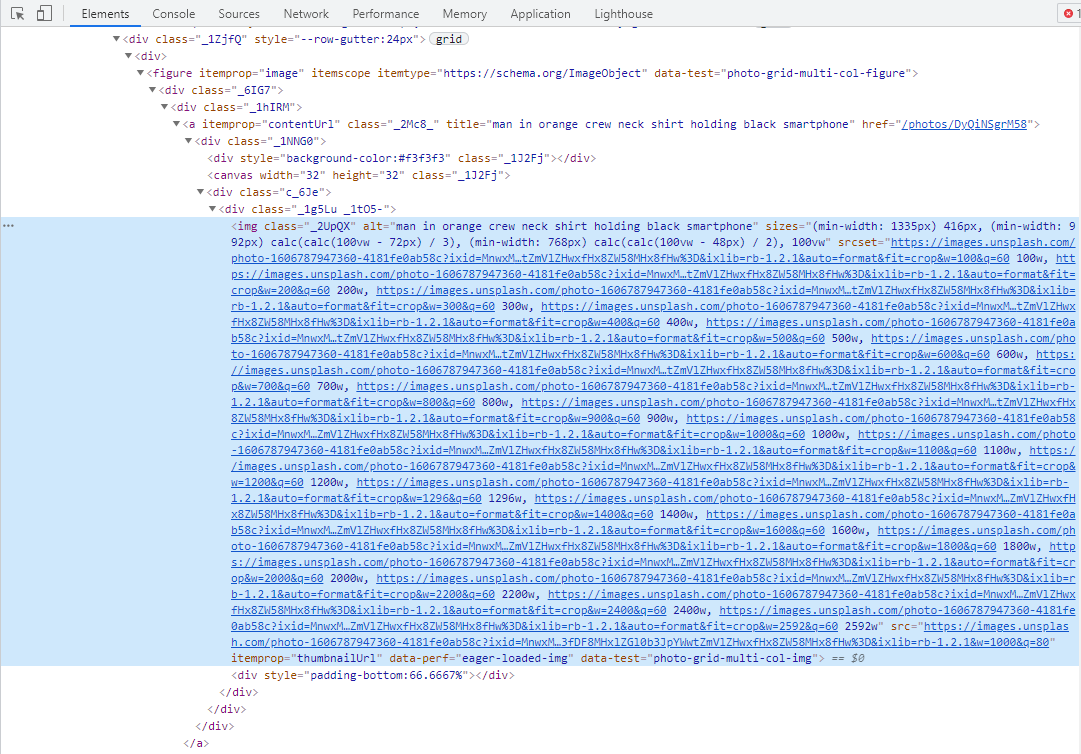
But the home page shows all the smaller size images, we click on a link to a particular image:.
Because of the three-layer web structure involved (img needs to be accessed once at the end), using a colly.Collector object, the OnHTML callback needs to be set with extra care, putting a relatively large mental burden on the coding. colly supports multiple Collectors, and we use this approach to code.
|
|
We use 3 Collector objects, the first Collector is used to collect the corresponding image links on the home page, then we use the second Collector to access these image links, and finally we let the third Collector to download the images. Above we also registered request and error callbacks for the first Collector.
The third Collector downloads the specific image content and saves it locally to.
|
|
The above uses atomic.AddUint32() to generate serial numbers for the images.
Run the program and crawl the results.
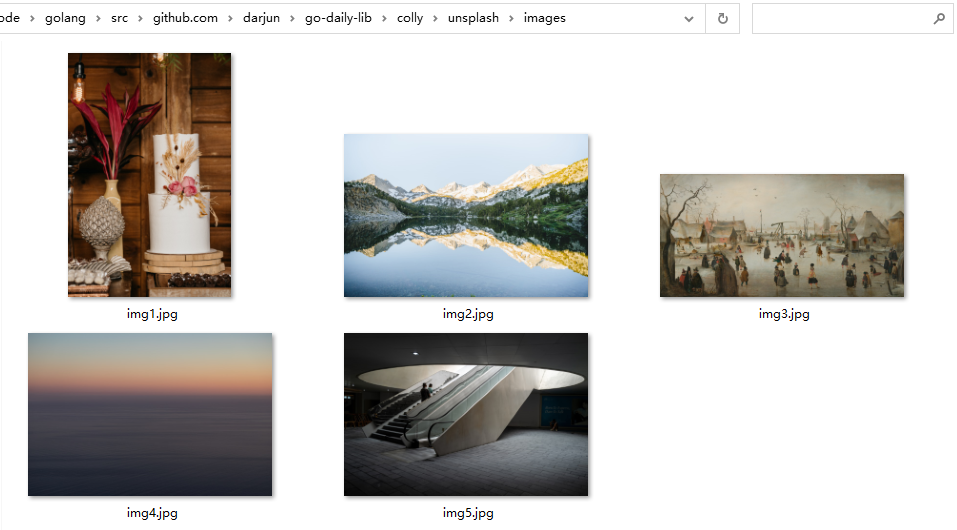
Asynchronous
By default, colly crawls web pages synchronously, i.e. one crawls after another, as in the unplash program above. This takes a long time, colly provides asynchronous crawling, we just need to pass the option colly.Async(true) when constructing the Collector object to enable asynchronous: colly.Async(true).
However, since it is an asynchronous crawl, the program needs to wait for Collector to finish processing at the end, otherwise it will exit main early and the program will quit: the
Running again, much faster 😀.
Second Edition
Scrolling down the unsplash page, we see that the image behind it is loaded asynchronously. Scroll down the page and view the request through the network tab of the chrome browser.
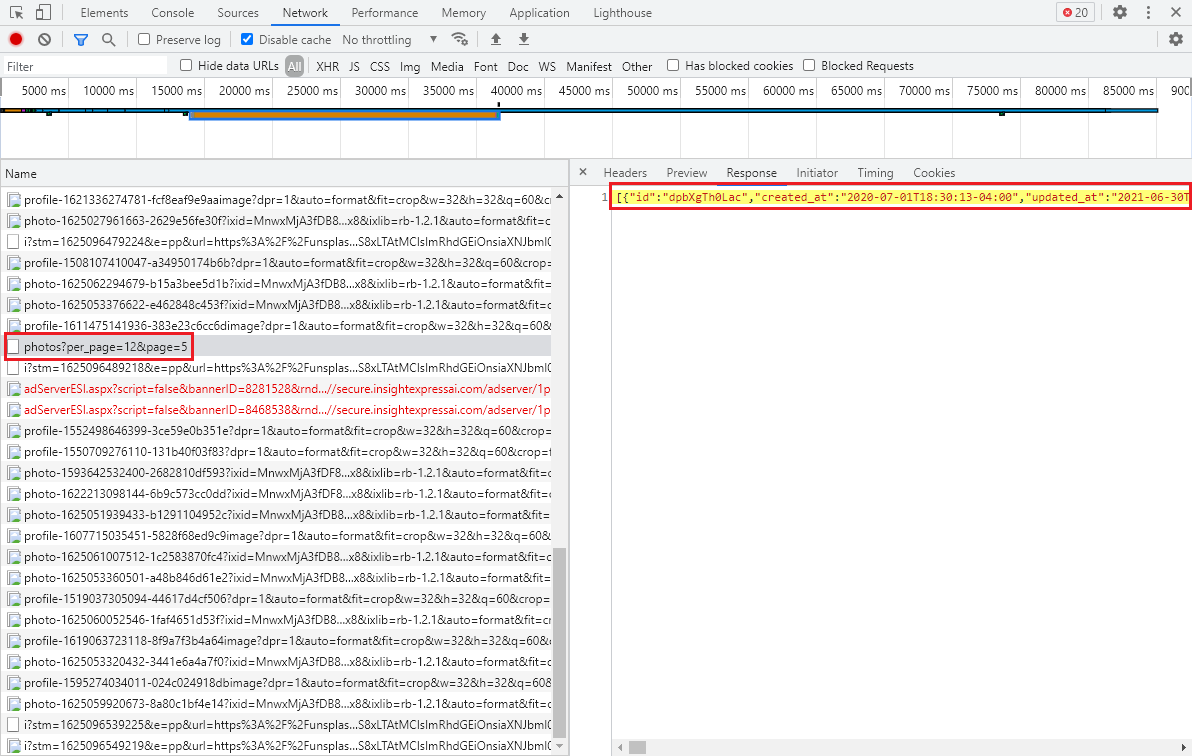
Requesting the path /photos, setting the per_page and page parameters, returns a JSON array. So there is an alternative way.
Define a structure for each item, where we keep only the necessary fields.
The JSON is then parsed in the OnResponse callback, and the Visit() method of the Collector responsible for downloading the image is called for each Download link.
To initialize the visit, we set up a pull of 3 pages, 12 per page (consistent with the number of page requests).
Run and view the downloaded images at
Request Limits
Sometimes there are too many concurrent requests and the site will restrict access. That’s where LimitRule comes in. To put it plainly, LimitRule is what limits access speed and concurrency.
The common ones are Delay/RandomDelay/Parallism, which indicate the request-to-request delay, random delay, and concurrency, respectively. Also must specify which domains are restricted, set via DomainRegexp or DomainGlob, if neither of these fields is set the Limit() method returns an error. Used in the above example.
We set a random maximum request-to-request delay of 500ms for the domain unsplash.com, with a maximum of 12 concurrent requests.
Set timeout
Sometimes the network is slow and the http.Client used in colly has a default timeout mechanism, which we can rewrite with the colly.WithTransport() option.
|
|
Extensions
colly provides some extensions in the subpackage extension, the most common one being the random User-Agent. Usually a website will use the User-Agent to identify whether a request is sent by a browser, and crawlers usually set this Header to disguise themselves as browsers. It is also relatively simple to use.
The random User-Agent implementation is also simple: a random one from some pre-defined User-Agent array is set in the Header.
It is not difficult to implement your own extension, for example, if we need to set a specific Header for each request, the extension can be written like this.
Calling the MyHeader() function with the Collector object is sufficient.
|
|
Summary
colly is the most popular crawler framework in the Go language, supporting a rich set of features. This article introduces some common features, with examples. Due to space constraints, some advanced features are not covered, such as queues, storage and so on. If you are interested in crawling, you can go deeper.
Reference https://darjun.github.io/2021/06/30/godailylib/colly/