There are numerous problems with the installation and operation of components such as Hadoop and Hive on Windows systems
With the help of several Internet references, I completed the construction of Hadoop and Hive development environment on Windows 10. This article documents the specific steps, problems encountered, and corresponding solutions for the entire build process.
Environmental Preparation
| Software | Version | Description |
|---|---|---|
| Windows | 10 | Operating System |
| JDK | 8 | Do not use a version greater than or equal to JDK9 for the time being, because unknown exceptions will occur when starting the virtual machine |
| MySQL | 8.x | Metadata for managing Hive |
| Apache Hadoop | 3.3.0 | - |
| Apache Hive | 3.1.2 | - |
| Apache Hive src | 1.2.2 | Because only the 1.x version of the Hive source code provides a .bat startup script, the ability to write their own scripts do not need to download this source code package |
| winutils | hadoop-3.3.0 | Startup dependencies for Hadoop on Windows |
Some of the components are listed below with their corresponding download addresses:
- Apache Hadoop 3.3.0:https://mirror.bit.edu.cn/apache/hadoop/common/hadoop-3.3.0/hadoop-3.3.0.tar.gz
- Apache Hive 3.1.2:https://mirrors.bfsu.edu.cn/apache/hive/hive-3.1.2/apache-hive-3.1.2-bin.tar.gz
- Apache Hive 1.2.2 src:https://mirrors.bfsu.edu.cn/apache/hive/hive-1.2.2/apache-hive-1.2.2-src.tar.gz
- winutils:https://github.com/kontext-tech/winutils
After downloading some of these software, MySQL is installed normally as a system service with system self-start. Unzip hadoop-3.3.0.tar.gz, apache-hive-3.1.2-bin.tar.gz, apache-hive-1.2.2-src.tar.gz and winutils to the specified directory
Next, copy the files in the bin directory of the unpacked source package apache-hive-1.2.2-src.tar.gz to the bin directory of `apache-hive-3.1.2-bin:.
Then copy the hadoop.dll and winutils.exe files from the hadoop-3.3.0\bin directory in winutils to the bin folder in the unpacked directory of Hadoop.
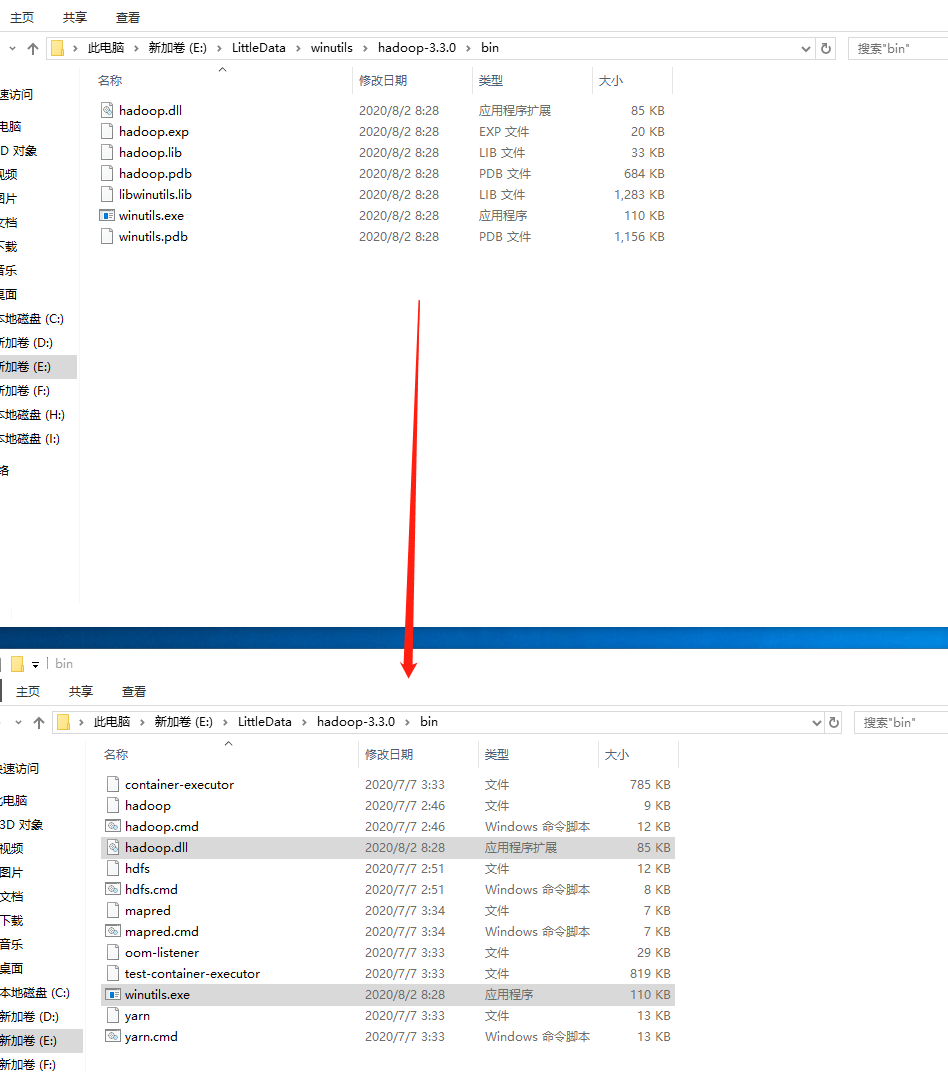
Finally, configure the JAVA_HOME and HADOOP_HOME environment variables, and add %JAVA_HOME%\bin; and %HADOOP_HOME%\bin to the Path:
Next, test it on the command line. If the above steps are OK, the console output will be as follows.
Configuring and starting Hadoop
In the etc\hadoop subdirectory of HADOOP_HOME, find and modify the following configuration files.
core-site.xml (the tmp directory here must be configured as a non-virtual directory, don’t use the default tmp directory, otherwise you will encounter permission assignment failure problems later)
hdfs-site.xml (here to pre-create nameNode and dataNode data storage directory, note that each directory should start with /, I pre-create nameNode and dataNode subdirectories in HADOOP_HOME/data here)
|
|
mapred-site.xml
yarn-site.xml
At this point, the minimalist configuration is basically complete. Then you need to format the namenode and start the Hadoop service. Switch to the $HADOOP_HOME/bin directory, use CMD to enter the command hdfs namenode -format (format namenode remember not to repeat the execution).
After formatting namenode, switch to the $HADOOP_HOME/sbin directory and execute the start-all.cmd script.
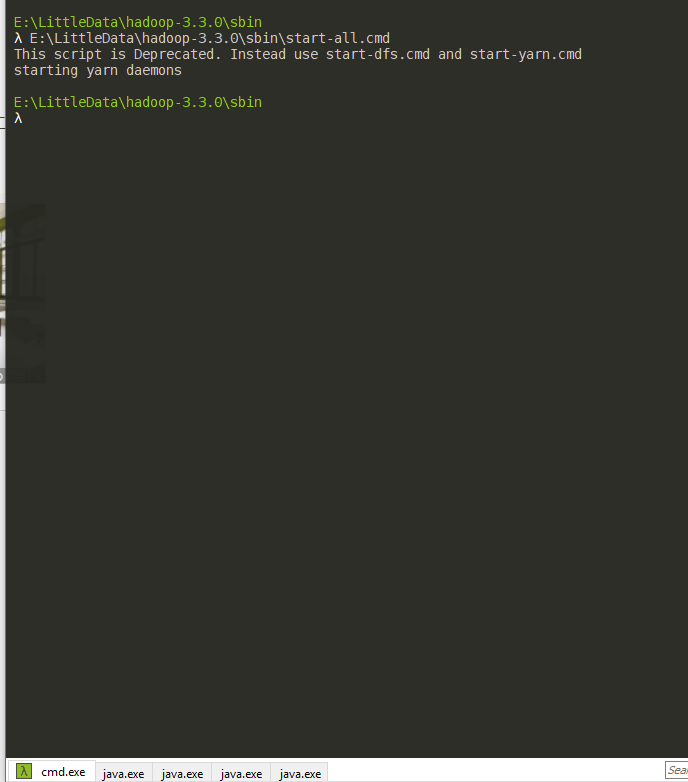
Here the command line will prompt start-all.cmd script has expired, it is recommended to use start-dfs.cmd and start-yarn.cmd instead. Similarly, if the execution of stop-all.cmd will also have a similar prompt, you can use stop-dfs.cmd and stop-yarn.cmd instead. After the successful execution of start-all.cmd, four JVM instances will be created (see the above figure in the Shell window automatically created four new Tabs), at this time you can view the current JVM instances through jps.
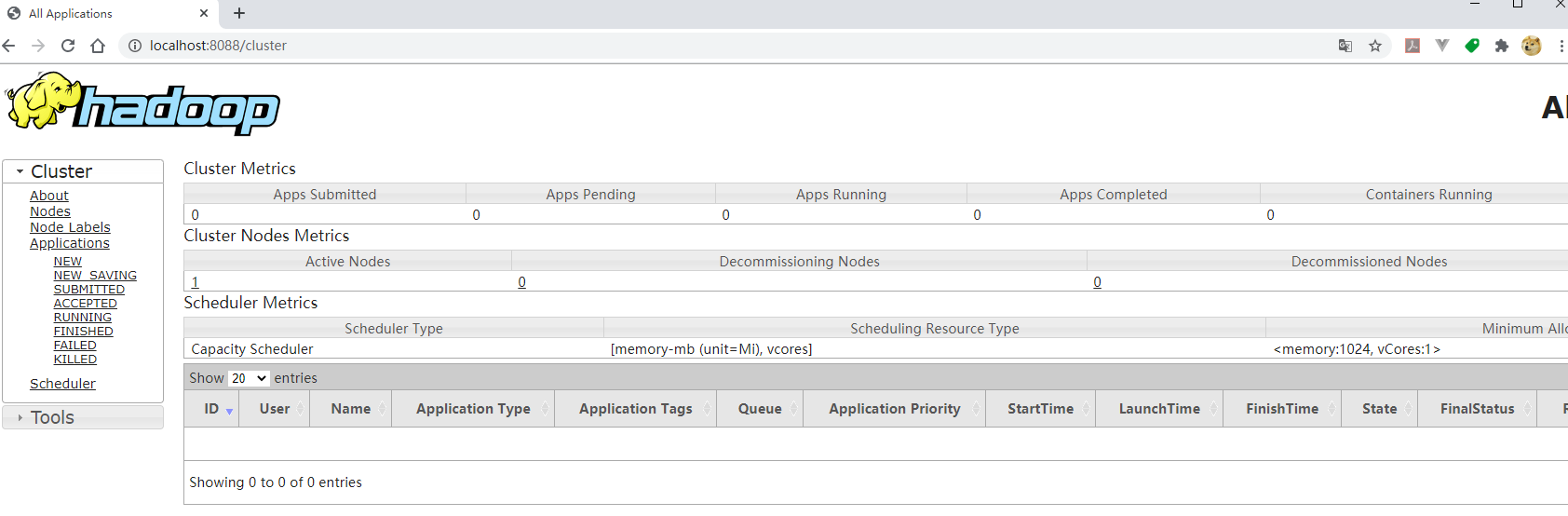
You can see that four applications ResourceManager, NodeManager, NameNode and DataNode have been started, so that the standalone version of Hadoop has been started successfully. Exit these four processes with the stop-all.cmd command. You can check the status of the scheduling tasks via http://localhost:8088/:
Go through http://localhost:50070/ to see the status of HDFS and the files.
To restart Hadoop: execute the stop-all.cmd script first, then the start-all.cmd script.
Configuring and starting Hive
Hive is built on HDFS, so make sure Hadoop is up and running; the default file path for Hive in HDFS is prefixed with /user/hive/warehouse, so you can create this folder in HDFS from the command line first
You also need to create and grant permissions to the tmp directory with the following command.
Add HIVE_HOME to the system variables, configure the specific value as E:\LittleData\apache-hive-3.1.2-bin, and add %HIVE_HOME%\bin; to the Path variable, similar to the previous configuration of HADOOP_HOME. Download and copy a mysql-connector-java-8.0.x.jar to the `$HIVE_HOME/lib directory.
To create the Hive configuration file, there is already a corresponding configuration file template in the $HIVE_HOME/conf directory, which needs to be copied and renamed as follows:
- $HIVE_HOME/conf/hive-default.xml.template => $HIVE_HOME/conf/hive-site.xml
- $HIVE_HOME/conf/hive-env.sh.template => $HIVE_HOME/conf/hive-env.sh
- $HIVE_HOME/conf/hive-exec-log4j.properties.template => - $HIVE_HOME/conf/hive-exec-log4j.properties
- $HIVE_HOME/conf/hive-log4j.properties.template => $HIVE_HOME/conf/hive-log4j.properties
Modify the hive-env.sh script by adding the following to the end.
Modify the hive-site.xml file, mainly by changing the following property items.
| Property Name | Property Value | Remarks |
|---|---|---|
hive.metastore.warehouse.dir |
/user/hive/warehouse |
The data storage directory for Hive, which is the default value |
hive.exec.scratchdir |
/tmp/hive |
The temporary data directory for Hive, which is the default value |
javax.jdo.option.ConnectionURL |
jdbc:mysql://localhost:3306/hive?characterEncoding=UTF-8&serverTimezone=UTC |
Hive database connection for metadata storage |
javax.jdo.option.ConnectionDriverName |
com.mysql.cj.jdbc.Driver |
Database driver for Hive metadata storage |
javax.jdo.option.ConnectionUserName |
root |
Hive database user for metadata storage |
javax.jdo.option.ConnectionPassword |
root |
Password of the database where Hive metadata is stored |
hive.exec.local.scratchdir |
E:/LittleData/apache-hive-3.1.2-bin/data/scratchDir |
Create local directory $HIVE_HOME/data/scratchDir |
hive.downloaded.resources.dir |
E:/LittleData/apache-hive-3.1.2-bin/data/resourcesDir |
Create local directory $HIVE_HOME/data/resourcesDir |
hive.querylog.location |
E:/LittleData/apache-hive-3.1.2-bin/data/querylogDir |
Create local directory $HIVE_HOME/data/querylogDir |
hive.server2.logging.operation.log.location |
E:/LittleData/apache-hive-3.1.2-bin/data/operationDir |
Create local directory $HIVE_HOME/data/operationDir |
datanucleus.autoCreateSchema |
true |
Optional |
datanucleus.autoCreateTables |
true |
Optional |
datanucleus.autoCreateColumns |
true |
Optional |
hive.metastore.schema.verification |
false |
Optional |
After the modification, the local MySQL service to create a new database hive, encoding and character set can choose a relatively large range of utf8mb4 (although the official recommendation is latin1, but the character set to a wide range of options have no impact):
After the above preparations are done, you can perform the initialization of the Hive metadatabase by executing the following script in the $HIVE_HOME/bin directory.
|
|
Here’s a little problem, line 3215 of the hive-site.xml file has a magic unrecognizable symbol

This unrecognizable symbol will cause Hive’s command execution exceptions and needs to be removed. When the console outputs Initialization script completed schemaTool completed, it means that the metadatabase has been initialized.

In the $HIVE_HOME/bin directory, you can connect to Hive via hive.cmd (close the console to exit)
|
|
Try to create a table t_test
Check http://localhost:50070/ to confirm that the t_test table has been created successfully.
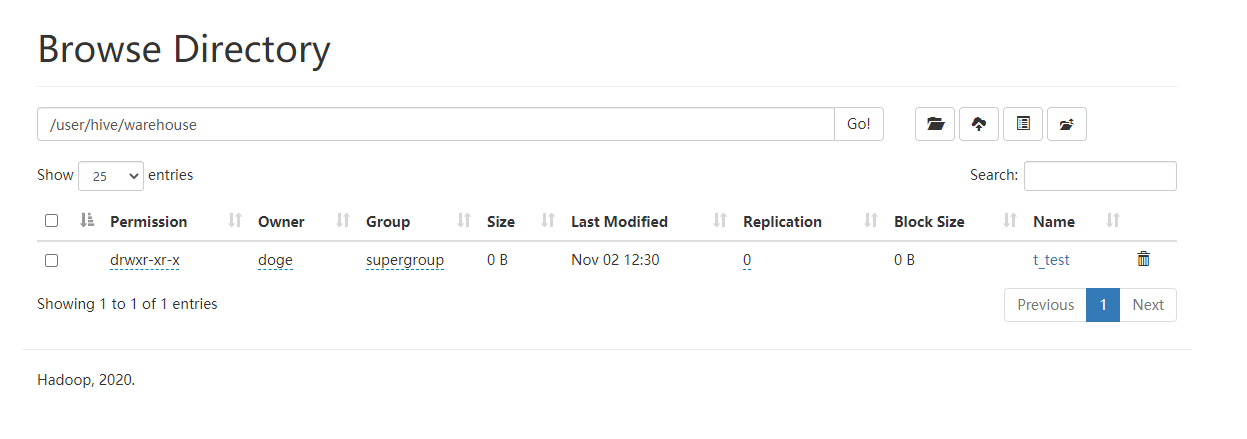
Try to execute a write statement and a query statement.
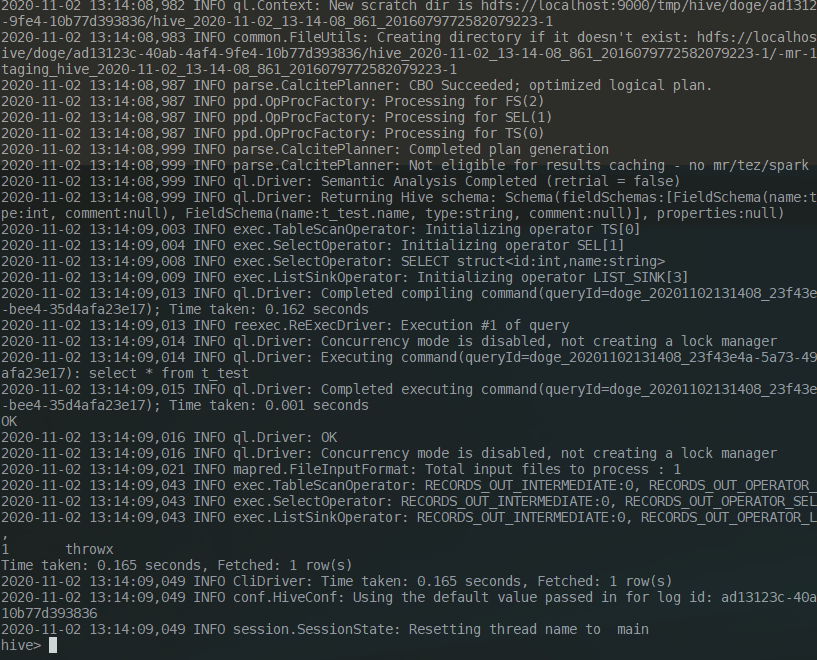
It took more than 30 seconds to write and 0.165 seconds to read.
Connecting to Hive using JDBC
HiveServer2 is the Hive server-side interface module, which must be started for remote clients to write and query data to Hive. Currently, this module is still based on Thrift RPC implementation, which is an improved version of HiveServer, supporting multi-client access and authentication and other functions. The following common properties of HiveServer2 can be modified in the configuration file hive-site.xml
| Property Name | Property Value | Remark |
|---|---|---|
| hive.server2.thrift.min.worker.threads | 5 | Minimum number of threads to work with, default value is 5 |
| hive.server2.thrift.max.worker.threads | 500 | Maximum number of working threads, default value is 500 |
| hive.server2.thrift.port | 10000 | The TCP port number to listen on, the default value is 10000 |
| hive.server2.thrift.bind.host | 127.0.0.1 | Bound host, the default value is 127.0.0.1 |
| hive.execution.engine | mr | Execution engine, default value is mr |
Execute the following command in the $HIVE_HOME/bin directory to start HiveServer2
|
|
The client needs to introduce hadoop-common and hive-jdbc dependencies, and try to correspond to the Hadoop and Hive versions.
|
|
The hadoop-common dependency chain is quite long and will download a lot of other related dependencies along with it, so you can find some free time to hang the task of downloading that dependency in some Maven project first. Finally add a unit test class HiveJdbcTest
|
|
Possible problems encountered
Java virtual machine startup failure
Currently positioned to be Hadoop can not use any version of JDK [9 + JDK, it is recommended to switch to any small version of JDK8.
Hadoop execution file not found exception
Make sure you have copied the hadoop.dll and winutils.exe files from the hadoop-3.3.0\bin directory in winutils to the bin folder of the unpacked directory of Hadoop.
When executing the start-all.cmd script, there is a possibility that the batch script cannot be found. This problem has occurred on the company’s development machine, but has not been reproduced on the home development machine. The specific solution is to add cd $HADOOP_HOME to the first line of the start-all.cmd script, such as cd E:\LittleData\hadoop-3.3.0.
Unable to access localhost:50070
Generally because the hdfs-site.xml configuration misses the dfs.http.address configuration item, add.
Then just call stop-all.cmd and then call start-all.cmd to restart Hadoop.
Hive connection to MySQL exception
Note whether the MySQL driver package has been copied correctly to $HIVE_HOME/lib and check whether the four properties javax.jdo.option.ConnectionURL and so on are configured correctly. If they are all correct, pay attention to whether there is a problem with the MySQL version or the service version does not match the driver version.
Hive can’t find the batch file
The general description is xxx.cmd' is not recognized as an internal or external command... , which is usually an exception in Hive’s command execution, you need to copy all the .cmd scripts in the bin directory of the Hive 1.x source package to the corresponding directory of $HIVE_HOME/bin.
Folder permission issues
Common exceptions such as CreateSymbolicLink can cause Hive to be unable to write data using INSERT or LOAD commands. Such problems can be solved by the following.
Win + R and run gpedit.msc - Computer Settings - Windows Settings - Security Settings - Local Policies - User Rights Assignment - Create Symbolic Link - Add Current User.
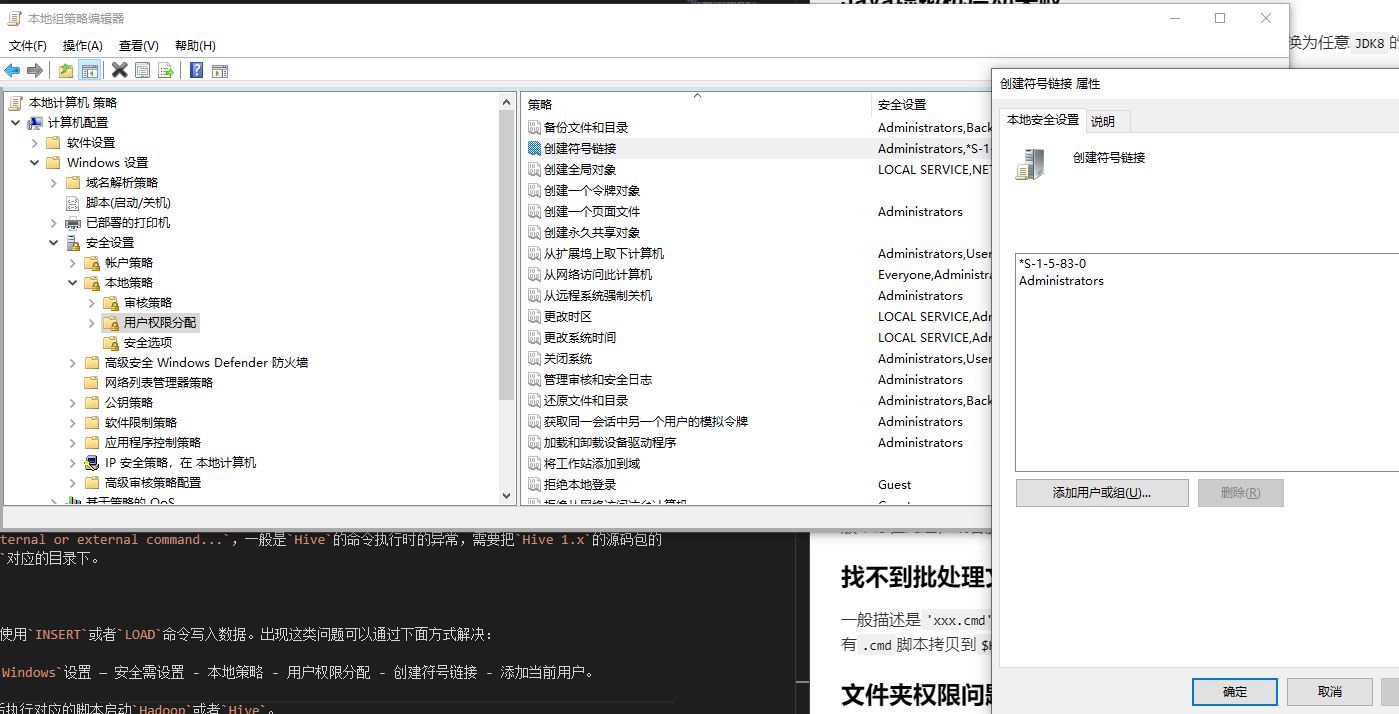
Or just start CMD with administrator account or administrator privileges, and then execute the corresponding script to start Hadoop or Hive.
SessionNotRunning exception
This exception may occur when starting HiveServer2 or when an external client connects to HiveServer2, specifically java.lang.ClassNotFoundException: org.apache.tez.dag.api.TezConfiguration exception. The solution is: the configuration file hive-site.xml in the hive.execution.engine property value from tez to mr, and then restart HiveServer2 can be. Because there is no tez integration, the restart will still report an error, but after 60000ms it will automatically retry to start (usually after the retry will start successfully):
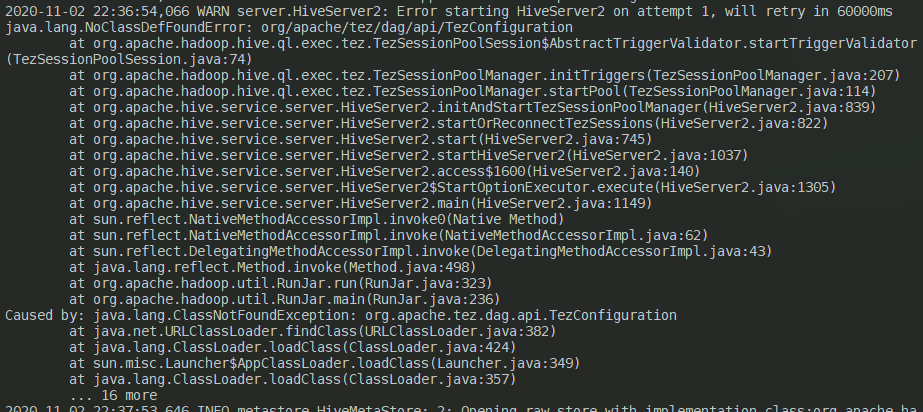
This is a legacy issue, but it does not affect the client’s normal connection, only the startup time will be 60 seconds longer.
HiveServer2 port conflict
Modify the value of the hive.server2.thrift.port property in the configuration file hive-site.xml to an unoccupied port, and restart HiveServer2.
Data node security mode exception
Generally SafeModeException exceptions appear, prompting Safe mode is ON. Through the command hdfs dfsadmin -safemode leave to remove the safe mode.
AuthorizationException
It is common for this exception to occur when Hive connects to the HiveServer2 service via the JDBC client, specifically the message: `User: xxx is not allowed to impersonate anonymous. this case just needs to modify the Hadoop configuration file core-site. xml, add.
Then just restart the Hadoop service.
MapRedTask’s Permissions Problem
The common exception is thrown when Hive connects to the HiveServer2 service via a JDBC client to perform an INSERT or LOAD operation, generally described as Execution Error, return code 1 from org.apache.hadoop.hive.ql.exec MapRedTask. Permission denied: user=anonymous, access=EXECUTE, inode="/tmp/hadoop-yarn":xxxx:supergroup:drwx------. Just give the anonymous user /tmp directory read and write access through the command hdfs dfs -chmod -R 777 /tmp.
Summary
It is better to build the development environment of Hadoop and Hive directly in Linux or Unix system. The file path and permission problems of Windows system can lead to many unexpected problems. This article refers to a large number of Internet materials and introductory books on Hadoop and Hive, so I won’t post them here, standing on the shoulders of giants.
Reference https://www.throwx.cn/2020/11/03/hadoop-hive-dev-env-in-win-10/