kube-scheduler is one of the core components of kubernetes, which is mainly responsible for the scheduling function of the entire cluster resources, according to specific scheduling algorithms and strategies, the pod will be scheduled to the optimal node above the working nodes, so as to make more reasonable and full use of the cluster resources, which is also a very important reason why we choose to use kubernetes. This is a very important reason why we chose to use kubernetes. If a new technology can’t help enterprises save costs and provide efficiency, I believe it’s very difficult to promote.
The scheduling process
By default, the default scheduler provided by kube-scheduler is able to satisfy most of our requirements, and the examples we’ve touched on earlier basically use the default policy, which ensures that our Pods can be assigned to run on well-resourced nodes. However, in a real online project, we may know our application better than kubernetes, for example, we may want a Pod to run only on certain nodes, or these nodes can only be used to run certain types of applications, which requires our scheduler to be controllable.
The main purpose of kube-scheduler is to schedule Pods to appropriate Node nodes according to specific scheduling algorithms and scheduling policies. It is a standalone binary that listens to the API Server all the time after startup and gets Pods with empty PodSpec.NodeName, and for each Pod, it creates a binding for each Pod.
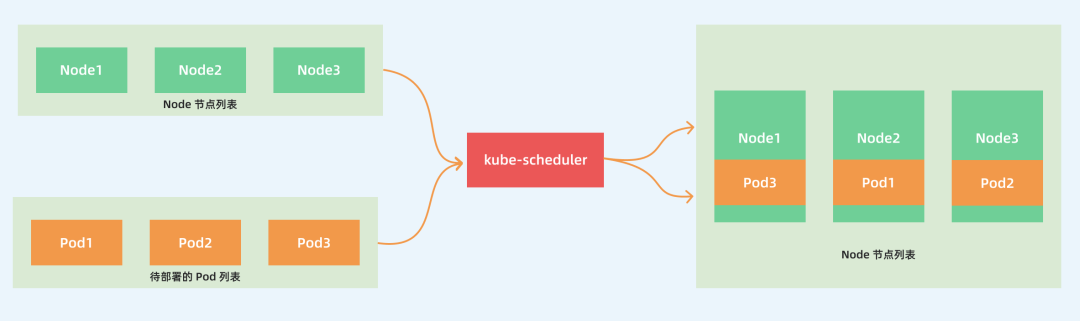
This process seems relatively simple to us, but in a real production environment, there are many issues to consider:
- How to ensure the fairness of all node scheduling? It is important to know that not all nodes are necessarily allocated the same resources.
- How to ensure that each node can be allocated resources?
- How can cluster resources be used efficiently?
- How can cluster resources be maximised?
- How to ensure the performance and efficiency of Pod scheduling?
- Can users customise their own scheduling policies according to their actual needs?
Considering the various complexities of the actual environment, kubernetes scheduler is implemented in the form of a plugin, which can be easily customised or developed twice, we can customise a scheduler and integrate it with kubernetes in the form of a plugin.
The source code for the kubernetes scheduler is located in kubernetes/pkg/scheduler, and the core program that the scheduler creates and runs is located in pkg/scheduler/scheduler.go. If you want to see the entry point for kube-scheduler, the corresponding code is in cmd/kube-scheduler/scheduler.go.
Scheduling is divided into the following main parts:
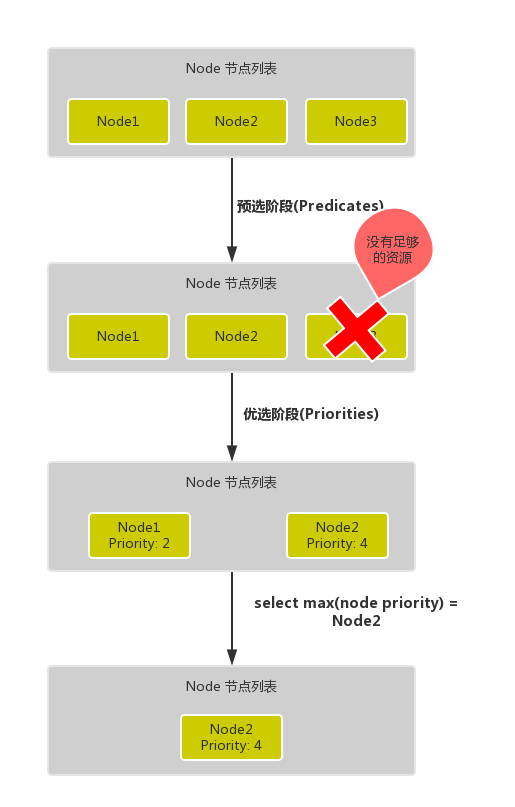
- Firstly, there is the pre-selection process, which filters out nodes that do not fulfil the conditions, a process called
Predicates.
- Then there is the Preferences process, where the passed nodes are sorted in order of priority, called
Priorities.
- Finally, the node with the highest priority is chosen from them, and if there is an error in any of the intermediate steps, the error is returned directly
The Predicates phase first traverses all the nodes and filters out the nodes that do not satisfy the condition, which belongs to the Mandatory rule, all the nodes that satisfy the requirement in the output of this phase will be logged and used as inputs for the second phase, if all the nodes do not satisfy the condition then the Pod will remain in the Pending state until one of them satisfies the condition, during this period the scheduler will keep retrying.
So when we are deploying an application, if we find that a Pod is always in Pending state, then the Pod is a node that does not meet the scheduling conditions, and we can check whether the node resources are available.
In the Priorities phase, the nodes are filtered again, and if more than one node meets the conditions, then the system will sort the nodes according to their priority (priorites) size, and finally select the node with the highest priority to deploy the Pod application.
The following is a simple diagram of the scheduling process:
The more detailed process looks like this:
- First, the client creates a Pod resource via API Server’s REST API or kubectl tool.
- The API Server receives the user request and stores the relevant data in the etcd database.
- The scheduler listens to the API Server to see the list of pods that have not yet been scheduled (bind), and iteratively tries to assign a node to each pod, which is the two phases we mentioned above:
- Predicates, filtering nodes, the scheduler uses a set of rules to filter out Node nodes that do not meet the requirements, for example, the Pod has set a request for resources, then the hosts with fewer resources available than the Pod needs will obviously be filtered out.
- Priorities stage (Priorities), for the priority of the node scoring, the previous stage of filtering out the list of Node scoring, the scheduler will take into account some of the overall optimisation strategy, such as the Deployment control of multiple copies of the Pod as far as possible to distribute to different hosts, the use of the least loaded hosts and so on.
- After the above stages of filtering, the highest scoring Node nodes and Pods are selected for
binding operations, and the results are stored in etcd. The kubelet corresponding to the last selected Node node performs the relevant operations to create the Pod (and of course, watches for APIServer discovery).
The scheduler has now implemented the scheduling framework all by means of plug-ins, and the built-in scheduling plug-ins that are turned on by default are shown in the following code:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
|
// pkg/scheduler/framework/plugins/registry.go
// NewInTreeRegistry Build the registry using all internal plugins.
// External plugins can register additional plugins through the WithFrameworkOutOfTreeRegistry option.
func NewInTreeRegistry() runtime.Registry {
fts := plfeature.Features{
EnableDynamicResourceAllocation: feature.DefaultFeatureGate.Enabled(features.DynamicResourceAllocation),
EnableReadWriteOncePod: feature.DefaultFeatureGate.Enabled(features.ReadWriteOncePod),
EnableVolumeCapacityPriority: feature.DefaultFeatureGate.Enabled(features.VolumeCapacityPriority),
EnableMinDomainsInPodTopologySpread: feature.DefaultFeatureGate.Enabled(features.MinDomainsInPodTopologySpread),
EnableNodeInclusionPolicyInPodTopologySpread: feature.DefaultFeatureGate.Enabled(features.NodeInclusionPolicyInPodTopologySpread),
EnableMatchLabelKeysInPodTopologySpread: feature.DefaultFeatureGate.Enabled(features.MatchLabelKeysInPodTopologySpread),
EnablePodSchedulingReadiness: feature.DefaultFeatureGate.Enabled(features.PodSchedulingReadiness),
}
registry := runtime.Registry{
dynamicresources.Name: runtime.FactoryAdapter(fts, dynamicresources.New),
selectorspread.Name: selectorspread.New,
imagelocality.Name: imagelocality.New,
tainttoleration.Name: tainttoleration.New,
nodename.Name: nodename.New,
nodeports.Name: nodeports.New,
nodeaffinity.Name: nodeaffinity.New,
podtopologyspread.Name: runtime.FactoryAdapter(fts, podtopologyspread.New),
nodeunschedulable.Name: nodeunschedulable.New,
noderesources.Name: runtime.FactoryAdapter(fts, noderesources.NewFit),
noderesources.BalancedAllocationName: runtime.FactoryAdapter(fts, noderesources.NewBalancedAllocation),
volumebinding.Name: runtime.FactoryAdapter(fts, volumebinding.New),
volumerestrictions.Name: runtime.FactoryAdapter(fts, volumerestrictions.New),
volumezone.Name: volumezone.New,
nodevolumelimits.CSIName: runtime.FactoryAdapter(fts, nodevolumelimits.NewCSI),
nodevolumelimits.EBSName: runtime.FactoryAdapter(fts, nodevolumelimits.NewEBS),
nodevolumelimits.GCEPDName: runtime.FactoryAdapter(fts, nodevolumelimits.NewGCEPD),
nodevolumelimits.AzureDiskName: runtime.FactoryAdapter(fts, nodevolumelimits.NewAzureDisk),
nodevolumelimits.CinderName: runtime.FactoryAdapter(fts, nodevolumelimits.NewCinder),
interpodaffinity.Name: interpodaffinity.New,
queuesort.Name: queuesort.New,
defaultbinder.Name: defaultbinder.New,
defaultpreemption.Name: runtime.FactoryAdapter(fts, defaultpreemption.New),
schedulinggates.Name: runtime.FactoryAdapter(fts, schedulinggates.New),
}
return registry
}
|
From the above we can see that a series of algorithms of the scheduler are done by various plug-ins at different stages of the scheduling, and we will start with the scheduling framework below.
Scheduling framework
The scheduling framework defines a set of extension points. Users can implement the interfaces defined by the extension points to define their own scheduling logic (we call them extensions) and register the extensions to the extension points. The scheduling framework will call the user-registered extensions when it encounters the corresponding extension points during the execution of the scheduling workflow. Scheduling frameworks have a specific purpose in reserving extension points, some extensions on extension points can change the decision making method of the scheduler, some extensions on extension points just send a notification.
We know that whenever a Pod is scheduled, it follows two processes: the scheduling process and the binding process.
The scheduling process selects a suitable node for a Pod, and the binding process applies the decisions of the scheduling process to the cluster (i.e., runs the Pod on the selected node), which together is called the scheduling context. Note that the scheduling process runs ``synchronously’’ (scheduling for only one Pod at a time), and the binding process can run asynchronously (binding for multiple Pods concurrently at a time).
The scheduling and binding processes exit in the following cases:
- The scheduler believes that there are currently no optional nodes for the Pod
- Internal error
At this point, the Pod is put back into the pending queue and waits for the next retry.
Extension Points
The following figure shows the scheduling context in the scheduling framework and the extension points within it. An extension can register multiple extension points so that it can perform more complex stateful tasks.
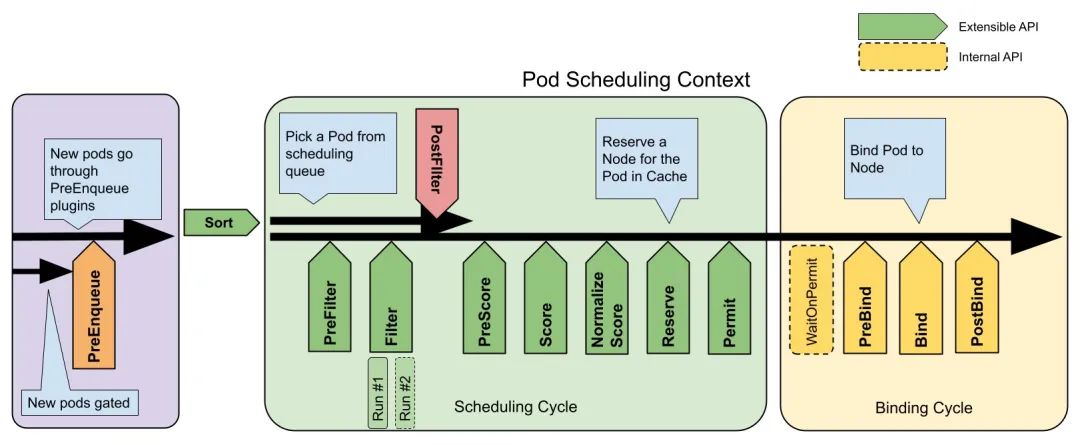
-
PreEnqueue This extension is called before adding a Pod to the internal active queue, where the Pod is marked as ready for scheduling. The Pod is only allowed into the active queue if all PreEnqueue plugins return Success. Otherwise, it is placed in the internal list of unschedulable Pods and does not appear unschedulable. (A .spec.schedulingGates field can be added to the Pod’s API to mark the Pod’s readiness for scheduling, and the Service Provider can change this field to signal to the scheduler when the Pod is ready for scheduling.)
-
The QueueSort extension is used to sort a Pod’s pending queue to determine which Pod to schedule first. The QueueSort extension essentially implements a single method Less(*QueuedPodInfo, *QueuedPodInfo) that compares two Pods and decides which one has priority to be scheduled, and there can only be one QueueSort plug-in in effect at a given point in time.
-
The Pre-filter extension is used to pre-process information about a Pod, or to check some preconditions that must be met by a cluster or Pod, and if pre-filter returns an error, the scheduling process terminates.
-
The Filter extension is used to exclude nodes that cannot run the Pod; for each node, the scheduler executes the filter extensions sequentially; if any of the filters mark the node as unselectable, the remaining filter extensions will not be executed. The scheduler can execute filter extensions on multiple nodes at the same time.
-
Post-filter is a notification-type extension point called with a list of nodes that have been filtered to optional nodes at the end of the filter phase, which can be used in the extension to update the internal state or to generate logs or metrics information.
-
The Scoring extension is used to score all optional nodes, the scheduler will call the Soring extension for each node and the scoring result will be a range of integers. In the normalise scoring phase, the scheduler will combine the scoring result of each scoring extension for a specific node with the weight of that extension as the final scoring result.
-
The Normalize scoring extension modifies the scoring results for each node before the scheduler performs the final ordering of the nodes. extensions registered to this extension point will get the scoring results of the scoring extension in the same plugin as an argument when they are called, and the scheduling framework will call one of the normalize scoring extensions in all the plugins once for every scheduling it performs.
-
Reserve is a notification extension point that can be used by stateful plugins to get the resources reserved for a Pod on a node. This event occurs before the scheduler binds the Pod to the node, and is intended to avoid a situation where the scheduler schedules a new Pod to a node while waiting for the Pod to bind to the node, and then actually uses more resources than are available (since binding a to a node occurs asynchronously). This is the last step of the scheduling process. After the Pod enters the reserved state, either the Unreserve extension is triggered when the binding fails, or the Post-bind extension ends the binding process when the binding succeeds.
-
The Permit extension is used to prevent or delay the binding of a Pod to a node.The Permit extension can do one of the following three things:
- approve: when all permit extensions have approved the binding of a Pod to a node, the scheduler will continue with the binding process
- deny: if any of the permit extensions denies a Pod’s binding to a node, the Pod is placed back in the pending queue, which triggers the
Unreserve extension
- wait: if a permit extension returns wait, the Pod will remain in the permit phase until approved by another extension, if a timeout event occurs and the wait state changes to deny, the Pod will be put back into the pending queue, which will trigger the Unreserve extension
-
The Pre-bind extension is used to perform certain logic before the Pod binds. For example, the pre-bind extension can mount a network-based data volume on a node so that it can be used by a Pod. If any of the pre-bind extensions return an error, the Pod is placed back in the pending queue and the Unreserve extension is triggered.
-
The Bind extension is used to bind a Pod to a node:
- The bind extension executes only if all pre-bind extensions have successfully executed
- The scheduling framework invokes bind extensions one by one in the order in which they are registered.
- A specific bind extension can choose to process or not process the Pod.
- If a bind extension handles the binding of the Pod to a node, the remaining bind extensions are ignored.
-
Post-bind is a notification extension:
- The Post-bind extension is called passively after a Pod is successfully bound to a node.
- The Post-bind extension is the last step in the binding process and can be used to perform resource cleanup actions.
-
The Unreserve is a notification extension that will be called if resources have been reserved for a Pod and the Pod is denied binding during the binding process.The unreserve extension should free compute resources on nodes that have been reserved for the Pod. Unreserve extensions should free compute resources on the nodes that have been reserved for the Pod. The reserve and unreserve extensions should appear in pairs in a plugin.
If we want to implement our own plugin, we must register the plugin with the scheduler framework and complete the configuration, and we must also implement the extension point interface, which we can find in the source code pkg/scheduler/framework/interface.go file, as shown below:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
160
161
162
163
164
165
166
167
168
169
170
171
172
173
174
175
176
177
178
179
180
181
182
183
184
185
186
187
188
189
190
191
192
193
194
195
196
197
198
199
200
201
202
203
204
205
206
207
208
209
|
// Plugin is the parent type for all the scheduling framework plugins.
type Plugin interface {
Name() string
}
// PreEnqueuePlugin is an interface that must be implemented by "PreEnqueue" plugins.
// These plugins are called prior to adding Pods to activeQ.
// Note: an preEnqueue plugin is expected to be lightweight and efficient, so it's not expected to
// involve expensive calls like accessing external endpoints; otherwise it'd block other
// Pods' enqueuing in event handlers.
type PreEnqueuePlugin interface {
Plugin
// PreEnqueue is called prior to adding Pods to activeQ.
PreEnqueue(ctx context.Context, p *v1.Pod) *Status
}
// LessFunc is the function to sort pod info
type LessFunc func(podInfo1, podInfo2 *QueuedPodInfo) bool
// QueueSortPlugin is an interface that must be implemented by "QueueSort" plugins.
// These plugins are used to sort pods in the scheduling queue. Only one queue sort
// plugin may be enabled at a time.
type QueueSortPlugin interface {
Plugin
// Less are used to sort pods in the scheduling queue.
Less(*QueuedPodInfo, *QueuedPodInfo) bool
}
// EnqueueExtensions is an optional interface that plugins can implement to efficiently
// move unschedulable Pods in internal scheduling queues. Plugins
// that fail pod scheduling (e.g., Filter plugins) are expected to implement this interface.
type EnqueueExtensions interface {
// EventsToRegister returns a series of possible events that may cause a Pod
// failed by this plugin schedulable.
// The events will be registered when instantiating the internal scheduling queue,
// and leveraged to build event handlers dynamically.
// Note: the returned list needs to be static (not depend on configuration parameters);
// otherwise it would lead to undefined behavior.
EventsToRegister() []ClusterEvent
}
// PreFilterExtensions is an interface that is included in plugins that allow specifying
// callbacks to make incremental updates to its supposedly pre-calculated
// state.
type PreFilterExtensions interface {
// AddPod is called by the framework while trying to evaluate the impact
// of adding podToAdd to the node while scheduling podToSchedule.
AddPod(ctx context.Context, state *CycleState, podToSchedule *v1.Pod, podInfoToAdd *PodInfo, nodeInfo *NodeInfo) *Status
// RemovePod is called by the framework while trying to evaluate the impact
// of removing podToRemove from the node while scheduling podToSchedule.
RemovePod(ctx context.Context, state *CycleState, podToSchedule *v1.Pod, podInfoToRemove *PodInfo, nodeInfo *NodeInfo) *Status
}
// PreFilterPlugin is an interface that must be implemented by "PreFilter" plugins.
// These plugins are called at the beginning of the scheduling cycle.
type PreFilterPlugin interface {
Plugin
// PreFilter is called at the beginning of the scheduling cycle. All PreFilter
// plugins must return success or the pod will be rejected. PreFilter could optionally
// return a PreFilterResult to influence which nodes to evaluate downstream. This is useful
// for cases where it is possible to determine the subset of nodes to process in O(1) time.
PreFilter(ctx context.Context, state *CycleState, p *v1.Pod) (*PreFilterResult, *Status)
// PreFilterExtensions returns a PreFilterExtensions interface if the plugin implements one,
// or nil if it does not. A Pre-filter plugin can provide extensions to incrementally
// modify its pre-processed info. The framework guarantees that the extensions
// AddPod/RemovePod will only be called after PreFilter, possibly on a cloned
// CycleState, and may call those functions more than once before calling
// Filter again on a specific node.
PreFilterExtensions() PreFilterExtensions
}
// FilterPlugin is an interface for Filter plugins. These plugins are called at the
// filter extension point for filtering out hosts that cannot run a pod.
// This concept used to be called 'predicate' in the original scheduler.
// These plugins should return "Success", "Unschedulable" or "Error" in Status.code.
// However, the scheduler accepts other valid codes as well.
// Anything other than "Success" will lead to exclusion of the given host from
// running the pod.
type FilterPlugin interface {
Plugin
// Filter is called by the scheduling framework.
// All FilterPlugins should return "Success" to declare that
// the given node fits the pod. If Filter doesn't return "Success",
// it will return "Unschedulable", "UnschedulableAndUnresolvable" or "Error".
// For the node being evaluated, Filter plugins should look at the passed
// nodeInfo reference for this particular node's information (e.g., pods
// considered to be running on the node) instead of looking it up in the
// NodeInfoSnapshot because we don't guarantee that they will be the same.
// For example, during preemption, we may pass a copy of the original
// nodeInfo object that has some pods removed from it to evaluate the
// possibility of preempting them to schedule the target pod.
Filter(ctx context.Context, state *CycleState, pod *v1.Pod, nodeInfo *NodeInfo) *Status
}
// PostFilterPlugin is an interface for "PostFilter" plugins. These plugins are called
// after a pod cannot be scheduled.
type PostFilterPlugin interface {
Plugin
// PostFilter is called by the scheduling framework.
// A PostFilter plugin should return one of the following statuses:
// - Unschedulable: the plugin gets executed successfully but the pod cannot be made schedulable.
// - Success: the plugin gets executed successfully and the pod can be made schedulable.
// - Error: the plugin aborts due to some internal error.
//
// Informational plugins should be configured ahead of other ones, and always return Unschedulable status.
// Optionally, a non-nil PostFilterResult may be returned along with a Success status. For example,
// a preemption plugin may choose to return nominatedNodeName, so that framework can reuse that to update the
// preemptor pod's .spec.status.nominatedNodeName field.
PostFilter(ctx context.Context, state *CycleState, pod *v1.Pod, filteredNodeStatusMap NodeToStatusMap) (*PostFilterResult, *Status)
}
// PreScorePlugin is an interface for "PreScore" plugin. PreScore is an
// informational extension point. Plugins will be called with a list of nodes
// that passed the filtering phase. A plugin may use this data to update internal
// state or to generate logs/metrics.
type PreScorePlugin interface {
Plugin
// PreScore is called by the scheduling framework after a list of nodes
// passed the filtering phase. All prescore plugins must return success or
// the pod will be rejected
PreScore(ctx context.Context, state *CycleState, pod *v1.Pod, nodes []*v1.Node) *Status
}
// ScoreExtensions is an interface for Score extended functionality.
type ScoreExtensions interface {
// NormalizeScore is called for all node scores produced by the same plugin's "Score"
// method. A successful run of NormalizeScore will update the scores list and return
// a success status.
NormalizeScore(ctx context.Context, state *CycleState, p *v1.Pod, scores NodeScoreList) *Status
}
// ScorePlugin is an interface that must be implemented by "Score" plugins to rank
// nodes that passed the filtering phase.
type ScorePlugin interface {
Plugin
// Score is called on each filtered node. It must return success and an integer
// indicating the rank of the node. All scoring plugins must return success or
// the pod will be rejected.
Score(ctx context.Context, state *CycleState, p *v1.Pod, nodeName string) (int64, *Status)
// ScoreExtensions returns a ScoreExtensions interface if it implements one, or nil if does not.
ScoreExtensions() ScoreExtensions
}
// ReservePlugin is an interface for plugins with Reserve and Unreserve
// methods. These are meant to update the state of the plugin. This concept
// used to be called 'assume' in the original scheduler. These plugins should
// return only Success or Error in Status.code. However, the scheduler accepts
// other valid codes as well. Anything other than Success will lead to
// rejection of the pod.
type ReservePlugin interface {
Plugin
// Reserve is called by the scheduling framework when the scheduler cache is
// updated. If this method returns a failed Status, the scheduler will call
// the Unreserve method for all enabled ReservePlugins.
Reserve(ctx context.Context, state *CycleState, p *v1.Pod, nodeName string) *Status
// Unreserve is called by the scheduling framework when a reserved pod was
// rejected, an error occurred during reservation of subsequent plugins, or
// in a later phase. The Unreserve method implementation must be idempotent
// and may be called by the scheduler even if the corresponding Reserve
// method for the same plugin was not called.
Unreserve(ctx context.Context, state *CycleState, p *v1.Pod, nodeName string)
}
// PreBindPlugin is an interface that must be implemented by "PreBind" plugins.
// These plugins are called before a pod being scheduled.
type PreBindPlugin interface {
Plugin
// PreBind is called before binding a pod. All prebind plugins must return
// success or the pod will be rejected and won't be sent for binding.
PreBind(ctx context.Context, state *CycleState, p *v1.Pod, nodeName string) *Status
}
// PostBindPlugin is an interface that must be implemented by "PostBind" plugins.
// These plugins are called after a pod is successfully bound to a node.
type PostBindPlugin interface {
Plugin
// PostBind is called after a pod is successfully bound. These plugins are
// informational. A common application of this extension point is for cleaning
// up. If a plugin needs to clean-up its state after a pod is scheduled and
// bound, PostBind is the extension point that it should register.
PostBind(ctx context.Context, state *CycleState, p *v1.Pod, nodeName string)
}
// PermitPlugin is an interface that must be implemented by "Permit" plugins.
// These plugins are called before a pod is bound to a node.
type PermitPlugin interface {
Plugin
// Permit is called before binding a pod (and before prebind plugins). Permit
// plugins are used to prevent or delay the binding of a Pod. A permit plugin
// must return success or wait with timeout duration, or the pod will be rejected.
// The pod will also be rejected if the wait timeout or the pod is rejected while
// waiting. Note that if the plugin returns "wait", the framework will wait only
// after running the remaining plugins given that no other plugin rejects the pod.
Permit(ctx context.Context, state *CycleState, p *v1.Pod, nodeName string) (*Status, time.Duration)
}
// BindPlugin is an interface that must be implemented by "Bind" plugins. Bind
// plugins are used to bind a pod to a Node.
type BindPlugin interface {
Plugin
// Bind plugins will not be called until all pre-bind plugins have completed. Each
// bind plugin is called in the configured order. A bind plugin may choose whether
// or not to handle the given Pod. If a bind plugin chooses to handle a Pod, the
// remaining bind plugins are skipped. When a bind plugin does not handle a pod,
// it must return Skip in its Status code. If a bind plugin returns an Error, the
// pod is rejected and will not be bound.
Bind(ctx context.Context, state *CycleState, p *v1.Pod, nodeName string) *Status
}
|
Enabling or disabling the scheduling framework plugins can be configured using the KubeSchedulerConfiguration resource object when the cluster is installed. The configuration in the following example enables one plugin that implements the reserve and preBind extension points, and disables another plugin, while providing some configuration information for the plugin foo:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
|
apiVersion: kubescheduler.config.k8s.io/v1
kind: KubeSchedulerConfiguration
---
plugins:
reserve:
enabled:
- name: foo
- name: bar
disabled:
- name: baz
preBind:
enabled:
- name: foo
disabled:
- name: baz
pluginConfig:
- name: foo
args: >
Any content that the foo plugin can parse
|
The order in which extensions are invoked is as follows:
- If no corresponding extension is configured for an extension point, the scheduling framework will use the extension in the default plugin
- If an extension is configured and activated for an extension point, the scheduling framework will call the extension of the default plugin first, then the extension in the configuration.
- The default plugin’s extensions are always called first, and then the extensions of the extension point are called in order of the extension’s activation
enabled in the KubeSchedulerConfiguration;
- The default plugin extension can be disabled and then activated somewhere in the
enabled list, which changes the order in which the default plugin extensions are called.
Assuming that the default plugin foo implements the reserve extension, and we want to add a plugin bar, which should be called before foo, we should disable foo first and then activate bar and foo in that order. An example configuration is shown below:
1
2
3
4
5
6
7
8
9
10
11
12
|
apiVersion: kubescheduler.config.k8s.io/v1
kind: KubeSchedulerConfiguration
---
profiles:
- plugins:
reserve:
enabled:
- name: bar
- name: foo
disabled:
- name: foo
|
In the source directory pkg/scheduler/framework/plugins/examples there are several demonstration plugins that we can refer to for their implementation.
Example
In fact, to implement a scheduling framework plug-in, it is not difficult, we just need to implement the corresponding extension point, and then register the plug-in to the scheduler, the following is the default scheduler in the initialisation of the plug-in registered:
1
2
3
4
5
6
7
8
9
10
11
12
|
// pkg/scheduler/algorithmprovider/registry.go
func NewRegistry() Registry {
return Registry{
// FactoryMap:
// New plugins are registered here.
// example:
// {
// stateful_plugin.Name: stateful.NewStatefulMultipointExample,
// fooplugin.Name: fooplugin.New,
// }
}
}
|
But you can see that the default does not register some plugins, so in order to make the scheduler can identify our plugin code, we need to implement a scheduler, of course, this scheduler we do not have to implement their own, directly call the default scheduler, and then in the above NewRegistry() function will be our plugin registration into the can be. The kubernetes/cmd/kube-scheduler/app/server.go source file for kube-scheduler has a NewSchedulerCommand entry with a list of arguments of type Option, which happens to be a plugin. ` happens to be the definition of a plugin configuration.
1
2
3
4
5
6
7
|
// Option configures a framework.Registry.
type Option func(framework.Registry) error
// NewSchedulerCommand creates a *cobra.Command object with default parameters and registryOptions
func NewSchedulerCommand(registryOptions ...Option) *cobra.Command {
......
}
|
So we can just call this function as our function entry and pass in our own plugin as an argument, and there’s also a function called WithPlugin underneath the file that creates an instance of Option:
1
2
3
4
5
|
func WithPlugin(name string, factory runtime.PluginFactory) Option {
return func(registry runtime.Registry) error {
return registry.Register(name, factory)
}
}
|
So we end up with the following entry function:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
|
package main
import (
"k8s.io/component-base/cli"
"k8s.io/kubernetes/cmd/kube-scheduler/app"
"math/rand"
"os"
// Ensure scheme package is initialized.
_ "simple-scheduler/pkg/scheduler/apis/config/schema"
"simple-scheduler/pkg/scheduler/framework/plugins"
"time"
)
func main() {
rand.Seed(time.Now().UTC().UnixNano())
command := app.NewSchedulerCommand(
app.WithPlugin(plugins.Name, plugins.New))
code := cli.Run(command)
os.Exit(code)
}
|
Where app.WithPlugin(sample.Name, sample.New) is the plugin we’re going to implement, and as you can see from the arguments to the WithPlugin function, our sample.New here has to be a value of type framework.PluginFactory. The definition of PluginFactory is a function:
1
|
type PluginFactory = func(configuration runtime.Object, f framework.Handle) (framework.Plugin, error)
|
So sample.New is actually the above function, in this function we can get to the plug-in some of the data and then logical processing can be, plug-in implementation is shown below, we simply get the data here to print the log, if you have the actual needs of the data you can get on the line according to the processing of the data can be. We have just achieved here PreFilter, Filter, PreBind three extensions, the other can be extended in the same way.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
|
package plugins
import (
"context"
"fmt"
v1 "k8s.io/api/core/v1"
"k8s.io/apimachinery/pkg/runtime"
"k8s.io/klog/v2"
"k8s.io/kubernetes/pkg/scheduler/framework"
"simple-scheduler/pkg/scheduler/apis/config"
"simple-scheduler/pkg/scheduler/apis/config/validation"
)
const Name = "sample-plugin"
type Sample struct {
args *config.SampleArgs
handle framework.Handle
}
func (s *Sample) Name() string {
return Name
}
func (s *Sample) PreFilter(ctx context.Context, cycleState *framework.CycleState, pod *v1.Pod) (*framework.PreFilterResult, *framework.Status) {
klog.V(3).Infof("prefilter pod: %v", pod.Name)
return nil, nil
}
func (s *Sample) Filter(ctx context.Context, cycleState *framework.CycleState, pod *v1.Pod, nodeInfo *framework.NodeInfo) *framework.Status {
klog.V(3).Infof("filter pod: %v, node: %v", pod.Name, nodeInfo.Node().Name)
return framework.NewStatus(framework.Success, "")
}
func (s *Sample) PreBind(ctx context.Context, state *framework.CycleState, pod *v1.Pod, nodeName string) *framework.Status {
if nodeInfo, err := s.handle.SnapshotSharedLister().NodeInfos().Get(nodeName); err != nil {
return framework.NewStatus(framework.Error, fmt.Sprintf("prebind get node: %s info error: %s", nodeName, err.Error()))
} else {
klog.V(3).Infof("prebind node info: %+v", nodeInfo.Node())
return framework.NewStatus(framework.Success, "")
}
}
func New(fpArgs runtime.Object, fh framework.Handle) (framework.Plugin, error) {
args, ok := fpArgs.(*config.SampleArgs)
if !ok {
return nil, fmt.Errorf("got args of type %T, want *SampleArgs", fpArgs)
}
if err := validation.ValidateSamplePluginArgs(*args); err != nil {
return nil, err
}
return &Sample{
args: args,
handle: fh,
}, nil
}
|
The full code is available at https://github.com/cnych/sample-scheduler-framework.
A parameter for the scheduler plugin is also defined here:
1
2
3
4
5
6
7
8
|
// +k8s:deepcopy-gen:interfaces=k8s.io/apimachinery/pkg/runtime.Object
type SampleArgs struct {
metav1.TypeMeta
FavoriteColor string `json:"favorite_color,omitempty"`
FavoriteNumber int `json:"favorite_number,omitempty"`
ThanksTo string `json:"thanks_to,omitempty"`
}
|
In the old version, the frameworkDecodeInto function was provided to directly convert the parameters we passed in, but in the new version, it must be a runtime.Object object, so we must implement the corresponding deep-copy method, so we add the +k8s:deepcopy-gen:interfaces=k8s.io/apimachinery/pkg/runtime.Object annotation on the top of the structure, and then the corresponding deep-copy method can be automatically generated by the hack/update-gen.sh script provided in the Kubernetes source code.
In the file register.go we need to add SampleArgs to the call to the AddKnownTypes function. also note that in the main.go file we import the schema defined here, which uses all the configuration initialisation schemes/configuration files we introduced in pkg/apis.
Once the implementation is complete, we can compile and package it into an image, and then we can deploy it as a normal application with a Deployment controller. Since we need to fetch some resource objects in the cluster, we need to apply for RBAC permissions, and then we can configure our scheduler with the --config parameter, again using a KubeSchedulerConfiguration resource object configuration, you can use plugins to enable or disable our implementation of the plugin, you can also use pluginConfig to pass some parameter values to the plugin:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
160
161
162
163
164
165
166
167
168
169
170
171
172
173
174
175
176
177
178
179
180
181
182
183
184
185
186
187
188
189
190
191
192
193
194
195
196
197
198
199
200
201
202
203
204
205
206
207
208
209
210
211
|
# sample-scheduler.yaml
kind: ClusterRole
apiVersion: rbac.authorization.k8s.io/v1
metadata:
name: sample-scheduler-clusterrole
rules:
- apiGroups:
- ""
resources:
- endpoints
- events
verbs:
- create
- get
- update
- apiGroups:
- ""
resources:
- nodes
verbs:
- get
- list
- watch
- apiGroups:
- ""
resources:
- pods
verbs:
- delete
- get
- list
- watch
- update
- apiGroups:
- ""
resources:
- bindings
- pods/binding
verbs:
- create
- apiGroups:
- ""
resources:
- pods/status
verbs:
- patch
- update
- apiGroups:
- ""
resources:
- replicationcontrollers
- services
verbs:
- get
- list
- watch
- apiGroups:
- apps
- extensions
resources:
- replicasets
verbs:
- get
- list
- watch
- apiGroups:
- apps
resources:
- statefulsets
verbs:
- get
- list
- watch
- apiGroups:
- policy
resources:
- poddisruptionbudgets
verbs:
- get
- list
- watch
- apiGroups:
- ""
resources:
- persistentvolumeclaims
- persistentvolumes
verbs:
- get
- list
- watch
- apiGroups:
- ""
resources:
- configmaps
verbs:
- get
- list
- watch
- apiGroups:
- "storage.k8s.io"
resources:
- storageclasses
- csinodes
verbs:
- get
- list
- watch
- apiGroups:
- "coordination.k8s.io"
resources:
- leases
verbs:
- create
- get
- list
- update
- apiGroups:
- "events.k8s.io"
resources:
- events
verbs:
- create
- patch
- update
---
apiVersion: v1
kind: ServiceAccount
metadata:
name: sample-scheduler-sa
namespace: kube-system
---
kind: ClusterRoleBinding
apiVersion: rbac.authorization.k8s.io/v1
metadata:
name: sample-scheduler-clusterrolebinding
namespace: kube-system
roleRef:
apiGroup: rbac.authorization.k8s.io
kind: ClusterRole
name: sample-scheduler-clusterrole
subjects:
- kind: ServiceAccount
name: sample-scheduler-sa
namespace: kube-system
---
apiVersion: v1
kind: ConfigMap
metadata:
name: scheduler-config
namespace: kube-system
data:
scheduler-config.yaml: |
apiVersion: kubescheduler.config.k8s.io/v1
kind: KubeSchedulerConfiguration
leaderElection:
leaderElect: true
leaseDuration: 15s
renewDeadline: 10s
resourceLock: endpointsleases
resourceName: sample-scheduler
resourceNamespace: kube-system
retryPeriod: 2s
profiles:
- schedulerName: sample-scheduler
plugins:
preFilter:
enabled:
- name: "sample-plugin"
filter:
enabled:
- name: "sample-plugin"
pluginConfig:
- name: sample-plugin
args: # runtime.Object
favorColor: "#326CE5"
favorNumber: 7
thanksTo: "Kubernetes"
---
apiVersion: apps/v1
kind: Deployment
metadata:
name: sample-scheduler
namespace: kube-system
labels:
component: sample-scheduler
spec:
selector:
matchLabels:
component: sample-scheduler
template:
metadata:
labels:
component: sample-scheduler
spec:
serviceAccountName: sample-scheduler-sa
priorityClassName: system-cluster-critical
volumes:
- name: scheduler-config
configMap:
name: scheduler-config
containers:
- name: scheduler
image: cnych/sample-scheduler:v0.26.4
imagePullPolicy: IfNotPresent
command:
- sample-scheduler
- --config=/etc/kubernetes/scheduler-config.yaml
- --v=3
volumeMounts:
- name: scheduler-config
mountPath: /etc/kubernetes
|
Deploying the above resource object directly, we have deployed a scheduler called sample-scheduler, and we can now deploy an application to use this scheduler for scheduling.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
|
# test-scheduler.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: test-scheduler
spec:
selector:
matchLabels:
app: test-scheduler
template:
metadata:
labels:
app: test-scheduler
spec:
schedulerName: sample-scheduler # Specify the scheduler to use, not the default default-scheduler.
containers:
- image: nginx:1.7.9
imagePullPolicy: IfNotPresent
name: nginx
ports:
- containerPort: 80
|
One thing to note here is that we have now manually specified a schedulerName field, setting it to the name of our custom scheduler sample-scheduler above.
Let’s create this resource object directly and view the logging information for our custom scheduler once it’s created.
1
2
3
4
5
6
7
8
9
10
11
12
13
|
➜ kubectl get pods -n kube-system -l component=sample-scheduler
NAME READY STATUS RESTARTS AGE
sample-scheduler-896658cd7-k7vcl 1/1 Running 0 57s
➜ kubectl logs -f sample-scheduler-896658cd7-k7vcl -n kube-system
I0114 09:14:18.878613 1 eventhandlers.go:173] add event for unscheduled pod default/test-scheduler-6486fd49fc-zjhcx
I0114 09:14:18.878670 1 scheduler.go:464] Attempting to schedule pod: default/test-scheduler-6486fd49fc-zjhcx
I0114 09:14:18.878706 1 sample.go:77] "Start PreFilter Pod" pod="test-scheduler-6486fd49fc-zjhcx"
I0114 09:14:18.878802 1 sample.go:93] "Start Filter Pod" pod="test-scheduler-6486fd49fc-zjhcx" node="node2" preFilterState=&{Resource:{MilliCPU:0 Memory:0 EphemeralStorage:0 AllowedPodNumber:0 ScalarResources:map[]}}
I0114 09:14:18.878835 1 sample.go:93] "Start Filter Pod" pod="test-scheduler-6486fd49fc-zjhcx" node="node1" preFilterState=&{Resource:{MilliCPU:0 Memory:0 EphemeralStorage:0 AllowedPodNumber:0 ScalarResources:map[]}}
I0114 09:14:18.879043 1 default_binder.go:51] Attempting to bind default/test-scheduler-6486fd49fc-zjhcx to node1
I0114 09:14:18.886360 1 scheduler.go:609] "Successfully bound pod to node" pod="default/test-scheduler-6486fd49fc-zjhcx" node="node1" evaluatedNodes=3 feasibleNodes=2
I0114 09:14:18.887426 1 eventhandlers.go:205] delete event for unscheduled pod default/test-scheduler-6486fd49fc-zjhcx
I0114 09:14:18.887475 1 eventhandlers.go:225] add event for scheduled pod default/test-scheduler-6486fd49fc-zjhcx
|
You can see that after we created the Pod, the corresponding logs appeared in our custom scheduler, and the corresponding logs appeared on top of the extension points we defined, proving that our example was successful, which can also be verified by looking at the schedulerName of the Pod.
1
2
3
4
5
6
7
8
9
10
|
➜ kubectl get pods
NAME READY STATUS RESTARTS AGE
test-scheduler-6486fd49fc-zjhcx 1/1 Running 0 35s
➜ kubectl get pod test-scheduler-6486fd49fc-zjhcx -o yaml
......
restartPolicy: Always
schedulerName: sample-scheduler
securityContext: {}
serviceAccount: default
......
|
Starting with Kubernetes v1.17, the Scheduler Framework’s built-in preselection and preference functions have all been plugged in, so to extend the scheduler we should get to know and understand the Scheduler Framework.