In fact, Kubernetes officially provides client-side libraries in various languages, but due to the inherent advantage of golang in the cloud-native domain, client-go is relatively the most used library. However, it is difficult to explain client-go clearly in one article, so it is impossible to cover all the details in this article, and we will try to describe the main framework clearly and explore the common interfaces and usage of client-go with code snippets.
client-go main framework
In fact, to understand the main functional modules of client-go and the functionality of each module, the Kubernetes API design philosophy is the foundation, especially for Kubernetes API grouping and versioning.
Let’s take a look at the main structure of the client-go code, and I’ll give you a sense of the core functionality of each major section.
1
2
3
4
5
6
7
8
9
10
11
12
|
$ tree -L 2 client-go
client-go
├── discovery # Contains dicoveryClient for discovering GVRs supported by k8s (Group/Version,/Resource), which is used by the 'kubectl api-resources' command to list the various resources in the cluster.
├── dynamic # Includes dynamicClient, which encapsulates the RESTClient and can dynamically specify the GVR of api resources, combined with unstructured.Unstructured types to access various types of k8s resources (e.g. Pod, Deploy...) Unstructured can also access user-defined resources (CRD).
├── informers # In order to reduce the client's frequent access to the apiserver, the informer is needed to cache the resources in the apiserver and receive notifications only when the api resource object changes. Each kind of api resource will have its own informer implementation, which is also differentiated by api grouping and version.
├── kubernetes # The main definition is ClientSet, which also wraps restClient and contains methods for managing various k8s resources and versions. Each api resource has a separate client, while ClientSet is a collection of multiple clients. clientSet and all requests from the clients of each k8s built-in resource are ultimately made by restClient; the typed directory includes client implementations for each specific k8s built-in resource, also grouped by api and version to distinguish.
│ ├── clientset.go
│ └── typed
├── listers # Read-only client containing various k8s built-in resources. Each lister has Get() and List() methods, and the results are read from the cache.
├── rest # Contains a client that actually sends requests to the apiserver, implements the Restful API, and supports both Protobuf and JSON format data.
├── scale # Mainly contains scalClient for Deploy, RS, etc. expansion/contraction.
├── tools # Various types of toolkits, common ones such as methods to get kubeconfig to SharedInformer, Reflector, DealtFIFO and Indexer, etc. These tools are mainly used to implement client query and caching mechanisms, reduce the load on apiserver, etc.
|
Note: For simplicity, unimportant files and directories are not listed.
In summary, the main functional modules of client-go and the dependencies of each module are roughly as shown in the following diagram.
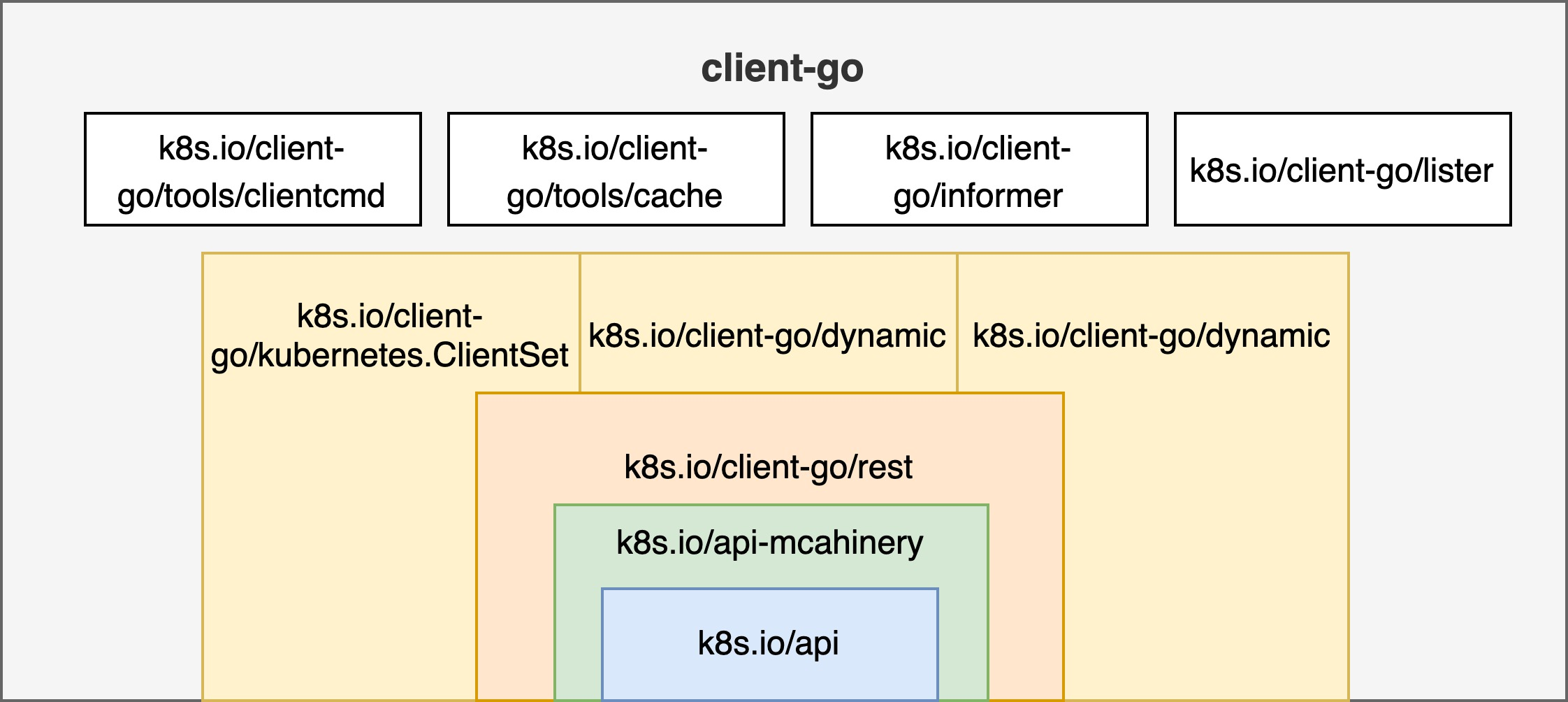
As you can see, restClient is encapsulated in ClientSet, DynamicClient, and DiscoveryClient, which means that the final request is sent to kube-apiserver by restClient. The grouping and versioning of API resources in k8s.io/api-machinery is the basis for all types of clients, and the definition of each API resource is included in the k8s.io/api module.
ClientSet
The ClientSet is a collection of statically typed clients for various API resources that use pre-generated API objects to interact with the kube-apiserver This is an RPC-like experience, with the benefit that typed clients use program compilation to enforce data security and some validation, but it also introduces the problem of strong coupling between version and type.
1
2
3
4
5
6
|
type Clientset struct {
*authenticationv1beta1.AuthenticationV1beta1Client
*authorizationv1.AuthorizationV1Client
// ...
*corev1.CoreV1Client
}
|
A typical example of using a statically typed client is as follows.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
|
import (
//...
"k8s.io/client-go/kubernetes"
"k8s.io/client-go/rest"
"k8s.io/client-go/tools/clientcmd"
)
func main() {
kubeconfig := filepath.Join(
os.Getenv("HOME"), ".kube", "config",
)
config, err := clientcmd.BuildConfigFromFlags("", kubeconfig)
// use the following one if running in cluster
// config, err := rest.InClusterConfig()
if err != nil {
log.Fatal(err)
}
// create the typed ClientSet
clientset, err := kubernetes.NewForConfig(config)
if err != nil {
log.Fatal(err)
}
// get the typed client for resources in CoreV1
coreV1Client := clientset.CoreV1()
// setup list options
listOptions := metav1.ListOptions{
LabelSelector: label,
FieldSelector: field,
}
// list PVCs with typed client
pvcs, err := coreV1Client.PersistentVolumeClaims(ns).List(listOptions)
if err != nil {
log.Fatal(err)
}
printPVCs(pvcs)
}
|
In almost all cases, except for Server Side Apply(SSA), we should give preference to statically typed clients over dynamic clients. We will have a chance to discuss SSA later.
DynamicClient
DynamicClient, which is the dynamic client, does not use the Go structures of the various API resources defined in k8s.io/api, but uses unstructured.Unstructured to represent all resource objects. unstructured The .Unstructured type uses a nested map[string]inferface{} value to represent the internal structure of the API resource, which is very similar to the server-side REST payload.
Dynamic clients defer all data binding to runtime, which means that programs using dynamic clients will perform type validation before the program runs. This can be a problem for some applications that require strong data type checking and validation. The attendant benefit is that loose coupling means that programs using dynamic clients do not need to recompile when client API resource objects change. Client programs have more flexibility in handling API surface updates without having to know in advance what those changes are.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
|
import (
//...
"k8s.io/apimachinery/pkg/apis/meta/v1/unstructured"
"k8s.io/apimachinery/pkg/runtime/schema"
"k8s.io/client-go/dynamic"
)
func main() {
kubeconfig := filepath.Join(
os.Getenv("HOME"), ".kube", "config",
)
config, err := clientcmd.BuildConfigFromFlags("", kubeconfig)
// use the following one if running in cluster
// config, err := rest.InClusterConfig()
if err != nil {
log.Fatal(err)
}
// create the dynamic client
dymClient, _ := dynamic.NewForConfig(config)
podGVR := schema.GroupVersionResource{Group: "core", Version: "v1", Resource: "pods"}
// api resource object with type unstructured.Unstructured, also can be unmarshaled from JSON/YAML
pod := &unstructured.Unstructured{
Object: map[string]interface{}{
"apiVersion": "v1",
"kind": "Pod",
"metadata": map[string]interface{}{
"name": "web",
},
"spec": map[string]interface{}{
"serviceAccount": "default",
...
}
}
}
// create the resource with dynamic client
dymClient.Resource(podGVR).Namespace(namespace).Create(context.TODO(), pod, metav1.CreateOptions{})
}
|
In addition, it is very easy to implement Server Side Apply (SSA) using dynamic clients, interested readers can take a look at this article.
DiscoveryClient
While the static and dynamic clients described above are both oriented towards resource objects, such as creating Pods, viewing PVCs, etc., DiscoveryClient is focused on discovering resources, such as viewing what resources are currently registered in the cluster and the version information of each resource. DiscoveryClient also encapsulates restClient and uses it to actually interact with the kube-apiserver.
The usage is basically similar to static and dynamic clients, so let’s look at an example of using DiscoveryClient.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
|
package main
import (
// ...
"k8s.io/client-go/discovery"
"k8s.io/client-go/tools/clientcmd"
)
func main() {
kubeconfig := filepath.Join(
os.Getenv("HOME"), ".kube", "config",
)
config, err := clientcmd.BuildConfigFromFlags("", kubeconfig)
// use the following one if running in cluster
// config, err := rest.InClusterConfig()
if err != nil {
log.Fatal(err)
}
// create dynamic client from config
dc, err := discovery.NewDiscoveryClientForConfig(config)
if err != nil {
log.Fatal(err)
}
// get all the api groups
apiGroup, apiResourceList, err := discoveryClient.ServerGroupsAndResources()
if err != nil {
log.Fatal(err)
}
log.Printf("APIGroup :\n %v\n\n\n", apiGroup)
// apiResourceList is slice that contains item of GVR
for _, apiRes := range apiResourceList {
// GroupVersion is string of 'G/V'
gvStr := apiRes.GroupVersion
gv, err := schema.ParseGroupVersion(gvStr)
if err != nil {
log.Fatal(err)
}
log.Printf("GroupVersion: %v\n", gvStr)
// APIResources contains all the reosurces in current GroupVersion
for _, res := range apiRes.APIResources {
log.Printf("%v\n", res.Name)
}
}
}
|
It should be noted that the kubectl api-resources command uses DiscoveryClient to discover resources in the cluster and group version information.
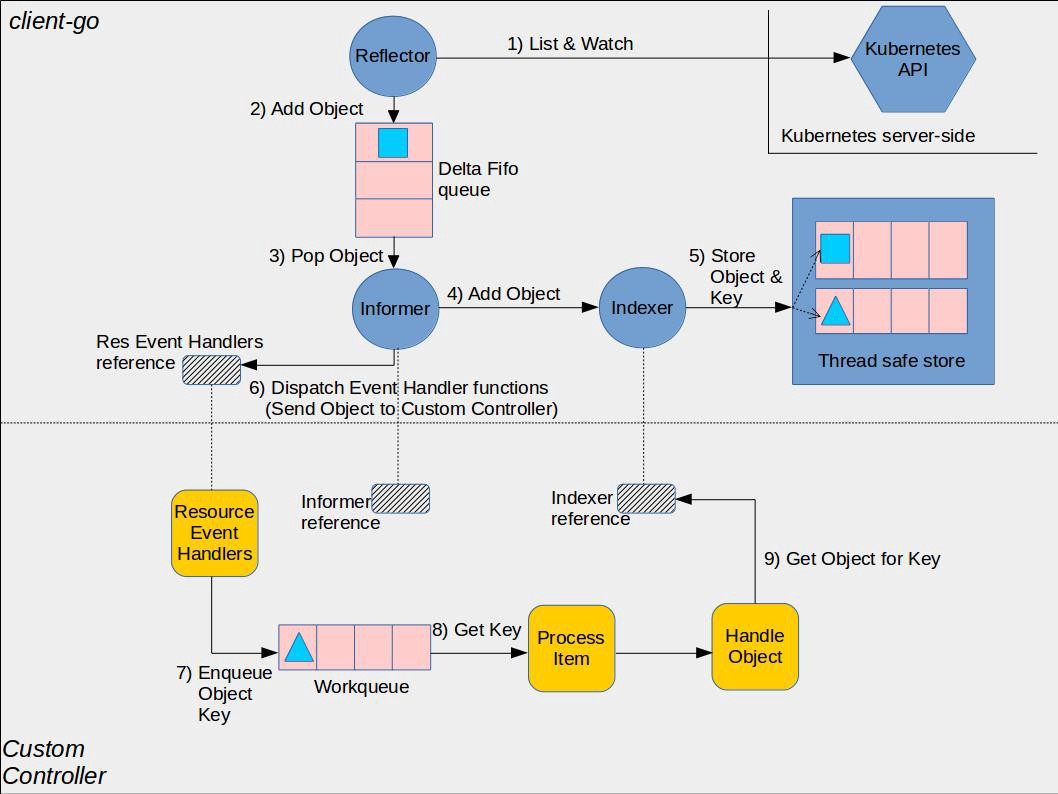
The Informer is important for implementing the controller model of kubernetes. We know that the main mode of operation of the controller is to look at the current state of the resources in the cluster and compare the expected state of the resources, and if they are not the same, to execute a number of commands to make the two states consistent. But the problem is that retrieving the current state of resources from the kube-apiserver is a very resource-intensive operation. If there is a caching mechanism that allows the controller to be notified only when the state of a resource changes, then the controller can execute instructions to reduce the load on the kube-apisever. This mechanism is the core functionality provided by the informer in client-go. In fact, the informer fetches all objects from the kube-apisever when it is initialized, and then only receives data pushed by the kube-apisever through the watch mechanism, instead of actively pulling data and using the data in the local cache to reduce the pressure on the kube-apisever.
Creating an informer is simple.
1
2
3
4
5
|
store, controller := cache.NewInformer {
&cache.ListWatch{},
&v1.Pod{},
resyncPeriod, // how often the controller goes through all items remaining in the cache and fires the UpdateFunc again
cache.ResourceEventHandlerFuncs{},
|
As you can see, the first parameter to create informer is a ListWatch interface type, which needs to know how to list/watch resources, the simplest ListWatch is as follows.
1
2
3
4
5
|
lw := cache.NewListWatchFromClient(
client,
&v1.Pod{},
api.NamespaceAll,
fieldSelector)
|
Of course, it is not complicated to create your own ListWatch, the main thing is to know how to list/watch resources.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
|
cache.ListWatch {
listFunc := func(options metav1.ListOptions) (runtime.Object, error) {
return client.Get().
Namespace(namespace).
Resource(resource).
VersionedParams(&options, metav1.ParameterCodec).
FieldsSelectorParam(fieldSelector).
Do().
Get()
}
watchFunc := func(options metav1.ListOptions) (watch.Interface, error) {
options.Watch = true
return client.Get().
Namespace(namespace).
Resource(resource).
VersionedParams(&options, metav1.ParameterCodec).
FieldsSelectorParam(fieldSelector).
Watch()
}
}
|
As you can see, the last parameter to create an Informer is a callback function ResourceEventHandlerFuncs, which knows how to handle events when a resource object changes. Specifically, it must contain AddFunc, UpdateFunc and DeleteFunc.
1
2
3
4
5
|
type ResourceEventHandlerFuncs struct {
AddFunc func(obj interface{})
UpdateFunc func(oldObj, newObj interface{})
DeleteFunc func(obj interface{})
}
|
In fact, Informer is rarely used, more often than SharedInformer, but understanding Informer is useful for developing controller.
Informer creates a number of columns of cache, which is bad when there are multiple controllers in an application creating Informers that access resources at the same time, and the caches of Informers created by different controllers overlap, leading to an unnecessary increase in resource consumption. The good thing is that there is SharedInformer, which maintains a cache of informer requirements for multiple controllers, in addition to the SharedInformer also maintains only one watch for the upstream server, regardless of the number of downstream consumers. This is common in kube-controller-manager.
1
2
|
lw := cache.NewListWatchFromClient(…)
sharedInformer := cache.NewSharedInformer(lw, &api.Pod{}, resyncPeriod)
|
Workqueue
The ShareInformer explained above has a problem, it has no way to track the status of each controller, so the controller must provide its own queue and retry mechanism. client-go provides workqueue to implement this feature. SharedInformer only needs to put the resource change events watched into the workqueue, and the controller as a consumer will retrieve the events from it to process.
Initialize a rate-limited workqueue.
1
|
queue := workqueue.NewRateLimitingQueue(workqueue.DefaultControllerRateLimiter())
|
When should a controller worker start fetching events from the workqueue to work on? The best practice is shown below.
1
2
3
4
5
6
7
8
9
10
11
12
|
controller.informer = cache.NewSharedInformer(...)
controller.queue = workqueue.NewRateLimitingQueue(workqueue.DefaultControllerRateLimiter())
controller.informer.Run(stopCh)
if !cache.WaitForCacheSync(stopCh, controller.HasSynched)
{
log.Errorf("Timed out waiting for caches to sync"))
}
// Now start processing
controller.runWorker()
|
Full Example
Let’s look at a complete example of a controller using SharedInformer with workqueue.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
|
import (
"k8s.io/apimachinery/pkg/runtime"
"k8s.io/apimachinery/pkg/watch"
"k8s.io/apimachinery/pkg/util/wait"
utilruntime "k8s.io/apimachinery/pkg/util/runtime"
corev1 "k8s.io/api/core/v1"
metav1 "k8s.io/apimachinery/pkg/apis/meta/v1"
"k8s.io/client-go/tools/cache"
"k8s.io/client-go/util/workqueue"
"k8s.io/client-go/kubernetes"
)
// Controller
type Controller struct {
clientset kubernetes.Interface
queue workqueue.RateLimitingInterface
informer cache.SharedIndexInformer
eventHandler handlers.Handler
}
func Start(kubeClient kubernetes.Interface, conf *config.Config, eventHandler handlers.Handler) {
c := newController(kubeClient, eventHandler)
stopCh := make(chan struct{})
defer close(stopCh)
go c.Run(stopCh) // start the controller
sigterm := make(chan os.Signal, 1)
signal.Notify(sigterm, syscall.SIGTERM)
signal.Notify(sigterm, syscall.SIGINT)
<-sigterm // wait for system term signal
}
// newController creates the controller
func newController(client kubernetes.Interface, eventHandler handlers.Handler) *Controller {
queue := workqueue.NewRateLimitingQueue(workqueue.DefaultControllerRateLimiter())
informer := cache.NewSharedIndexInformer(
&cache.ListWatch{
ListFunc: func(options metav1.ListOptions) (runtime.Object, error) {
return client.CoreV1().Pods(metav1.NamespaceAll).List(options)
},
WatchFunc: func(options metav1.ListOptions) (watch.Interface, error) {
return client.CoreV1().Pods(metav1.NamespaceAll).Watch(options)
},
},
&corev1.Pod{},
0, // no resync
cache.Indexers{},
)
informer.AddEventHandler(cache.ResourceEventHandlerFuncs{
AddFunc: func(obj interface{}) {
key, err := cache.MetaNamespaceKeyFunc(obj)
if err == nil {
queue.Add(key)
}
},
UpdateFunc: func(old, new interface{}) {
key, err := cache.MetaNamespaceKeyFunc(new)
if err == nil {
queue.Add(key)
}
},
DeleteFunc: func(obj interface{}) {
key, err := cache.DeletionHandlingMetaNamespaceKeyFunc(obj)
if err == nil {
queue.Add(key)
}
},
})
return &Controller{
clientset: client,
informer: informer,
queue: queue,
eventHandler: eventHandler,
}
}
// Run starts the controller
func (c *Controller) Run(stopCh <-chan struct{}) {
defer utilruntime.HandleCrash()
defer c.queue.ShutDown()
go c.informer.Run(stopCh)
if !cache.WaitForCacheSync(stopCh, c.HasSynced) {
utilruntime.HandleError(fmt.Errorf("Timed out waiting for caches to sync"))
return
}
// runWorker will loop until "something bad" happens. The .Until will then rekick the worker after one second
wait.Until(c.runWorker, time.Second, stopCh)
}
// HasSynced is required for the cache.Controller interface.
func (c *Controller) HasSynced() bool {
return c.informer.HasSynced()
}
// LastSyncResourceVersion is required for the cache.Controller interface.
func (c *Controller) LastSyncResourceVersion() string {
return c.informer.LastSyncResourceVersion()
}
func (c *Controller) runWorker() {
// processNextWorkItem will automatically wait until there's work available
for c.processNextItem() {
// continue looping
}
}
// processNextWorkItem deals with one key off the queue. It returns false when it's time to quit.
func (c *Controller) processNextItem() bool {
key, quit := c.queue.Get()
if quit {
return false
}
defer c.queue.Done(key)
err := c.processItem(key.(string))
if err == nil {
// No error, reset the ratelimit counters
c.queue.Forget(key)
} else if c.queue.NumRequeues(key) < maxRetries {
// err != nil and retry
c.queue.AddRateLimited(key)
} else {
// err != nil and too many retries
c.queue.Forget(key)
utilruntime.HandleError(err)
}
return true
}
// processItem processs change of object
func (c *Controller) processItem(key string) error {
obj, exists, err := c.informer.GetIndexer().GetByKey(key)
if err != nil {
return fmt.Errorf("Error fetching object with key %s from store: %v", key, err)
}
if !exists {
c.eventHandler.ObjectDeleted(obj)
return nil
}
c.eventHandler.ObjectCreated(obj)
return nil
}
|
Finally, let’s take a look at the classic illustration of the controller pattern.