BoltDB is an embedded K/V database implemented in Go language with the goal of providing a simple, fast and reliable embedded database for projects that do not require full database services such as Postgres or MySQL. boltDB has been implemented as the underlying database in projects such as etcd, Bitcoin, etc. This article provides a brief analysis of the design principles of BoltDB.
BoltDB is currently archived by the original author, so the version analyzed in this article is the one maintained by etcd: etcd-io/bbolt .
BoltDB is mainly designed from LMDB, supports ACID transaction, lock-free concurrent transaction MVCC, provides B+Tree index, BoltDB uses a single file as persistent storage, uses mmap to map the file into memory, and divides the file into equal size Page to store data, and uses copy-on-write technique to write dirty pages to the file.
MMAP
The Memory-Mapped File (mmap) technique maps a file into the virtual memory of the calling process and accesses the contents of the mapped file by manipulating the corresponding memory area. The mmap() system call function is typically used when frequent reads and writes to a file are required, replacing I/O reads and writes with memory reads and writes to achieve higher performance.
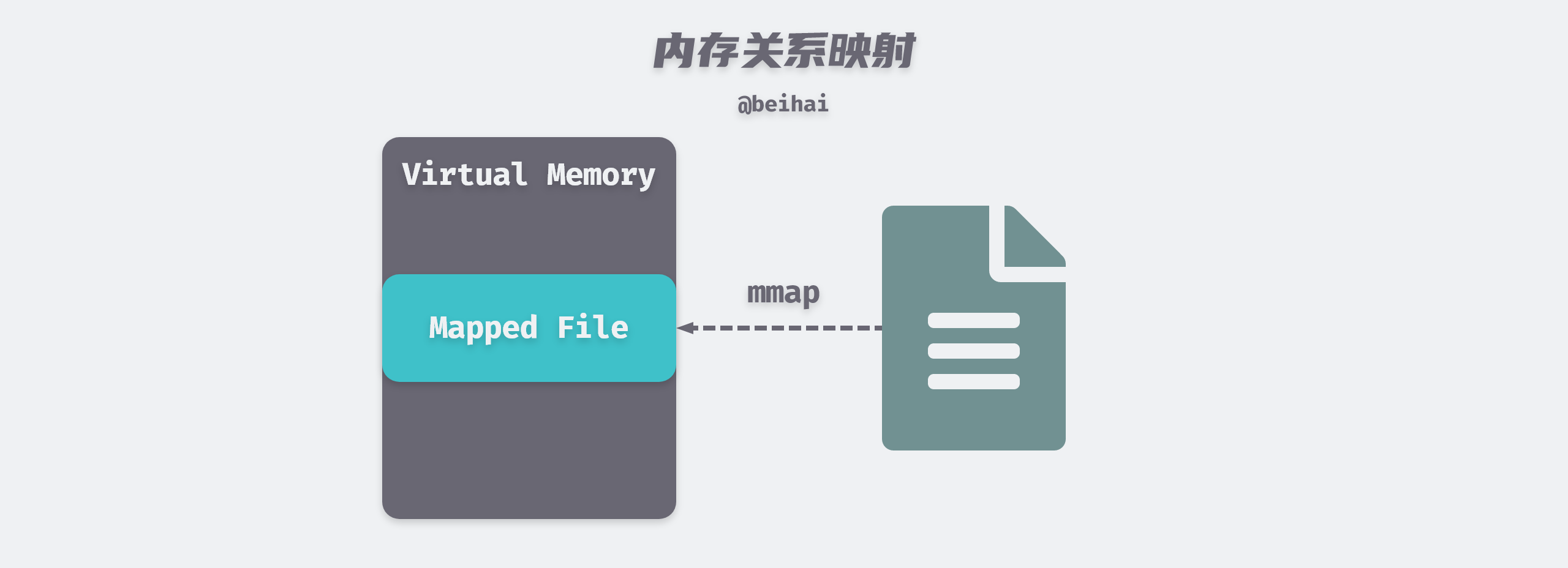
Traditional UNIX or Linux systems have multiple buffers in the kernel. When we call the read() system call to read data from a file, the kernel usually copies that data to a buffer first, and then copies the data to the process memory space.
When using mmap, the kernel creates a memory map area in the virtual address space of the calling process, and the application process can access this memory directly to get data, saving the overhead of copying data from kernel space to user process space. mmap does not actually copy the contents of the file to memory in real time, but rather copies the file data to memory only when a page-out interrupt is triggered during the read process.
Paging is a common memory management technique used in modern operating systems to divide the virtual memory space into equally sized Pages, which are usually 4KB in size, and in UNIX-like systems, we can use the following command to get the page size.
Therefore, in order to reduce the number of random I/Os, the data files in BoltDB are also divided by 4KB size. However, in the process of use, frequent reading and writing data will still cause too many random I/Os and affect the performance.
Writing to files in BoltDB does not use the
mmaptechnique, but writes data to files directly through two system callsWrite()andfdatasync().
Data Structure
BoltDB’s data file is organized into multiple Pages. When the database is initialized, 4 Pages are pre-allocated, page 0 and page 1 are initialized as meta pages, page 2 is initialized as a freelist page, and page 3 is initialized as an empty leafPage for writing key-value pairs data. While these types of Pages are described below, we first analyze the data structure of the page.
Page
Each Page has a fixed size Header area, which is used to mark the id, page type and other information of the page. Since BoltDB uses B+Tree indexing, in addition to leafPage which holds data, there will be branchPage which is used as data index.
|
|
In older implementations there was an extra
ptrfield pointing to the data storage address, but in Go 1.14 it did not pass the pointer safety check, so this field has been removed, for details see: PR#201 Fix unsafe pointer conversions caught by Go 1.14 checkptr
BoltDB assigns a unique identifier id to each page and looks up the corresponding page by its id. The pageHeader is followed by a concrete data storage structure. Each key-value pair is represented by an Element structure, and the address of the key-value pair is obtained by a pointer operation using the offset pos: &Element + pos == &key.
|
|
The above two different Element structures are used in different types of page, if it is used for data indexing branchPage, only the size field ksize of the key and the pgid of the next level page will be stored in a branchPageElement for data indexing.
The leafPageElement is used to store real key-value pair data, so the vsize field is added to quickly get the key-value pair information for queries. The meaning of the flags field will be described in the Bucket section.
The memory layout of branchPage and leafPage can be derived from the analysis of Element as shown in the following figure.
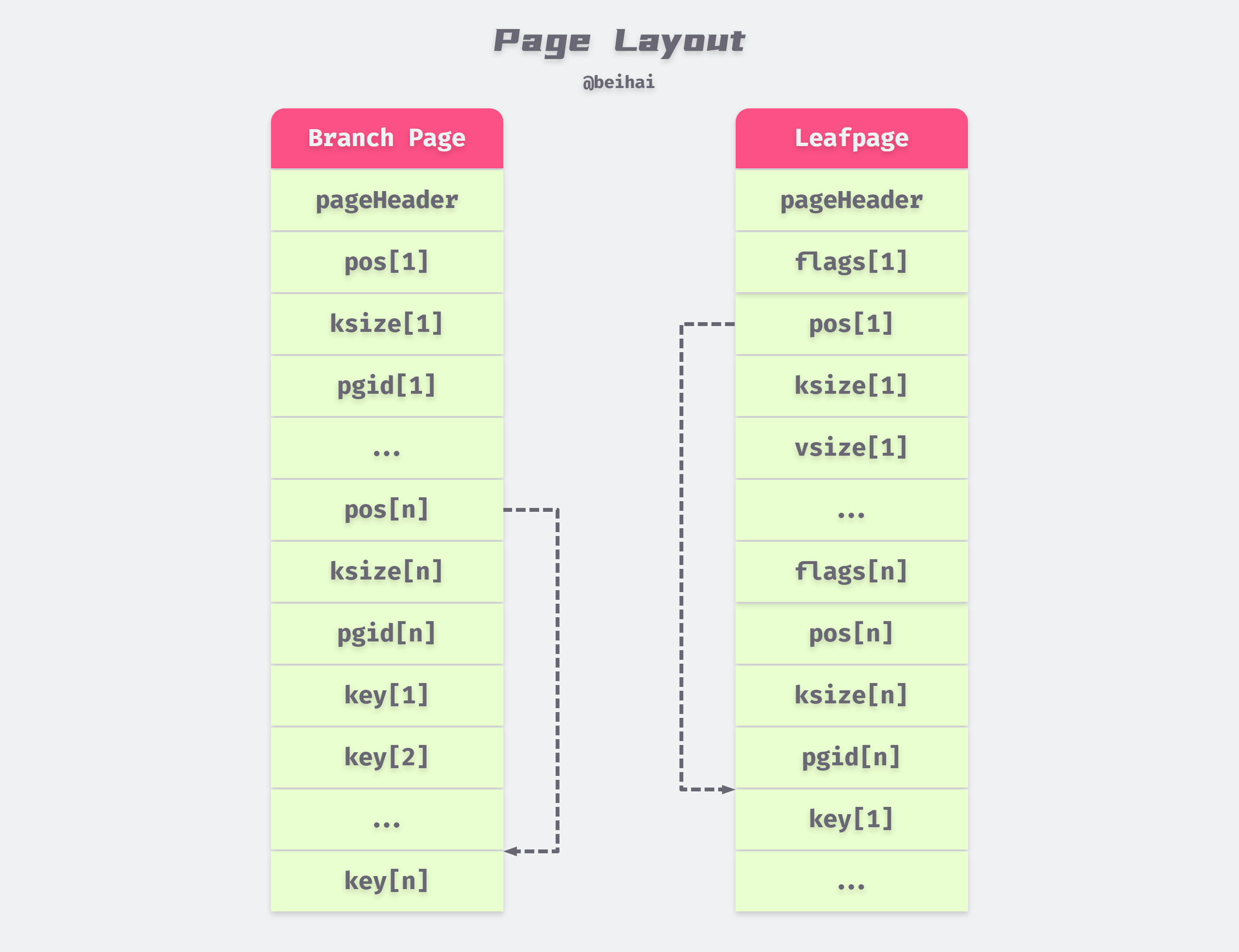
Storing Element and key-value pairs separately reduces the lookup time because the size of the Element structure is fixed and we can get all Elements in O(1) time complexity, whereas if they were stored in [Element header][key value][...] format, we need to iterate through them in order to find them.
Node
page is the layout format of the data in the disk file, which is deserialized to node when the Page is loaded into memory for data modification operations. A node is represented as a B+Tree node, so additional unbalanced and spilled fields are needed to indicate whether the node needs to be rotated and split. The node also stores a pointer to the parent and child nodes, which can be used for range queries on the key.
|
|
The key-value pairs in page are stored in node.inodes and correspond one-to-one, so that a key-value pair can be accessed by the index of the slice.
Serialization
To facilitate data modification operations in BoltDB, the corresponding page needs to be instantiated as node and then serialized back to page for writing to disk after the modification is done. The conversion of node and page is realized by the methods node.read(p *page) and node.write(p *page). Take the deserialization process of page as an example, the conversion process is as follows.
|
|
When filling inodes with key-value pairs. If it is leafPage, inode.flags is the flags of the element, key and value are the corresponding Key and Value of the element respectively; if it is branchPage, inode.pgid is the page number of the child node, and inode corresponds to Element in the page one by one.
Bucket
Buckets are higher-level data structures, and each Bucket is a complete B+Tree that organizes multiple node pages.
Data structure
Bucket is defined by the Bucket structure, which contains a Header field defined by bucket containing the page id of the root node and uniquely identifying the self-incrementing id. buckets are independent of each other and are conceptually equivalent to namespaces.
|
|
The nodes in the Bucket may be either instantiated nodes or serialized stored pages. When you need to find the key-value pair of a page from the Bucket, you will first check if the corresponding node exists from the Bucket.nodes cache (only pages that have been modified with data are cached as node), if not, then you will look for it from page.
The Bucket.FillPercent field records the fill percentage of the node. When the used space in a node exceeds a certain percentage of the entire node capacity, the node must be split to reduce the probability of triggering a rebalance operation when inserting key-value pairs in the B+ Tree. The default value is 50%, and increasing this value is only helpful if the large number of multi-write operations is added at the end.
Data Querying
To facilitate data queries, a Bucket may hold multiple iterators, defined by Cursor, containing the Bucket the iterator is traversing and the stack on which the search path is stored.
|
|
stack is a slice, each elemRef points to a node of the B+ Tree, which may be an instantiated node or an uninstantiated page, elemRef stores a pointer to the corresponding structure, another pointer is empty, and records the location of the key-value pair.
When querying, the Cursor starts with a recursive lookup from the page corresponding to Bucket.root to the final leaf node. The path to the corresponding key is stored in Cursor.stack, and the node and location of the key are stored at the top of the stack. In addition to regular key-value lookup operations, Cursor also supports the First, Last, Next, and Prev methods of the lookup Bucket for optimization of related scenarios.
Bucket nesting
Buckets in BoltDB can form nested relationships, which are divided into subBucket and inlineBucket depending on the nesting form. In use, we usually create a new Bucket and set a name in the following way.
A subBucket itself is also a complete B+Tree, with its name as key and a bucket structure as value, indexed to the page where the root node of the subBucket is located.
BoltDB holds a rootBucket that stores the root nodes of all B+ Trees in the database, and every Bucket we create is a subBucket of the rootBucket.
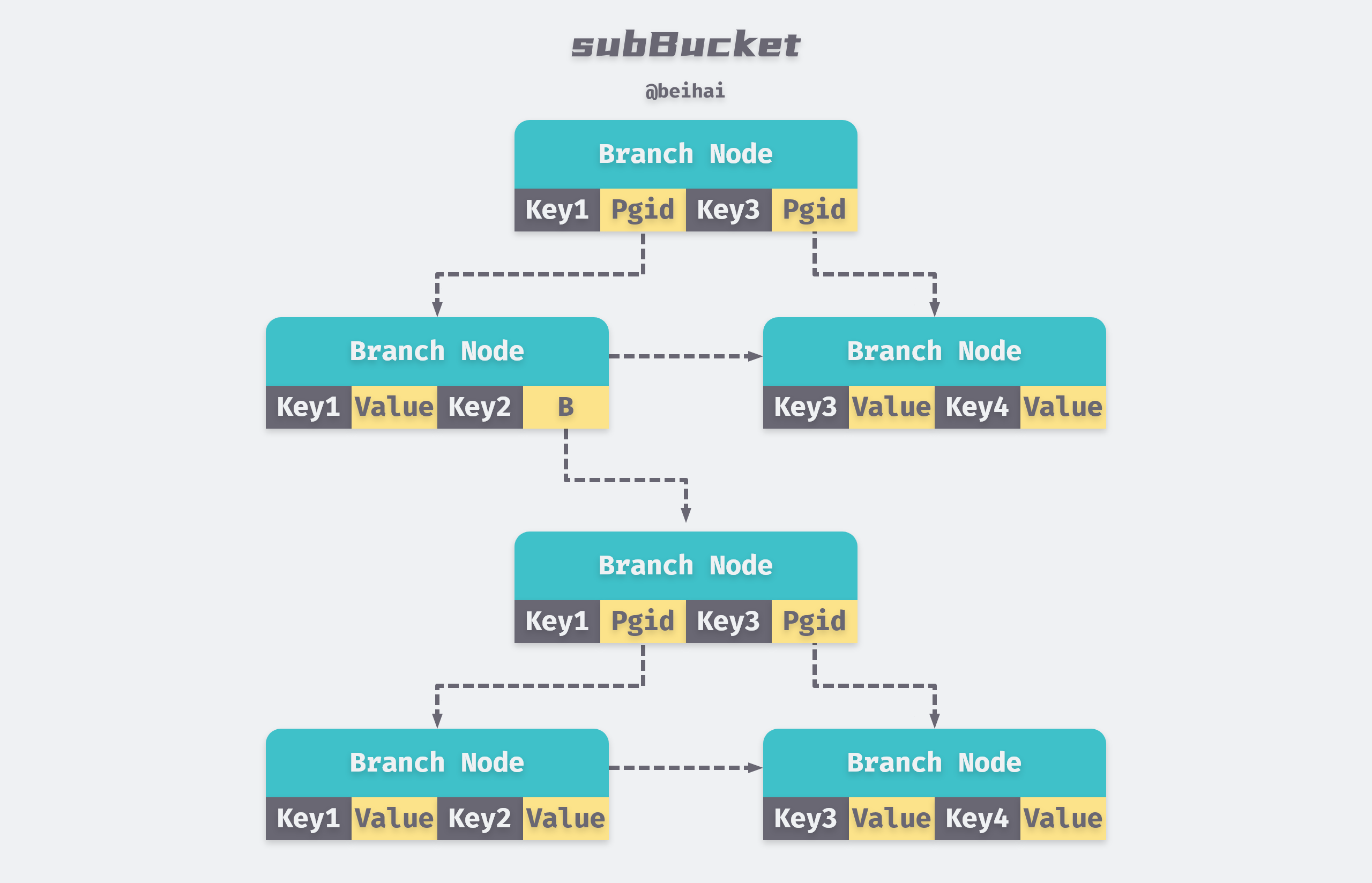
As you can see from the above figure, only the bucket field of subBucket is stored in the parent bucket, each subBucket takes up extra page to store data, usually the nested sub-buckets do not have a lot of data, which causes a waste of space. to solve this problem by storing the values of smaller child buckets directly in the leaf nodes of the parent bucket, thus reducing the number of pages used.
inlineBucket is an optimization of subBucket, as we can deduce from the following code, it is essentially appending a complete page structure to the value of subBucket and writing it to a file as a byte array.
|
|
In order to ensure the stable operation of the program, BoltDB has made some restrictions on inlineBucket.
- the size of
inlineBucketcannot exceed 1/4 of pageSize. inlineBucketcan contain only one leaf node.- the
bucket.rootfield ofinlineBuckethas a value of 0 to indicate the structure type.
Transactions
BoltDB supports ACID transactions and uses a read/write locking mechanism to support multiple read operations and one write operation to execute concurrently, allowing applications to handle complex operations more easily. Each transaction has a txid, where db.meta.txid holds the largest committed write transaction id.
BoltDB enforces different id assignment policies for write and read transactions.
- Read transactions:
txid == db.meta.txid. - Write transactions:
txid == db.meta.txid + 1. - When the write transaction is successfully committed,
db.meta.txidis updated to the current write transaction id.
MVCC
BoltDB implements multi-version concurrency control through the meta copy mechanism. The meta page is the entry point for transactions to read data, which records the version information of the data and the starting point of the query. The definition of meta is as follows, with a selection of important fields.
|
|
When the database is initialized, the two pages with page numbers 0 and 1 are set as meta pages. Each transaction gets a txid and selects the meta page with txid % 2 as the read object of the transaction, and the meta page is updated alternately after each write. When one of them is inconsistent, the other meta page is used.
BoltDB write operations are performed in memory, if the transaction is not committed when the error occurs, it will not affect the database; if the error occurs in the process of commit, the order of BoltDB write file also ensures that it will not affect: because the data will be written in the new page without overwriting the original data, and the information in meta will not change at this time.
- start a write transaction with a copy of the
metadata. - starting from
rootBucket, traverse the B+ Tree to find the location of the data and modify it. - when the modification operation is complete, a transaction commit is performed, which writes the data to a new page.
- finally update the information of
meta.
Freelist
BoltDB works by allocating 4KB pages and organizing them into a B+ Tree, and allocating more pages at the end as needed. BoltDB uses copy-on-write technology when writing to a file. When a page is updated, its contents are copied to a new page and the old page is freed.
When after repeated additions and deletions, there will be parts of the file without data. The page that is emptied of data may be located anywhere, BoltDB does not intend to move data, truncate the file to return this part of space, but to add this part of the empty page, to the internal freelist to maintain, and reuse this space when new data is written.
So the persistence file of
BoltDBwill only grow, not decrease as data is deleted.
freelist is a complex structure that contains a number of function definitions. For ease of understanding, a few important fields are listed below.
|
|
freelist has two types, FreelistArrayType and FreelistMapType, the default is FreelistArrayType format, the following content is also based on the array type for analysis. When the cache record is in array format, the freelist.ids field records the pgid of the current empty page, and when the program needs the page, it will call the corresponding freelist.arrayAllocate(txid txid, n int) pgid method to iterate through the ids and select n consecutive empty pages for the caller to use.
When a write transaction produces a useless page, freelist.free(txid txid, p *page) is called to put the specified page into the freelist.pending pool and set the page to true in freelist.cache, noting that the data is not cleared at this point. When the next write transaction is opened, the freelist.release(txid txid) method is called to move the page from the pending pool that is not used by any transaction to the ids pool.
BoltDB is designed to achieve multi-version concurrency control, speed up the rollback of transactions, and avoid interference with read transactions.
- when the write transaction updates data, it does not directly overwrite the page where the old data is located, and allocates a new page to write the updated data, and then puts the page occupied by the old data into the
freelist.pendingpool and creates a new index. When the transaction needs to be rolled back, just delete the page in thependingpool and roll back the index to the original page. - When a read transaction is initiated, a separate copy of the
metainformation is made, and the data pointed to by themetacan be read from this uniquemetaas the entry point. At this time, even if a write transaction modifies the data of the related key, the modified data will only be written to the new page, and the old page referenced by the read transaction will enter thependingpool, and the data related to the read transaction will not be modified. The data associated with the read transaction will not be modified until all the read transactions associated with the page are finished.
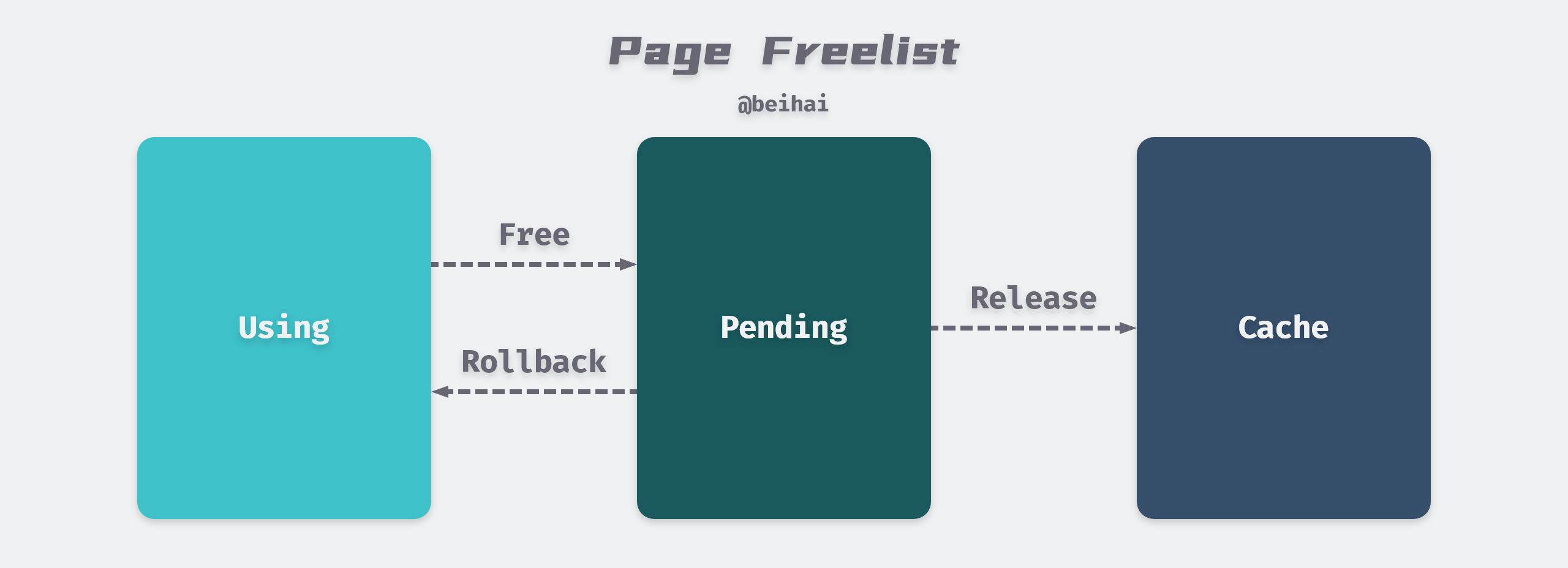
freelist implements MVCC with space reuse, only when the remaining space does not meet the write requirements will the file map grow, when the data file is less than 1GB, each remapping size doubles, when the file is larger than 1GB, each growth of 1GB to make full use of space.
Summary
BoltDB is a streamlined database implementation model, using mmap to map the page on disk to the page in memory, realizing zero copy of data, using B+ Tree for indexing, which is helpful to understand the concepts related to database system. It provides a way of thinking about the problem. The operating system uses COW (Copy-On-Write) technology for Page management, and through copy-on-write technology, the system can achieve lock-free read-write concurrency, but cannot achieve lock-free write-write concurrency, which predestines this kind of database to have high read performance, but poor random write performance, so it is suitable for the scenario of ‘read more write less’.
The use of write-time replication technology also creates certain disadvantages, if the long execution of read-only transactions, it will lead to dirty pages can not be recycled; if the long execution of the read-write transactions, it will cause other read-write transactions to hang and wait. In the process of using BoltDB, you should be careful to avoid long-running transactions as much as possible.
The text does not describe the B+Tree data structure in detail, you can read the article yourself : Concepts of B+ Tree and Extensions - B+ and B Tree index files in DBMS
Reference
- https://wingsxdu.com/posts/database/boltdb/
- http://man7.org/linux/man-pages/man2/mmap.2.html
- http://man7.org/linux/man-pages/man2/fdatasync.2.html
- https://blog.csdn.net/letterwuyu/article/details/80927226
- http://blog.decaywood.me/2017/04/10/Linux-mmap/
- https://github.com/boltdb/bolt/issues/308
- https://youjiali1995.github.io/storage/boltdb/#%E5%AE%9E%E7%8E%B0